
In a previous article we measured that a large percentage of 6to4 connections fail. In this article we show our attempts to find out why these connections fail.
Introduction
We pointed out in the article 6to4 - How Bad is it Really? that roughly 15% 6to4 connections we measured fail. More specifically we saw a TCP-SYN, but not the rest of a TCP connection. A similar failure rate was independently observed by Geoff Huston . There are 2 reasons why 6to4 is interesting to look at:
1) A minority of operating systems default to preferring 6to4 (and other auto-tunneled IPv6) over native IPv4 when an end-host connects to a dual-stacked host [1]. When the 6to4-connection fails it has to time-out before hosts try the IPv4 connection. This results in a poor user experience, which is the reason some large content providers are hesitant to dual-stack their content.
2) In a near future with IPv6-only content, 6to4 might be the only connectivity option for IPv4-only end-hosts that were 'left behind' and don't have native IPv6 connectivity yet. The end-host would have to have a public IPv4 address or be behind a 6to4-capable device (typically a CPE) for this to work. People looking for ways to make IPv4 hosts talk to IPv6 hosts should know about pros and cons of specific technologies that try to enable that.
In this article we take a closer look at why 6to4 connections fail, specifically the interplay between 6to4 and firewalls.
Firewalls rule/Firewall rules
A 6to4 connection starts off as an IPv6 packet encapsulated in IPv4, i.e. the protocol field in the IPv4 packet is set to 41. The encapsulated IPv6 packet will be decapsulated by a 6to4 relay. Return IPv6 traffic will go to a, potentially different, 6to4 relay which will encapsulate it into an IPv4 packet, destined for the original sender (see Wikipedia , RFC 3056 and RFC 3068 for more info on 6to4).
Previously we speculated that 6to4 breakage was caused by blocking IPv4 packets with proto 41 close to the connection initiator. So we set out to identify networks with very high rates of failing connections to see if it was indeed caused by filtering. I contacted a small number of networks, and from the responses an interesting pattern emerged. In these cases a firewall rule set like this caused the 6to4 connections to fail:
allow outbound (tcp|udp|icmp) keep-state allow inbound established-connection defaults: deny inbound allow outbound
Can you spot the explicit 6to4 blocking? Quite likely you can't because 6to4 is not blocked explicitly, but implicitly allowed out (default: allow outbound). But it doesn't match any rules for inbound traffic. Because no state is kept on outbound 6to4 (this is done only for TCP, UDP and ICMP in this case), and all other packets are denied (default: deny inbound), 6to4-return packets are dropped on the floor. The fact that 6to4 is enabled by default, combined by the 'drop everything we don't know'-security paradigm is a recipe for trouble here.
If you take the firewall rules above, and change the default outbound policy to 'deny', 6to4 will also not work. In this case not even the TCP-SYN makes it past the firewall, so these failed connections don't show up in our measurements. Let's assume the deny-outbound policy is as prevalent as the allow-outbound policy. In that case there would be 15% of 6to4 connections that we don't see but that all would fail. This speculation would bring the real 6to4 connection failure rate to 26%! Of course this is highly speculative, but as security people rather block all traffic that they don't want to specifically allow, it is not an unrealistic assumption that the deny-outbound policy is widely in use.
To Anycast, or to Unicast?
It seems possible to do "stateful" filtering on 6to4 traffic: One can keep state based solely on fields in the IPv4 packet, specifically the source IP, destination IP, and protocol fields, with 2 of these fields having a fixed value (destination IP = 192.88.99.1 and proto = 41). A problem with this layer-3-only filtering is that the source address of the return packets from a 6to4 connection is not well defined. The 6to4 relay that receives IPv6 packets and encapsulates these in IPv4 packets can be configured to use the anycast 192.88.99.1 address, or can use one of it's own IPv4 unicast addresses for the return traffic. In the latter (unicast) case, stateful layer-3-only filtering will break, so the amount of extra breakage caused by switching a 6to4 relay from anycast to unicast is an indication of how much of this layer-3-only stateful filtering is going on.
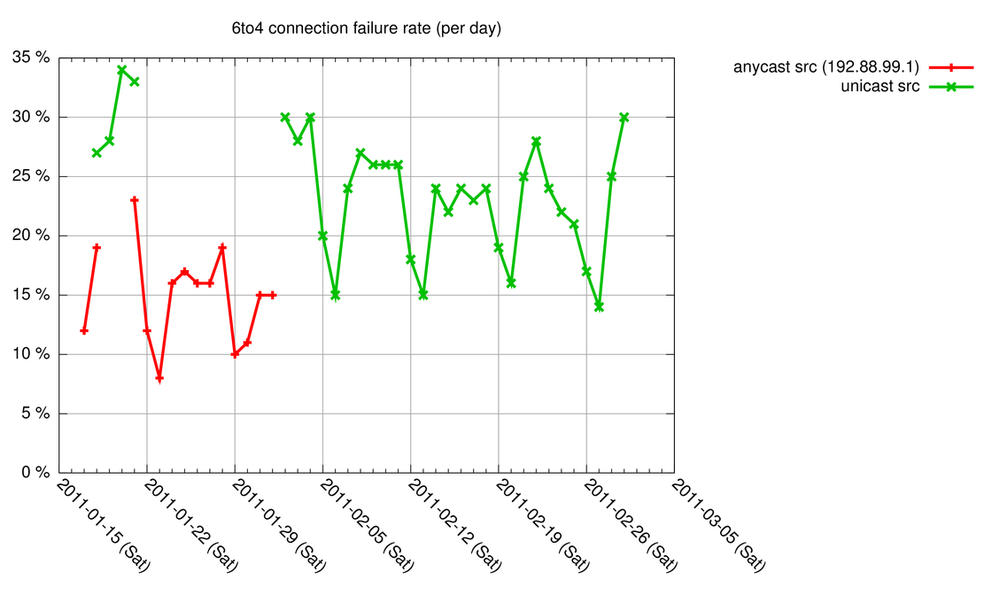
We measured this with the measurement setup as described in the earlier 6to4 - How Bad is it Really? article , but we changed the setup such that we had a 6to4 relay local to our measurement host. We switched the 6to4 relay between using anycast and unicast addresses for the 6to4 return traffic. The result is shown in Figure 1.

Figure 1: 6to4 connection failure rate (anycast and unicast)
As you can see, we measured that roughly an extra 5-10% of 6to4 connections break when using a unicast address for the 6to4 return traffic. The anycast configuration had a similar connection failure rate as our previous experiment with a remote 6to4 relay. In both local unicast, and local anycast configurations the connection failure rate is significantly lower in the weekends, which we also saw when using a remote 6to4 relay. The difference between the anycast and unicast configuration seems to indicate that layer-3-only stateful filtering is in common use, at least for the population of end-hosts we measured. Based on this it would be recommended for 6to4 relays to use the IPv4 anycast address 192.88.99.1 for return traffic.
Spoofed TCP-resets to the rescue?
As a firewall operator, how would one make 6to4 connection attempts fail fast? This is important for a quick fail-over from broken 6to4 to other potential forms of connectivity. As already mentioned in the ARIN IPv6 wiki , ICMPv4 and ICMPv6 unreachable messages back to the client don't necessarily make connection attempts fail fast. As an experiment I created a daemon that sends spoofed TCP-resets to TCP connection attempts in 6to4 (script available here , but beware: hacky prototype code). This far these TCP-resets seem to be the fastest way that I can make TCP connections over 6to4 fail. The prototype code could work as a stand-alone daemon somewhere near the inside interface of a firewall and would currently kill all TCP-over-6to4 traffic it detects. Other methods I tried to make 6to4 TCP connections fail fast, like ICMPv6 unreachables (6to4-embedded) and ICMPv4 unreachables, result in significant timeouts, see table 1:
| Windows 7 | Mac OS X 10.5.8 | |
|---|---|---|
| spoofed TCP reset in 6to4 | < 1s | < 1s |
| ICMPv6 unreachable | 22s | 4s |
| ICMPv4 unreachable | 22s | 75s |
| no response / drop packets | 22s | 75s |
Table 1: Connection timeouts under various conditions for Windows 7 and Mac OS 10.5.8.
The values for ICMPv6 and ICMPv4 unreachables match those in the ARIN IPv6 wiki. If somebody has a cleaner way to make 6to4 connection attempts to fail fast, I'd be happy to hear (please comment below). The spoofed TCP-resets are essentially an ugly hack, for an even uglier situation.
Conclusion
We hope this article sheds some more light on the unfortunate interactions between 6to4 and firewalls, and the pains one has to go through to make 6to4 connections fail fast if one wanted to. Some conclusions one can draw from this are:
- Don't enable 6to4 by default. For hosts that have 6to4 enabled by default (Windows Vista and later for example), consider disabling it.
- Firewall admins: beware of 6to4. Consider the consequences of dropping IPv4 packets with proto 41 now and in the near future.
Note there is work underway in the IETF on 6to4 deployment .
There is also another option to deal with 6to4-woes, or rather to avoid it being used at all: Get native IPv6, so hosts in your network won't have to deal with potentially broken transition technologies.
Footnote
[1] The main culprit here is Mac OS X versions before 10.6.5, see Tore Anderson's graph on Mac OS X versions seen in HTTP requests. Applications that do their own DNS resolving and selection of which IP protocol to use (like the Opera web browser before version 10.50 ) are another potential source of problems.

Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Anonymous •
You forgot to check about the IPv6 PTB (Packets to Big) messages that gets destroyed in transit.<br /><br />6to4 is usually on top of a PPPOE connection ending with weird MTU. The PTB message does not pass therefore some small packets are transmitted while big packets never reach their targets.<br /><br />Some more work to do to understand 6to4 in the wild...
Anonymous •
You are right, no consideration for IPv6 PTB in this article. All TCP packets in this experiment are too small to trigger pMTU problems. The situation is already not particularly rosy without considering PTB ...<br />
Anonymous •
It's an interesting extra variable though: Configuring different MTU:s on the server and trying to measure difference in client success connection rate. One could start with the extremes: 1500 vs 1280.<br /><br />Thanks for doing this measurement Emile!