
The Time Warner Cable network suffered an outage on 27 August 2014 between approximately 9:40 and 10:55 UTC. We looked at some interesting details of this outage using RIS and RIPE Atlas.
As reported in the press yesterday , Time Warner Cable (TWC) suffered a network outage lasting a little more than an hour.
If we look at the Time Warner Cable (TWC) network, it actually consists of several Autonomous Systems (ASNs). The main ASN is AS7843 ( TWCABLE-BACKBONE ), but we count at least seven TWC ASNs ( AS7843 , AS10796 , AS11351 , AS11426 , AS11427 , AS12271 , AS20001 ) [1].
Routing Information Service Measurements
From the data we collect in the Routing Information Service (RIS) , which provides a view of the Internet control plane BGP from over 400 points (peers) worldwide, we see that most of these seven ASNs were severely affected. Table 1 below shows the number of prefixes we detected as still being up at 9:40 UTC on 27 August, which was the snapshot where we saw the biggest impact. In this context, we consider a prefix being down if we see it from less than ten vantage points (peers). We also show what percentage of prefixes that represents, relative to the maximum number of prefixes seen in the last month.
| IPv4 Prefix | IPv6 Prefix | |
| AS7843 | 7 (2%) | 7 (100%) |
| AS10796 | 0 (0%) | 2 (100%) |
| AS11351 | 0 (0%) | 2 (100%) |
| AS11426 | 1 (0.3%) | 1 (100%) |
| AS11427 | 209 (99%) | 2 (100%) |
| AS12271 | 0 (0%) | 1 (100%) |
| AS20001 | 0 (0%) | 3 (100%) |
Table 1: Number of prefixes we see as being up at 9:40 UTC on 27 August
When looking at this in more detail, we see that AS11427 also had major connectivity issues, but the paths through AS7843-AS3356 (TWC-BACKBONE / Level3) stayed up. See for example this AS11427 prefix on BGPlay . This example also shows the bounds of the outage, as far as BGP is concerned: roughly 9:30 to 11:00 UTC.
Interestingly, we see that IPv6 prefixes announced by the TWC ASNs were not affected at the BGP level. As an IPv6 aficionado, I initially thought that was a silver lining to all of this, but further testing with RIPE Atlas (see below) indicates that the IPv6 data plane was also affected by the outage.
We also see that AS19151 ( BroadbandONE ) kept seeing TWC ASNs in BGP throughout this outage through the TWC backbone ASN AS7843. If data plane connectivity was also unaffected, this means that TWC customers were able to still visit websites hosted in AS19151 even during the outage (for instance Games Press , which is the highest Alexa ranked website in AS19151).
In summary: From BGP data, we see that a large part of the TWC network went down, but we also find pieces of connectivity that remained.
In BGP we also see another effect. We are still actively monitoring for 512k-routes related problems , and the TWC outage is also visible when you look at the number of ASNs that were down. On 27 August at 9:40 UTC, we saw 136 ASNs being down, out of which at least 64 are networks downstream of TWC. Looking at how these ASNs connect to the Internet, the top four upstream networks are all TWC networks, as shown in Table 2.
| Count | ASN |
| 34 | 10796 |
| 15 | 20001 |
| 9 | 11351 |
| 6 | 12271 |
Table 2: Top upstream networks of networks that were down at 9:40 UTC

Figure 1: ASNs that were down over time. Clear peaks are visible on 12 August (the 512k-routes related problems), and on 27 August (the TWC network outage)
It looks like these networks were either single-homed behind a TWC network, or any fail-over mechanism they had in place didn't kick in at that point.
While the monitoring for 512k-routes related problems showed this outage, it doesn't mean the TWC network outage was 512k-routes related. On August 12, 512k-routes problems started with thousands of newly announced prefixes that were widely visible in BGP. In the case of the TWC outage, we did not see a similar spike in new prefixes, indicating this is likely not related. We also don't expect a network as large as TWC to run equipment that's susceptible to this problem in their core.
RIPE Atlas Measurements
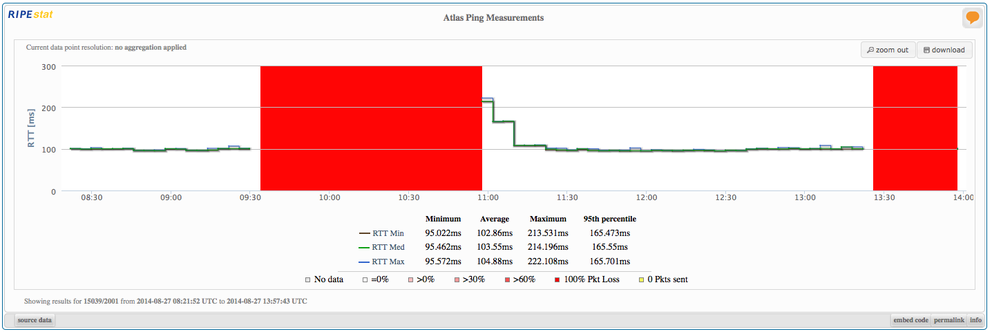
RIPE Atlas allows us to see control plane effects of this outage. Preliminary analysis of RIPE Atlas data shows that both the IPv4 and IPv6 data planes were equally affected, which is interesting because the IPv6 control plane (BGP) seemed unaffected. Figure 2 shows an example of ping measurements from a RIPE Atlas probe in a TWC network to a server in Germany (you can enlarge the images by clicking on them). Most other ping measurements from the TWC network probes towards destinations on the Internet have a similar outage pattern.

Interestingly, some of the DNS root server ping measurements that are built into the RIPE Atlas probes do not show interrupted connectivity to the K-root and J-root servers, while the other root servers measured showed an outage. Considering the geographic scope of the TWC networks and the root server deployments, this leads to the suspicion that in IPv4, the TWC data plane in/towards other networks in Miami, FL ( NAP of the Americas ?) was intact throughout the outage. The I-root and L-root servers that are also located in Miami, FL were not reachable during the outage. Also, all IPv6 measurements to root servers that we looked at for the outage period failed. Figures 3 and 4 below show examples of ping measurements to K-root, over IPv4 and IPv6.


Conclusion
We saw a large outage on 27 August from roughly 9:30 to 11:00 UTC, but we also saw pockets of connectivity remaining throughout the outage.
IPv6 prefixes were not affected in BGP, but on the data plane we didn't find evidence of IPv6 connectivity during the outage.
This event was likely unrelated to 512k , although the definitive source of information for that would be the TWC engineers who were unfortunate enough to have to go through this outage.
Concluding observation: Even the largest networks can have full or partial outages. If resilience to outages is important for you, having a plan for backup connectivity is important.
Further reading:
- Time Warners statement about the outage states " an erroneous configuration was propagated throughout our national backbone, resulting in a network outage. ".
- CAIDA's analysis of this outage.
Footnote:
[1] List of ASNs taken from here . Another list is available here .
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.