
After we observed increased query load on the root name severs recently, we did some investigation and analysis which is described in the article below.
Earlier, we reported about an Increased Query Load on Root Name Servers . At no time was there any operational problem for K-root, the root name server the RIPE NCC is responsible for. In the meantime, traffic load is back to normal again and we would like to present some preliminary results:
We immediately noticed this increase and we kept a close watch on the developments. Because the increased load did not pose problems for K-root, we decided not to block the traffic. However, we took some measurements to spread the load across other instances of K-root. Also, the collaboration with our peers was excellent during the entire time.
Initially a few small drops could be observed in our DNS monitoring tool DNSMON . DNSMON is extremely sensitive and shows the slightest changes immediately. We took immediate action to limit the bandwidth impact of the increased load and the drops never appeared again.The engineering reason for these drops is an internal bandwidth limitation in our global nodes. This was known and upgrades were already scheduled. We have re-scheduled these upgrades to happen earlier where possible.
By working with our peers and their up-streams we established early on that the majority of the traffic was originated from a few Autonomous Systems (ASes) located mostly in China. We contacted the operators of these networks to find out what's going on. This was relatively complicated because of the geographic distance and because we don't have a lot of contact with the operators in question. We will be looking into streamlining communications with distant ISPs. However, this will always remain difficult because of language and time zone differences.
One of the ASes originating the traffic is very big compared to the others, so initially it looked like it only came from one single AS. Consequently, anycast did not spread the query load as effectively as usual: because the bulk of the queries came from one AS and because this AS was very large, most queries were targeted to one particular anycast instance of K-root. This is the first occurrence of this kind of traffic distribution, or lack thereof. We will work with the routing community and seek methods to make anycast more effective at a more granular level than just by AS. Ideas are welcome.
Detailed analysis
The increased load was caused by queries to a single .com domain, called <domain> in the text below. the www. <domain> .com hostname in this domain was by far the most popular. The webserver for www. <domain> .com was associated with a game site in China, which is not in the Alexa 1M list. A zone transfer of this zone from all 4 authoritative nameservers revealed a typical "one host small zone", and there are no indications this zone was using fast-flux or similar detection evasion techniques.
If we look at queries for *. <domain> .com. on 29 June, we find 99.996% of queries of type A (or 1 in decimal), and interestingly there are no queries of type AAAA. The very small fraction of other query-types is of both assigned and unassigned query-types, the top 3 are listed below. If we look at query class, 99.998% of queries is of class 'IN', the top 3 of other query-types is also listed below. Interestingly the value of the top query type and query class is 2561, for which we don't have an explanation (It is 2561 years ago that Confucius was born though). Queries for www. <domain> .com had the Recursion Desired (RD) flag set. Communication with the operators of .com revealed that they did not receive the same type of query-storm for www. <domain> .com. to their authoritative servers.
| query type | Count |
|---|---|
| TYPE2561 | 4437 |
| TYPE3841 | 2566 |
| TYPE1281 | 1198 |
| query class | Count |
|---|---|
| CLASS2561 | 2260 |
| CLASS513 | 980 |
| CLASS3585 | 20 |
Spot checking of a couple of IP addresses that queried for www. <domain> .com revealed that these IP addresses didn't query for anything else but <domain> .com, which suggests that there are no typical DNS resolvers behind these IP addresses. Speculating: this could be caused by either a misconfiguration in a piece of software, or something initiated by a botnet.
If we look at the ASes for sources querying the www. <domain> .com, we find sources from 287 distinct ASes, that map to 48 distinct countries. As already indicated earlier, the main source were ASes in China. If we look at the top 10 ASes, in terms of the number of /24s that traffic came from 8 where in China, the other 2 were in Taiwan and India (based on the delegation files from the RIRs). This indicates that this was not something exclusively originating from China, but there seems to be some correlation to countries with Chinese language populations. Speculating on what could cause this correlation, it could be due to either a bug in a piece of software that is tied to Chinese languages, or a botnet who's mode of infection is Chinese language specific, like language specific malware or spam.
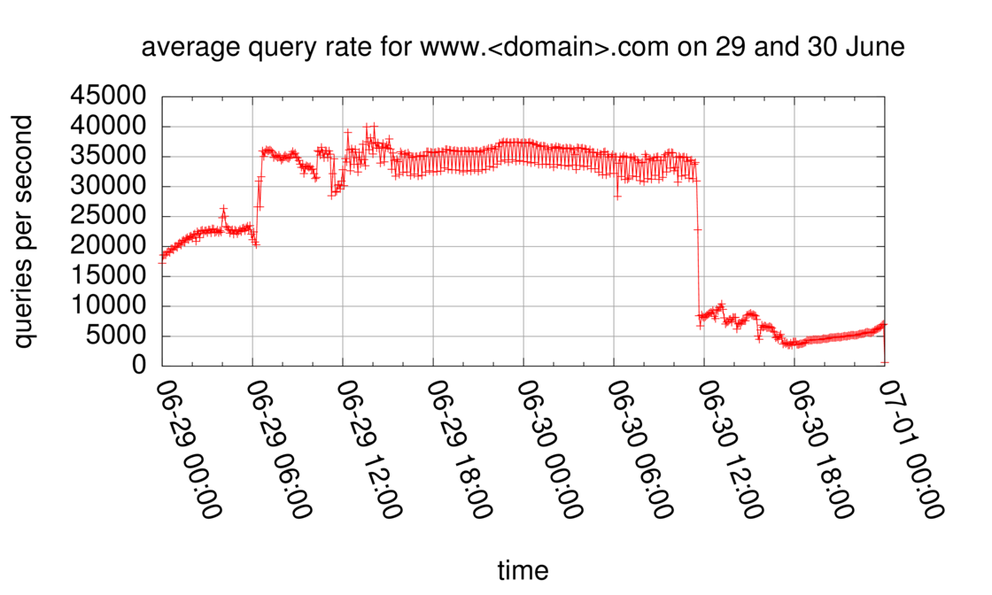
If we look at the total query rate for www. <domain> .com to K-root (see Figure 1), we see 2 distinct changes in query rate, one on 29 June around 6am UTC, and the other one on 30 June around noon UTC.

Figure 1: Query rate distribution for www.<domain>.com on 29 and 30 June
If we look at the query rate per source address, we see that this is quite low. Figure 2 shows boxplots of the distribution of queries per minute per source for 30 minutes intervals.

As you can see, the query rate per source address is at under 100 packets per minute typically. The same 2 distinct changes (on 29 June 6:00 UTC, and on 30 June 12:00 UTC) as in the overall query rate graph (Figure 1) are visible here.
In Figure 3, the number of unique IP address per 30 minute interval querying for www. <domain> .com is plotted for 29 and 30 June. As can be seen from this plot, about 60,000 to 65,000 distinct IP addresses were sending queries to K-root on 29 June and the first part of June 30. About midway through June 30 the number of distinct IP addresses dropped significantly, at the same time as the total query rate decreased (see Figure 1) and the median query-rate per IP address increased (see Figure 2).

Figure 3: Unique IP addresses querying for www.<domain>.com on 29 and 30 June
Conclusions
Even though we did not experience any disruption in service at any time, we decided to increase the over-provisioning of all global nodes of K-root in order to have even more headroom in the future. We will prepare methods to make anycast more effective at a more granular level than just by AS, in case such an incident repeats. We will work to improve communication with ISPs that are distant from our global nodes and our operations center.
As to the cause of this incident we are still in the dark. While it is plausible that this was caused by a botnet, this hardly can be classified as a DDoS attack to K-root, since the packet rates per individual source were too low to have significant impact. One speculation is that this was a test of the capabilities of a specific botnet.
If you have more information or have an idea about the cause of this incident, please let us know in a comment below.
Comments 6
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Anonymous •
Some additional analysis, which I put on the <a href="mailto:ncc-services@ripe.net">ncc-services@ripe.net</a> and <a href="mailto:dns-wg@ripe.net">dns-wg@ripe.net</a> mailingslists:<br /><br />This issue appears not to be related to a<br />misconfigured zone, the zone looked (and still looks) like this:<br /><br /><domain>.com. 7200 IN SOA ns1.<nsdomain>.<br />root.ns1.<domain>.com. 20091027 28800 600 604800 86400<br /><domain>.com. 300 IN A <ipv4_1><br /><domain>.com. 300 IN A <ipv4_2><br /><domain>.com. 7200 IN NS ns1.<nsdomain>.<br /><domain>.com. 7200 IN NS ns2.<nsdomain>.<br /><domain>.com. 7200 IN NS ns3.<nsdomain>.<br /><domain>.com. 7200 IN NS ns4.<nsdomain>.<br />www.<domain>.com. 300 IN A <ipv4_1><br />www.<domain>.com. 300 IN A <ipv4_2><br /><domain>.com. 7200 IN SOA ns1.<nsdomain>.<br />root.ns1.<domain>.com. 20091027 28800 600 604800 86400<br /><br />The <nsdomain> was a different domain, not in COM.<br />We asked folks that operate COM and they didn't see the same query-storm for this domain though. If these were all 'normal' resolvers dealing with a misconfigured zone, I'd expect them to follow the delegation chain. Also when spot-checking some 20 source IPs for these queries we didn't find these did any other queries to K-root then for things in <domain>.com.<br /><br />As mentioned in the article, we have several indications that this was caused by a botnet.<br /><br />It is unlikely this was a reflector attack with spoofed source addresses, as there are some 60,000 unique source IPs per hour in the queries for this specific domain. For targeted spoofing I'd would expect this number to be very low, for random spoofing I'd expect this number would be far higher.<br /><br />When looking at the query load for www.<domain>.com on 20110628, and before 16:28 UTC (0:28 Chinese Standard time) we have 2 queries for this domain, then it all starts:<br />#queries timestamp<br />1 1309252434<br />1 1309274472<br />8603 1309278521<br />9630 1309278522<br />11277 1309278523<br />14123 1309278524<br />12271 1309278525<br />12457 1309278526<br />12118 1309278527<br />12369 1309278528<br />12234 1309278529<br />12402 1309278530<br />12202 1309278531<br />12469 1309278532<br />12138 1309278533<br />12149 1309278534<br />... (continues to be in 10-12kps range for a while)<br /><br />So either the misconfiguration started at around 16:28 UTC, or this wasn't a misconfiguration. The third possibility, already misconfigurated+slashdotted-equivalent, I think is not impossible but unlikely,<br />both because of it being past midnight at the ASes that were a major source of queries, and the very sudden increase in load.
Mesh •
China is testing to see how hard it'd be to take out the root name servers?
chaz •
Unlikley, but were they trying to hide something else? Since a lot Chinese software is pirated looks like someone or country embedded some extra code in that software and wated to try out their new bot net to see what it could. With their limited IP's the attack was located to a one root location. I would have shut them down.
Exaybachay •
It sound like beginning of the end =)
Alan •
The owner of <domain>.com was a victim of a DDOS attack against their authoritative name servers. They attempted (and probably succeeded) at mitigating the attack by adding glue for the www record directly into the root.
Dan •
I could not even sign in to my router initially. The IP address was changed? I had to do a full system factory re-set and firmware update to regain control over the DNS. Once done, I changed passwords. A notice sent from Charter here in Michigan alerted me, or I would not have known. I will spread the word on Facebook if it will help awareness of this Botnet attack, but it looks like a very extreme test of servers and also effects users as far as accessibility of routers. Perhaps users may help identify these activities if they are aware. Most people I know would not even open an email as I did and check their IP address.