
Traffic classification has become an increasingly challenging task in network management recently. This proposal introduces two new techniques to address two identified issues in the operation of traffic classification.
Introduction
Finding out what applications are running on a network, provides information for many other tasks in network management. Traffic classification is the task of identifying the source applications that cause traffic on a network. It is an important part in the construction of Diffserv networks and QoS networks. With the growing complexity and dynamics of Internet applications and the use of traffic classification evasion techniques, this task is becoming increasingly difficult. Traditional classification techniques, namely port based classification and deep packet inspection become less effective, especially given that TCP ports can be manually assigned, and packet payloads can be encrypted.
Machine learning based traffic classification technique has been proposed in recent years. Significant research has shown that there are statistical differences in the way that different Internet applications communicate, and these statistics can be learned and applied to classify traffic flows and distinguish them from each others. As this technique does not reply on port numbers nor reading the packet payload, it doesn't have any of the shortcomings that exist in other techniques.
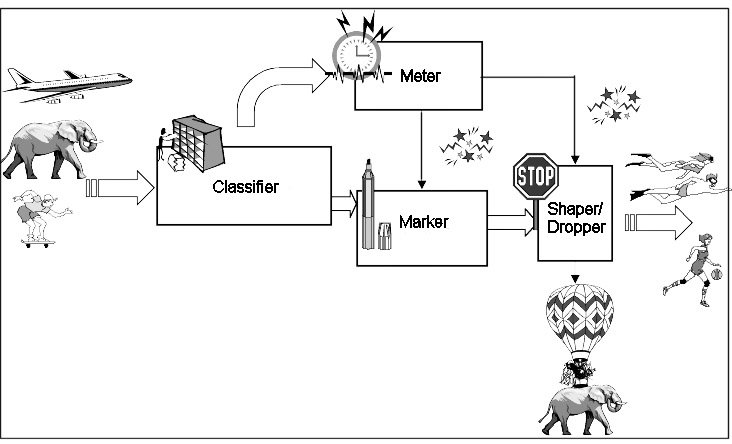
Figure 1 below illustrates a Diffserv architecture, originally proposed in
RFC 2475
. While this nice image is obtained from google images, I'd like to acknowledge the author who created this beautiful artwork.

Proposal 1: An effective updating traffic classification system
Machine Learning (ML) algorithms need updates over time when new Internet applications emerge or features of existing applications evolve. The two current methods used in practice come with two shortcomings:
- Training a new classifier only on new traffic leads to some learned knowledge being lost along with the abandoned data and classifiers and
- Training a classifier on a large dataset that combines all data collected in different periods leads to performance issues.
We propose to use the
ensemble classification technique
to address these issues [1]. This technique allows a classification system to get updated effectively in response to change. An ensemble classifier is a group of classifiers with their corresponding weights. To avoid ambiguity, we refer to the classifiers composing the ensemble as
base classifiers
. Each base classifier has a weight. Ensemble classification is made based on the weighted majority voting given by the base classifiers.
An ensemble classifier allows the system to be incrementally updated. Each update is performed on the most recent dataset only. As it is unnecessary to train a new classifier on a large dataset that combines data from previous phases, the updating time is saved, while old information encoded in old classifiers are utilised as part of the base classifiers. Moreover, the training process of the ensemble classifier can avoid a situation in which a phase with large data volume dominates the training process. In general, the most recent phase should be treated as the most important phase. However, the traditional method combines data from all previous phases to construct a single classifier. That means a phase with a large dataset can dominate the analysis of the combined dataset which can lead to the phase with the large data volume becoming the most influential phase in training a traffic classifier instead of the most recent one. In contrast, the ensemble method trains base classifiers individually on different phases and dynamically computes weights for different base classifiers, thus their influences can be controlled.

The image in Figure 2 above shows the structure of the ensemble traffic classification system. It consists of an online classification module and an offline training module . The online module consists of three components: flow identifier, feature generator and traffic classifier. Packets are grouped into flows by flow identifier using 5-tuple {transport protocol, source IP, destination IP, source port, destination port}. The offline module also consists of three components: a sample storage, measurement and ensemble training. The sample storage stores the traffic flows captured online. Every few hours (or days) the offline module measures the captured flows in order to detect if a change occurred. If that's the case, the offline module will update the existing ensemble classifier and then upload the updating configuration to the online modules. The updating configuration is a classifier and a set of weights.
Proposal 2: Classify traffic flows using arbitrary 5 packets
The common practice in ML based traffic classification is to use the first five packets in a flow for classification. The first five packets are not always available, and this approach provides low accuracy in cases where dropped IP packets are frequent or where traffic evasion techniques based on emulating traffic statistics for the first few packets in a flow are used.
As described earlier, traffic classifiers can be trained with using the first five packets or some subflows, with the aim to address the issues mentioned above. That poses a question: is it possible to train classifiers using packets arbitrarily selected from flows, meaning packets are neither the first five packets (e.g., packets of {1,2,3,4,5}) nor consecutive packets (e.g., packets of {4,5,6,7,8})? Instead they could be arbitrary sequences like {1,4,7,8,10} or {3,5,7,9,11}.

Figure 3: Selecting packets
We believe that this proposal could work, because if the statistics of a sequence of packets can be learned by using some ML algorithms, using an arbitrary subset of packets should also be learn-able. The proposal that the classifier would use arbitrary packets provides an auxiliary function to the existing traffic classification systems by addressing the problem of existing classifiers not being able to classify traffic due to packet loss or retransmissions in flows.
Constructing the features of traffic flows is an essential task in this work. The features used in our classifier are subject to the condition that the packets in flows are arbitrarily selected. For example, features related to inter-arrive time (IAT) are not used in this work, as the time interval would vary significantly depending on the selected packets. Our experimental results in [2] show that, although not every packet sets are equally effective on training accurate classifiers. By using some good packet sets (e.g., packet sets like {1,2,3,7,8}, {1,3,5,7,9}, {2,3,4,5,10}), the proposed traffic classifier provides a level of accuracy comparable to a classifier using the first five packets.
References
[1] R. Wang, L. Shi, B. Jennings, "Ensemble Classifier for Traffic in Presence of Changing Distributions," IEEE Symposium on Computers and Communications (IEEE ISCC), Split, Croatia, 2013.
[2] R. Wang, L. Shi, B. Jennings, "Training Traffic Classifiers with Arbitrary Packet Sets," IEEE Traffic Classification and Identification for Advanced Network Services and Scenarios (TRICANS ICC Workshop), Budapest, Hungary, 2013.
Runxin Wang was one of the fellows who attended the RIPE 66 meeting in Dublin, Ireland, under the RIPE Academic Cooperation Initiative (RACI).
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.