

RIPE Atlas probes are now active on five continents. After the big run on the measurement probes during the recent RIPE Meeting, the deployment is a little slower than expected; but there is a steady stream of probes coming online. We expect to make our initial goal of 300 active probes well before the end of 2010. Probe hosts can win an iPad by keeping their probes up during December.
10 Days After the RIPE Meeting
10 days after the RIPE meeting we have about 300 RIPE Atlas probes distributed and 150 active and measuring:




100 More Probes
We will shortly distribute 100 more probes to hosts who pre-registered earlier. Although requests are highly concentrated we will aim for an even distribution again:
1000 More Probes
We are currently working with our hardware manufacturer to obtain 1000 or more additional probes in order to satisfy demand. Stay tuned if you have requested a probe.1 iPad For You ?!!
And if you already have a probe, please keep your promise and get it online. As promised by us, all hosts of a probe that is taking measurements in December 2010 will have a chance to win an iPad. The drawing will be in January and your chances are proportional to the up-time of your probes.

Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Anonymous •
Just to share some experiences getting probes installed: I pre-registered for two probes (one for home, one for the office), and picked them up in Rome, no problem. Getting them installed turned out to be a little more subtle than expected, though!<br /><br />The probe at home was the first one I got working. The challenge here was hardware: The ISP my gateway provides simply has no ethernet ports! (It offers only 802.11.) Luckily, I had a spare DD-WRT enabled router handy, so I was able to configure it "backwards", using 802.11 as an uplink, NATted to the ethernet ports as downlink. Once I got that set up, I plugged the USB end of the ATLAS probe into an iPhone charger block and ran an ethernet cable to the DD-WRT, and the probe showed as "Up" on atlas.ripe.net within a few minutes. In summary:<br />(uplink)---CPE---(wifi)---DD-WRT---(ethernet)---ATLAS<br /><br />The issue at the office was more one of policy. Corporate IT policy forbids any devices that don't come through official channels from being connected to the internal network, and IT wasn't willing to set up an external LAN with it's own DHCP server just to run a single probe. It was a couple of weeks before I realized that we also have an external-facing visitor network (with DHCP); the probe is now wired in there and happily measuring away.<br /><br />So at least for now, I've got two green triangles on the map!
Anonymous •
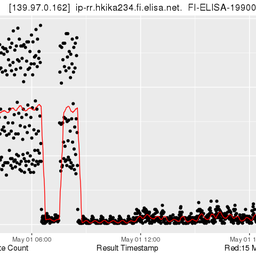
My experience on the uptime measurements is a bit strange.<br />I pluged my probe directly into my router, a Draytek Vigor 2130n, and left it alone untill now.<br />While my router says the uptime is 25 days, when I look at my probe on the atlas site, it has had a dozen disconnects allready.<br />My router's log does not show any disconnects, nor does my own monitoring system.<br />I assume some of them were caused by firmware upgrades by RIPE, others because of perhaps config changes as I saw a new controler has been deployed early December, but I cannot explain the other disconnects. So the measurements are not as stable as my own measurements.<br />And offcourse I want to win the Ipad :-)
Anonymous •
Hi Antoin,<br /><br />there are indeed some instabilities with some of probes. We do not<br />know the reasons for these yet. In your case we suspect that the Draytec<br />Vigor somehow blocks our traceroute measurements. We have seen this<br />with other probes behind these routers as well. Of course this should not make the probe flap, but it does. We are investigating. In addition we had other problems as reported in the message to the ripe-atlas mailing list before:<br /><br />Date: Thu, 16 Dec 2010 14:57:46 +0100<br />From: Daniel Karrenberg<br />To: Robert Kisteleki<br />Cc: Harald Firing Karlsen, ripe-atlas<br />Subject: Re: [atlas]Probe flapping<br /><br />Intermediate update to keep those interested informed.<br />I am writing this to keep the engineers free to work<br />the problem. I do not know nitty gritty details, so<br />this is a general overview.<br /><br />No conclusions yet.<br /><br />Architecture:<br /><br />After registering with the RIPE Atlas network the probes are connected<br />to "controllers" that handle requests to/from the probes. The<br />architecture allows probes to use any controller in the system. Probes<br />are distributed among controllers according to geographic and load<br />balancing heuristics at the moment. We have four controllers at the<br />moment:<br /><br />1 in Germany on a dedicated server: jonin<br />1 in the US on a dedicated server: carson<br />2 in NL on RIPE NCC VMs: caldwell and zelenka<br /><br />You can see the number of probes associated with each controller and<br />some other details on<br /><br /> <a href="https://atlas.ripe.net/statistics" rel="nofollow">https://atlas.ripe.net/statistics</a><br /><br />This page is updated hourly.<br /><br /><br />What happened:<br /><br />This morning zelenka was in standby and ronin started disassociating<br />probes in a massive way. We do not know the root cause of this.<br />The most likely cause so far is a connectivity problem but we are<br />investigating with an open mind.<br /><br />The system reacted as designed and the probes dropped by ronin started<br />to register with caldwell. Unfortunately caldwell became overloaded by<br />this both because of its physical limitations and because of an<br />unfortunate database configuration error.<br /><br />Probes associated to carson were not affected.<br /><br /><br />What we are doing:<br /><br />We brought up Zelenka but as Murphy dictates the RIPE NCC firewall<br />prevented probes from reaching it. This has been fixed and zelenka is<br />now picking up probes.<br /><br />We are working hard to fix a lot of minor problems uncovered by this and to get all probes re-connected and their data backlog processed.<br /><br />What we have learned so far:<br /><br />We need a larger safety margin in the capacity of the controllers vs the<br />number of deployed probes. We will start moving caldwell and zelenka<br />onto physical machines outside of firewalls and other complications.<br /><br />We also need to exercise moving probes among controllers and verify that<br />the safety margin exists in reality.<br /><br />Personally I regard all this as normal teething problems in a<br />distributed computing deployment. So far the architecture is holding up<br />well. Just the implementation has some flaws. Please bear with us.<br /><br />If anyone has suggestions for high quality hosting of controllers in the<br />RIPE region, please drop me and Robert a private mail.<br /><br />Daniel