
For decades, the Domain Name System (DNS) has relied on UDP as its transport protocol of choice, mostly because of its simplicity. New transports such as DNS-over-TLS and DNS-over-HTTPS are now gaining popularity: they offer increased privacy while preventing the use of the DNS as a DDoS attack vector. What may be less obvious is that they can also provide increased performance compared to UDP.
For decades, the Domain Name System (DNS) has been based on a connectionless semantic: a client sends its query as a single User Datagram Protocol (UDP), and it receives a single UDP datagram with the response. This very simple communication model, along with efficient caching and clear administrative boundaries, is what allowed the DNS to scale and successfully adapt to an ever-increasing demand.
However, this approach has been starting to show its limits in recent years: from DNS-based DDoS attacks to broken IP fragmentation in the public Internet, the picture of DNS over UDP looks bleaker and bleaker. In addition, there is a recent push to encrypt all DNS communication through the specification and deployment of DNS-over-TLS and DNS-over-HTTPS, further phasing out the use of UDP.
In this post, we focus on performance, more specifically between a DNS client (a stub resolver in the DNS terminology) and a recursive resolver. We show that DNS-over-TLS — and more generally any scheme that allows persistent DNS connections — provides an opportunity to improve query latency compared to UDP.
This post starts by defining what we mean exactly by DNS performance, and then moves on to describe persistent DNS connections and their impact on DNS performance.
Foreword on DNS performance
From the perspective of the DNS end-user, the most relevant performance metric is latency: how long do I have to wait before getting the answer to my previous query?
Most of the time, no useful work can be carried out by the application before a DNS response is received — think of a browser loading a webpage, or an email server checking a DNS-based blocklist. Therefore, reducing the latency of DNS queries has a strong and direct impact on application responsiveness.
On the recursive resolver side, the focus is somewhat different. The main performance metric is ‘How many clients can I serve while providing an acceptable level of service?’, and the related question, ‘What hardware do I have to buy and at what cost?’.
The performance objectives of clients and recursive resolvers are sometimes contradictory. For example, a client could aggressively retransmit its queries several times (perhaps even to several recursive resolvers) to make sure it gets a timely response. However, this would impose an additional load on the recursive resolvers, hurting their own performance metric. Perhaps this could even cause other clients to experience higher latency as a result. Therefore, a delicate balance has to be found between the needs of the clients and the induced load on the DNS infrastructure.
Packet loss turns into massive latency spikes
Packet loss is one way a DNS query can go wrong, with a massive impact on latency. UDP has no built-in reliability mechanism such as acknowledgements and retransmission, so it is up to the application layer to detect and recover from losses. This is a big issue for DNS: a stub resolver has no way to distinguish a packet loss from a slow recursive resolver!
Let’s see in detail what happens when a stub resolver queries a recursive resolver:

Figure 1: DNS over UDP: Query 1 is successful, while Query 2 is lost and must be retransmitted
The ‘DNS resolution delay’ shown for Query 1 can be as large as several seconds: if the answer is not already in its cache, the recursive resolver has to query several authoritative servers through an iterative process to determine the answer. Meanwhile, because of the lack of acknowledgement, the stub resolver does not even know whether the recursive resolver has received the query!
How long should the stub resolver wait for an answer before triggering a timeout event and retransmitting its query? The value of this retransmission timeout should be higher than the maximum expected resolution delay, as shown for Query 2 in Figure 1, to avoid spurious retransmissions.
The following table lists the retransmission timeout used in practice by typical stub resolvers:
| Stub resolver | First retransmission timeout | Retransmission strategy | Time before application failure |
|---|---|---|---|
| Glibc 2.24 (Linux) | 5 seconds | Constant interval | 40 seconds |
| Bionic (android 7.1.2) | 5 seconds | Constant interval | 30 seconds |
| Windows 10 | 1 second | Exponential backoff | 12 seconds |
| OS X 10.13.6 | 1 second | Exponential backoff | 30 seconds |
| IOS 11.4 | 1 second | Exponential backoff | 30 seconds |
Table 1: Retransmission behaviour of the most widely used stub resolvers when configured with two recursive resolvers. The ‘Time before application failure’ is the time it takes for the stub resolver to give up retransmission and signal a failure to the calling application. This data was obtained through experiments, and confirmed with source code analysis (for glibc and bionic) and documentation for Windows.
As shown in Table 1, a single packet loss will cause between 1 and 5 seconds of delay, which is enormous by today’s latency standards. Note that Android tries to limit the impact of such loss events (which can be common on unreliable mobile networks) by implementing a cache in the stub resolver itself and by selecting which DNS resolver to use based on past reliability statistics.
The case for persistent DNS connections
Looking more closely at the above problem, we can identify two different issues:
- The stub resolver implements both transport-layer and application-layer functionalities, with a tight coupling between the two — in other words, the DNS answer itself is used as a kind of acknowledgement. But this DNS answer has a very unpredictable delay, so it cannot be used to accurately estimate the Round Trip Time (RTT) between the stub resolver and the recursive resolver. Such an accurate RTT estimation would be necessary to detect losses in a timely manner.
- In general, no knowledge about the network is reused between successive DNS queries. In this respect, the Android stub resolver stands out as it collects statistics about reliability and response time to decide which recursive resolver it will query first.
Maintaining a persistent DNS connection using TCP or TLS tackles both issues. In this setup, the stub resolver opens a single connection to the recursive resolver and sends several queries in a row on this connection. It is now possible to accurately estimate the RTT to the recursive resolver and use past estimates to adapt the retransmission timeout for subsequent queries.
In Figure 2 below, we show the same example as before, but with a persistent TCP connection:

Figure 2: DNS over TCP recovers faster from losses
The end result is a much lower query latency in the case of packet loss, because of faster loss detection and retransmission. The overall latency could still be improved though, because TCP suffers from head-of-line blocking between successive queries due to its strict ordering guarantee. Future work using DNS-over-QUIC will hopefully avoid this pitfall.
Will it burn down my recursive resolver?
This is the next question that comes to mind, particularly ‘What if all stub resolvers started opening persistent TCP or TLS connections to their recursive resolvers?’ and ‘How badly would this overload the recursive resolver infrastructure?’.
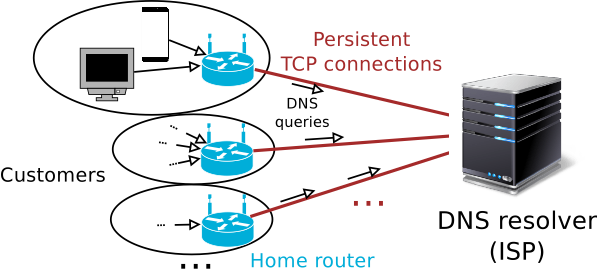
Our simplified architecture is shown in Figure 3, where each home router maintains a persistent TCP connection to an ISP-managed recursive resolver. Such a large-scale setup could easily lead to hundreds of thousands of simultaneous TCP connections to the same server. Conventional wisdom has it that TCP is expensive, so there is a cause for worry.

Figure 3: ISP model where all customers maintain persistent TCP connections to the recursive resolver
To test whether this approach scales, we experimented using a large-scale lab setup. We ran unbound on a physical server (2x Xeon E5-2630 v4), configured for a 100% cache hit. Next, we used dedicated hardware resources to spawn hundreds of virtual machines (VMs). Each VM opened persistent TCP connections to unbound, and then started generating DNS queries over them. We measured the latency of each query, and increased the query load until the point where unbound saturates. This allows us to measure the ‘peak server performance’ of unbound running as a recursive resolver, expressed in queries per second (qps).
On the plot below (Figure 4), we can see that as the number of TCP clients increases, the performance of the recursive resolver drops, and then stabilises at around 25% of the performance of the UDP baseline. We attribute this drop in performance either to CPU cache misses (because of the number of TCP connections to manage) or to the reduced number of opportunities for packet aggregation at the TCP layer.

Figure 4: Performance of unbound as the number of concurrent clients increases
To stress the system further, we went up to 6.5 million simultaneous TCP clients: unbound still kept up, with a performance of 50k qps per CPU core! The amount of memory used by unbound and the kernel was 51.4 GB.
Large-scale DNS-over-TCP seems feasible; it is slower than using UDP but only by a factor of 4. Given that the DNS infrastructure is typically over-provisioned to cope with events such as denial-of-service attacks, it is likely that current resolver infrastructure could withstand the additional load. Therefore, DNS-over-TCP can form an acceptable trade-off between improving client latency and increasing the cost of the recursive resolver.
Using TLS for all stub-to-resolver traffic?
Ten years ago, it would have been unthinkable to handle 6.5 million TCP connections on a single server. Today, thanks to the improvement of both software and hardware, it seems to be reasonable to switch all stub-to-recursive DNS traffic to TCP or TLS. Along with many security benefits, this could improve query latency for end users, for a manageable increase in cost on the recursive resolver.
Further work will involve testing DNS-over-TLS and DNS-over-QUIC in the same setup, and trying out other recursive resolver software. Sara Dickinson already performed a similar study in a smaller-scale scenario and found that TLS and TCP have similar performance characteristics.
Another area to study is the impact of connection churn on the performance of the recursive resolver.
This work was presented at RIPE 76. You can view the video and slides here: https://ripe76.ripe.net/archives/video/63/
Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Tom Arnfeld •
Super interesting. I have a couple of questions; Could you share more about the query traffic sample you used to generate traffic to unbound from the stubs? Also, have you spent any time looking at the real world impact of using TCP for recursive to authoritative? If one of the big sells for using TCP is better RTT measurements and retransmit logic, then this might help for unicast authoritatives hosted in bad networks, or geographically far away from their customer’s resolver. Are you aware of any stubs or resolvers that have options to prefer TCP configuration like this? Do you think it would be safe to enable TCP-first in stubs at scale, without causing resourcing issues on existing resolvers? Same question goes for resolver to auth. Thanks for a well written article!
Baptiste Jonglez •
Thanks for your comments! The traffic is generated according to a Poisson process, with all queries being identical (A query for example.com, with a static answer configured on the resolver). Not very realistic, but it's simple and I couldn't find real-world data on temporal distribution of queries. The issue with recursive-to-authoritative is the generally lower amount of connection reuse: you would pay the overhead of opening a persistent connection (high latency, high CPU cost for TLS) for just a few queries. Then, either you leave the connection open with almost no traffic, which would be costly for the authoritative side, or you close it, and it will be costly for you to open it again later. That being said, QUIC may make this easier with its 0-RTT connection resumption. Regarding support in stub resolvers, TLS stubs like stubby already use persistent connections because TLS is costly to setup :) If I remember well, they generally use a configurable timeout (for instance, if no queries are made for 5 seconds, they close the connection to the recursive) I think that's the way to go, because TLS adds privacy and does not seem much more costly than TCP once established (this is a preliminary result). In any case, recursive resolvers need to be configured accordingly: unbound for instance only accepts 10 simultaneous TCP/TLS connections by default... And you also need to raise various file descriptor limits if you want to handle lots of simultaneous connections. There is more details in the RIPE76 slides: https://ripe76.ripe.net/presentations/95-jonglez-dns-tcp-ripe76.pdf
Lennie •
Were the TCP-based queried head-of-line blocked ? And would thus HTTP/2 (implying TLS, possibly: TLS/1.3) have solved that head-of-line blocking ?