
In this report we provide some more details about the incidents of 30 November and 1 December 2015, as seen from the K-root environment. We also share some of the lessons we took away from this event.
Traffic flood
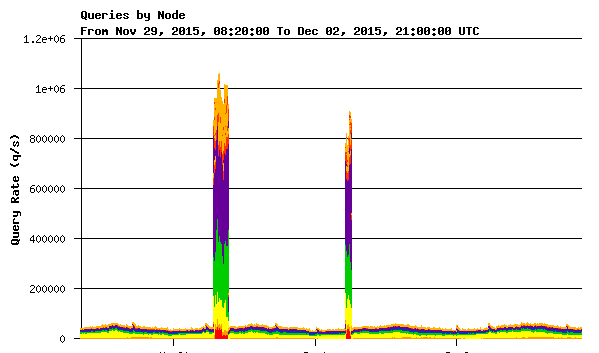
On 30 November 2015, at around 07:00 UTC, K-root servers began receiving a massive flood of queries. This is illustrated in the diagram on the right (colours indicate K-root nodes or groups of nodes).

We noticed the following:
- Our monitoring tools were reporting uplink bandwidth overflows at many of our K-root sites
- Some K-root core sites were no longer reachable
- DNSMON confirmed that K-root was showing high rates of packet loss from most of the DNSMON vantage points. We noticed that some other root servers were also showing problems in DNSMON
- Our internal DNS traffic monitor (DSC) showed very high incoming packet rates on many of the K-root nodes, although the added load showed significant variation between locations
- Total received packet rates were close to 20x our normal baseline rates
Query flood characteristics
We observed that all the queries had the following characteristics:
- They were queries for the same single name
- They were requesting recursion
- They were coming from a large number of sources
Mitigation actions
Following our initial investigations of the packet characteristics, we employed different filter techniques. The filters were, after some tuning of parameters, effective in reducing the impact on our servers. After rollout of these filters, K-root DNS services recovered. The actual rollout of these filters took longer than necessary, due to the fact that not all required tools were available across all of our servers.
Similar event on 1 December 2015
On 1 December we observed what seemed to be a repetition of the event of 30 November. The traffic pattern was very similar, though using a different query name. During the second event, on 1 December, we were able to activate filters on our servers more quickly.
Lessons learned
The postmortem of this incident highlighted some important improvement points:
-
Planned hardware upgrades and replacements for some of our locations should be made a priority.
At the time of writing of this report, all previously planned replacements have been rolled out. - Our operational setup should be improved to allow us to enable specific features of the software or the server operating system faster, e.g. specific filtering capabilities. We have since addressed this by ensuring that relevant software features are available on our servers by default, as well as being easily enabled from our configuration tools.
-
Hardware and connectivity limitations
Depending on the specific details of the traffic, hardware or network capabilities like available bandwidth may become an obvious limitation of our service capacity. We are continuously reevaluating our infrastructure to maintain sufficient headroom to absorb significant attacks. Where necessary, we improve and expand further.
Availability of captured data
There have been requests to share captured traffic from the event to allow further third party analysis. We have uploaded packet captures taken during the incident to the DNS data archive at DNS-OARC where it is available to researchers who agree to respect DNS-OARC's ethical and privacy standards.
We plan to present some more details about the event and our mitigation actions at the upcoming DNS-OARC meeting .

Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.