
This article presents a software-based prototype able to estimate the most queried domain names in a stream of DNS traffic at 12Mpps (wire-rate 10GbE). The goal is to identify domains involved in random qname attacks. This prototype is a proof-of-concept of our research on software and commodity-hardware approaches to analyse high-speed network streams.
It integrates statistical tools (Count-Min Sketch) and high-performance network packet processing frameworks (DPDK and libmoon), to analyse packets received by 10GbE NICs.
Linux, commodity-hardware and handling network packets
Since we are relying on software and commodity-hardware, we have to care about the performance of the operating system our tools run on. In Linux, the standard network packet processing framework, the New API (NAPI), has shown some limitations in handling high speed traffic, and different frameworks have been developed to overcome them. Examples of these frameworks include: PFQ [BPGP12], PF_RING, HPCAP [Mor15], DPDK, and more recently, eBPF and XDP.
We have built our proof-of-concept prototype on libmoon, a library developed by Paul Emmerich (Technische Universität München (TUM)) [Emm15] that provides a Lua interface to DPDK. So we can write Lua scripts that process the packets received by DPDK to produce statistics about the frequency of the elements in the DNS queries, for example, the top queried domains.
Identifying queries relating to DDoS
While there are different kinds of DDoS attacks relating to DNS, in this article we focus on random qnames, which aim to undermine the availability of DNS authoritative servers. For that, the offender floods the target server with non-existing random queries under domains found in the server’s authority. Since DNS resolvers do not find these queries in their caches, they recursively query the authoritative server. Processing these non-existing resources costs extra resources for the server.
It is common that random qname attacks rely on specific domain name suffixes. For example, the dafa888 attack from 4 September 2014 [Bal14] attempted to flood the French ccTLD .fr with random xxxxxx.www.dafa888.wf queries. You can see the effects in DNSMon. As described by Sandoche Balakrichenan from AFNIC [Bal14], to investigate the source of the problem and countermeasure it, operators had to tcpdump the traffic, find that there was an abnormal number of queries under the dafa888.wf domain and then block them.
In this kind of attack, the queries on the malicious domains are the most frequent elements in the network traffic. These are the heavy hitters that we aim to detect on-the-fly with our proof-of-concept prototype. We then need to process each DNS packet in the network traffic stream, keep statistics about the different queried domain names and estimate their frequency for a short period of time.
In this regard, one of the main challenges about identifying such heavy hitters is to count the occurrences of every different possible item (i.e. domain names) in network traffic, especially if we rely on limited memory. As there is an unlimited number of possible domain names of different lengths, it's not feasible to use key-value tables to keep statistics because it would require unbounded memory. So, instead of trying to count the exact number of occurrences for each item, for example the exact number of DNS requests for each (Top Level Domain TLD + Second Level Domain SLD) suffix, we use a CountMin Sketch (CMS) [CM05]. CMS is a statistical tool, such that makes it possible to obtain an accurate approximation of counts while requiring sublinear memory space.
Count-Min Sketch
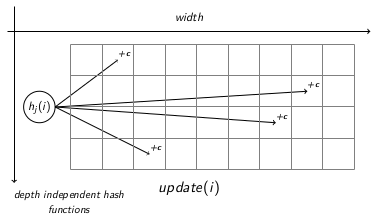
CMS is a statistical estimation tool developed by G. Cormode and S. Muthukrishnan, that guarantees an approximation of the number of occurrences ai of an item i in a data stream s, under controlled memory size and error probability. A CMS relies on a fixed-size array F of w x d counters. Each row j of counters is mapped to a hash function hj(i) of the family ((r1j*i + r2j) % p) % w, so hj(i): {1…n}→{1…w}, ∀j ∈ {1…d}. These hash functions are associated to the two basic actions provided by CMS: update(i) and query(i), that make it possible to increment the counts of an item and estimate its occurrences, respectively.
When a new item i arrives from the stream, CMS updates (update(i)) the table, incrementing the corresponding counter in each row at the index hj(i), as shown in Figure 1 below. Given the possible hash collisions, the counter in cell [j][hj(i)] could be increased by more than one item i. However, to minimize overcounting, query(i) returns the minimum value among the counters mapped to that item, i.e. minjF[j][hj(i)]. As hash functions hj are independent this minimizes the impact of collisions on the accuracy of count values estimates.
Also, to control the error probability of the estimator, CMS provides two parameters, precision ϵ and sensitivity δ, that actually dimension the sketch structure: w = [e/ϵ] and d = [ln(1/δ)]. Given ϵ and δ, CMS guarantees an estimation error lower than ϵ * |s|1 (where |s|1 is the L1 norm of the stream s = (i1, i2, …), that is the total count value), with a probability at least 1 − δ. Mathematically speaking: P||(âi − ai) < (ϵ * |s|1)|| > (1 − δ), where âi is the estimated number of occurrences of the item i.

Figure 1: Count-Min Sketch: update function
We use CMS to estimate how many times domain names with specific characteristics, for example domain names under the same suffix (SLD+TLD), has been queried during a time slot. It is important to note that CMS keeps track of all queries in the stream, without any assumption on the characteristics of malicious queries.
CMS example
Let us consider example values of the precision parameters to calculate the error factor, its probability, and the sketch size. Let us take as an example a CM Sketch with ϵ = 10−4 and δ = 10−3. It would have a size of d = ln(1/10−3)=7 rows; and w = e/10−4 = 27183 columns; that equals to 190,281 counters, and a memory size proportional to them. We would like to use it to count items from a DNS packet stream at full 10GbE wire-rate, which means around 12 million packets per second. According to the formulas above, there is a probability greater than 0.999 (1 − δ) to have a difference between the estimated and the actual number of occurrences lower than 10−4 * |s|1. After ten seconds, there would be 120 million packets, so the estimation error would be lower than 10−4 * 120M = 12,000. This is accurate enough to detect statistically significant changes in the number of queries relating to, for example, a given domain suffix or to estimate the top queried domains.
One of the drawbacks we have to take into account is that the CMS linear hash functions are developed to process numerical items i, while the DNS qnames are sequences of 8-bit characters. Therefore we first need to map each string domain name to a numeric value, before feeding it into the CMS update or query functions. For the moment, we are using the «djb2» hash function (proposed by Daniel J. Bernstein). We would like to note that this additional hash function increases the collisions probability between domain names, with a potential impact on the precision of the estimates.
Also, the related hash functions are not reversible, so we cannot transform a hashed value into the original item (e.g. the domain name). As we show in the proof-of-concept description below, for being able to report the most frequent domains in the stream, we modified the update(i) function to compare the current min count against a given threshold. This make it possible to include the updated domain into a fixed-size list of suspicious domains. The following section provides more details about the proof-of-concept we have implemented.
A proof-of-concept
Relying on CMS as the core of the estimation approach, we have built a Lua proof-of-concept (PoC) script, on top of DPDK and libmoon. We have chosen DPDK over the academy frameworks listed above, because it is well supported and has stable versions. This PoC is available at git repo.
The idea is simple: this script reads DNS queries from incoming traffic, and updates CM Sketch counters for each suffix (SLD+TLD) it sees in the stream. As explained above, each update(i) call increases some of the values stored in the cells of the CM Sketch, and moreover it evaluates if the minimum counter value for the domain exceeds a threshold. Since this could be a sign of abnormal behaviour, the corresponding domains are included in a temporary list of heavy hitters. In cycles of r seconds defined by the user, the script queries the CM Sketch to estimate the frequency of occurrences of the domains in that list.
To increase performance, the script is able to distribute the load among different threads, and at the end of each processing cycle, a specific function collects statistics from each counting task and unifies results. This is a simplified version of the algorithm at the core of the PoC:
Input:DPDK reception queueCM Sketch precision and sensitivity parameters ϵ, δ ∈ [0,1]refresh_time > 0threshold > 0Output: Estimated top domain names and the number of occurrencesSet rx_buffers ← Incoming data stream batch from DPDKCreate a timer of refresh_time secondsCreate a table per_thread_stats (stats per CPU, to be sent to a collector function)Create a table domains_to_estimate of size k (suspicious domains)loop
(This is the update part: read the packets during r seconds and increase countersfor each domain name)while timer > 0 dofor all dns_packet ∈ rx_buff ers dodname ← domain (SLD+TLD) from each query in dns_packet
(for the following function we are currently using
Daniel J. Bernstein's djb2 hash function)hashed_dname ← hash the domain name string into an integer
(this is the modified CMS.update(i) function that evaluates if the
minimum counter exceeds a threshold)if CMS.update_and_evaluate(hashed_dname, threshold) thenInclude dname in domains_to_estimateend ifend forend while(once the timer gets to zero, call the CMS.query() function to
estimate the occurrences of the suspicious domains)for all dn ∈ domain_to_estimate doInclude dn and CMS.query(dn) in per_thread_statsend forSend per_thread_stats to the collectorReset per_thread_stats (empty table)Reset CMS counters (counters to zero)Reset domains_to_estimate(empty table)Reset timer (to refresh_time seconds)end loop
To show the performance of the script, we tested it using attacker and analysis work-stations, directly connected through 10GbE links. The attacker machine runs our DNS query generator [RRVB16]. We configured that machine to produce 120 million queries uniformly distributed among four domains: example.com, evildomain.666, ilove.pizza and hola.co, with random prefixes of maximum four character length.
The PoC script runs on an Intel Xeon E5-2630@2.40GHz CPU machine, and we have configured it to distribute the load among eight CPU cores, using CM Sketches given by ϵ = 0.0001 and δ = 0.001. Here are the results after receiving the 120 million packets sent by the generator:
Total counts (requests per domain):
evildomain.666. : 29999156
example.com. : 29999116
ilove.pizza. : 29999161
hola.co. : 29999128
----
total: 119996561
total packets received by device: 120000000The script was able to process 119,996,561 of 120,000,000 packets: 99.99% of the packets received by the network interface. The README.md found in the project repository describes how to install and test the script.
Next steps
This is work-in-progress, and we would love to get more feedback from the community. We aim to consider different requirements and network analysis uses cases to design useful tools, built upon approaches similar to this proof-of-concept. We are now studying methods to increase the performance of processing the DNS payload, especially hashing the character strings. For future work, we also plan to address how to filter and classify packets, still relying on software and commodity-hardware.
Acknowledgments
We would like to thank CNRS’ PEPS SISC INS2I program and the Fondation Carnot that have funded this research. This is part of the work presented at the RIPE 74 DNS Working group session, thanks to the RIPE Academic Cooperation Initiative (RACI). The slides and video of the presentation are available here and here.
References
[Bal14] Sandoche Balakrichenan. Disturbance in the DNS - talk at DNS-OARC, 2014. Last accessed on: February 26th 2016.
[BPGP12] Nicola Bonelli, Andrea Di Pietro, Stefano Giordano, and Gregorio Procissi. On Multi-gigabit Packet Capturing with Multi-core Commodity Hardware. In Proc. PAM 2012, volume 7192, pages 64–73. Springer, 2012.
[CM05] Graham Cormode and S Muthukrishnan. An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms, 55(1):58–75, 2005.
[DPDK] “Data Plane Development Kit,” [Online]. Available: http://dpdk.org
[Emm15] P. Emmerich, S. Gallenmüller, D. Raumer, F. Wohlfart, and G. Carle, “MoonGen: A Scriptable High-Speed Packet Generator,” in Proc. IMC’15, Tokyo, Japan, Oct. 2015.
[Mor15] Victor Moreno. Harnessing low-level tuning in modern architectures for high-performance network monitoring in physical and virtual platforms. PhD thesis, Universidad Autónoma de Madrid, 2015.
[PFRING] PF_RING, “High-speed packet capture, filtering and analysis.” Last visited on: February 18th 2016. [Online]. Available: http://www.ntop.org/products/packet-capture/pf_ring
[RRVB16] S. Ruano Rincón, S. Vaton, and S. Bortzmeyer. Reproducing DNS 10Gbps flooding attacks with commodity-hardware. In IWCMC 2016: 12th International Wireless Communications & Mobile Computing Conference, pages 510–515, 2016.
[XDP] "eXpress Data Path," [Online]. Available: https://www.iovisor.org/technology/xdp
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.