
Last week there were several problems with the RIPE NCC's reverse DNS (rDNS) service. This article is a first report about the events. It is not intended to analyse the causes or make detailed recommendations for action.
Scope
Last week there were several problems with the RIPE NCC's reverse DNS (rDNS) service. This article is a first report about the events. It is not intended to analyse the causes or make detailed recommendations for action. We briefly describe the systems involved, the time-line of events and, finally, we list a number of immediate actions we have taken to improve our systems and procedures. Over the coming weeks, we will analyse the causes of these events and take the appropriate actions. We will conclude this process with a short report.
Introduction
rDNS is a part of the DNS that translates IP addresses to domain names, the inverse function of the regular DNS. rDNS can be used for diagnostic, logging and verification purposes. rDNS is not typically used in a way that makes it critical for browsing the web; rDNS is used frequently in the process of delivering electronic mail.
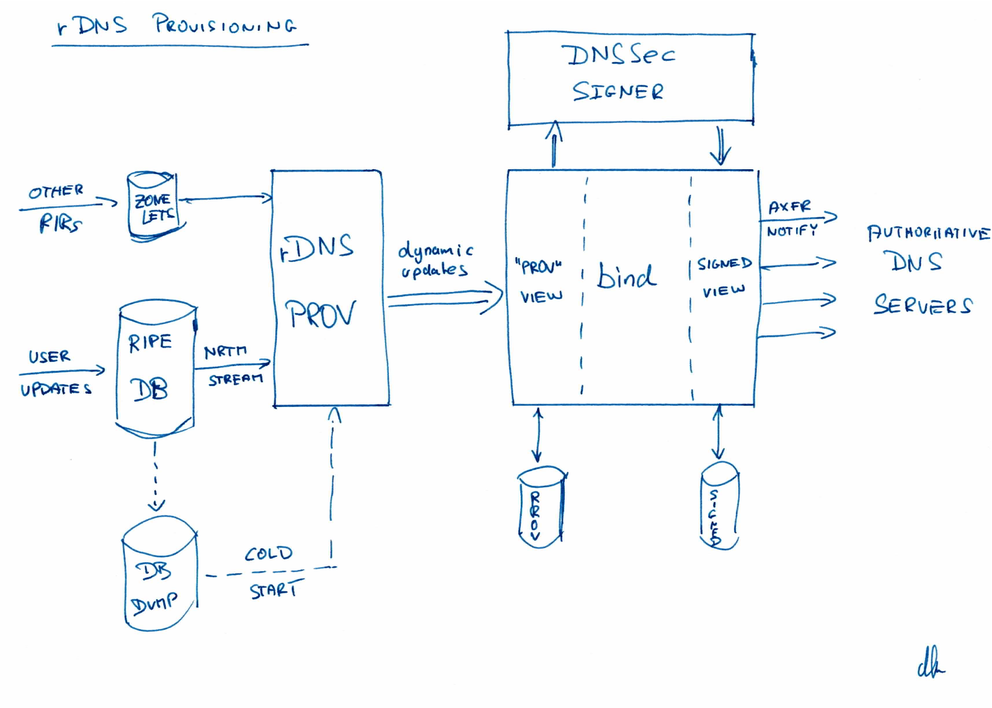
rDNS look-ups follow the IP address hierarchy. Therefore, the RIRs have a major role in providing the rDNS service. The RIPE NCC publishes rDNS information from two sources. The majority of the rDNS data comes from the IP address registry stored in the RIPE Database; this covers all address space allocated via the RIPE NCC since around the mid 1990s. The address space users can update this information in the RIPE Database and the rDNS provisioning system then translates it into rDNS zone files. A small amount of the rDNS data mostly pertaining to address space distributed before the mid-1990s comes from "zonelets" exchanged among the RIRs. The rDNS provisioning system combines all that information, passes it through DNSSEC signers and transfers it to the authoritative name servers.
Please see below a high-level overview of the system:

Below you can find a table showing the series of events. You can also view the pdf version of the table .
| Time (UTC) | Events | Impact Assessment |
|---|---|---|
| Wed, 13 June | ||
| 13:30 | We discover that several zone files are missing from the DNS provisioning system [The cause of this is still unknown and under investigation. Circumstantial is a routine bind update in the morning.] |
No impact on DNS reverse operations, but zone updates broken for delegations in parent zones: 0.4.1.0.0.2.ip6.arpa, 185.in-addr.arpa, 4.1.1.0.0.2.ip6.arpa, 5.1.0.0.2.ip6.arpa, 6.1.1.0.0.2.ip6.arpa, 7.0.1.0.0.2.ip6.arpa, 7.1.1.0.0.2.ip6.arpa, 7.4.1.0.0.2.ip6.arpa, 8.0.1.0.0.2.ip6.arpa, a.0.1.0.0.2.ip6.arpa, a.1.1.0.0.2.ip6.arpa, a.4.1.0.0.2.ip6.arpa, b.0.1.0.0.2.ip6.arpa, b.1.1.0.0.2.ip6.arpa, b.4.1.0.0.2.ip6.arpa (a total of 425 delegations, 185/8 is in de-bogonising: no operational impact) |
| 13:45 | Decision to reload zone files from backup storage | |
| 14:00 | Discovery that backups are not available | |
| 14:15 | Decision to cold start the provisioning system. Because the state of the remaining zone files available was unclear, we decide to rebuild all zone files from scratch. | |
| 15:00 |
Start DNS provisioning system from scratch (empty zone files). By mistake we do not disable transfers to the authoritative servers. |
Empty zones for entire reverse tree start propagating Impact on whole of reverse DNS tree, limited initially by caching |
| 16:00 | Reports of reverse tree breakage start to come in | |
| 16:00 - 20:00 | Investigation of problems and considering possible workarounds for slow provisioning system cold start | |
| 20:00 | Found incidental backup of zone files with state of 13/6/2012 13:30 UTC | |
| 20:15 | Stopped DNS provisioning system. Reloaded DNS provisioning system with data from backup files. ERX related zones are missing from these backups, as are the above mentioned ip6.arpa delegations. |
missing: 0.4.1.0.0.2.ip6.arpa, 185.in-addr.arpa, 4.1.1.0.0.2.ip6.arpa, 5.1.0.0.2.ip6.arpa, 6.1.1.0.0.2.ip6.arpa, 7.0.1.0.0.2.ip6.arpa, 7.1.1.0.0.2.ip6.arpa, 7.4.1.0.0.2.ip6.arpa, 8.0.1.0.0.2.ip6.arpa, a.0.1.0.0.2.ip6.arpa, a.1.1.0.0.2.ip6.arpa, a.4.1.0.0.2.ip6.arpa, b.0.1.0.0.2.ip6.arpa, b.1.1.0.0.2.ip6.arpa, b.4.1.0.0.2.ip6.arpa (together containing a total of 425 delegations) |
| Authoritative servers reloading. However, a race condition in the provisioning system causes the zone serial numbers for two zones to be incorrectly updated. Therefore two large zones (212.in-addr.arpa and 213.in-addr.arpa) are propagating in an incomplete form. This causes severe breakage for these zones. In total approx. 6% of the reverse delegations are affected during this period | Restored zone files start propagating for all but the below mentioned parent zones (state of 13/6/2012 13:30UTC). Due to negative caching, impact on restored zones may have been prolonged. Details of impacted zones below | |
| Affected 6.1% of total reverse DNS delegations Parent zones 212.in-addr.arpa, and 213.in-addr.arpa are distributed incompletely. Affected: 43% in delegations in 212.in-addr.arpa, 54% of delegations in 213.in-addr.arpa. In total 33,996 delegations affected in these parent zones. ERX zones. ERX import zones: 4,426 delegations accross 22 zones absent during this period. ERX exports: updates delayed Above mentioned missing zones in ip6.arpa (475 delegations total) are still lacking during this period. RFC 2317 delegations: a total of 31 RFC 2317 delegations are lacking the associated CNAME records at this time. | ||
| 20:30 | Restarted DNS provisioning system, starting with state of 13.30 UTC. The DNS provisioning system is still running at an unexpectedly low insertion rate. | At this time we believed the remaining impact to be limited to a small number of ERX imported zones, and a limited number of ip6.arpa zones. The problems with 212.- and 213.in-addr.arpa went unnoticed until early morning of Thursday 14 June |
| Thur, 14 June | ||
| 7:00 | First reports received about remaining breakage | |
| 7:00 - 10:00 | Investigations of reported remaining issues | |
| 10:45 | We discover the that 212./213.in-addr.arpa are incomplete due to the above mentioned race condition. After updating serial numbers, zones 212./213.in-addr.arpa start propagating properly again. | Zones 212.in-addr.arpa and 213.in-addr.arpa, complete and up to date to the then-current state, start propagating again. ERX import zones (4426 delegations), ip6.arpa (475 delegations) and RFC 2317 zones (31 delegations) still not restored |
| 16:00 | Based on RIPE DB dump of 14/6/2012 0.00h, all regular zones are restored, incl. ip6.arpa zones | |
| 16:00- 16:30 | Processing of updates for period after 00:00 14/6/2012 | |
| 16:30 | All updates processed for all zones, with the exception of ERX zones | All regular zones restored and current. ERX import zones (4426 delegations) and RFC 2317 zones (31 delegations) still not restored |
| 19:30 | Restart processing of ERX delegations (much slower than anticipated) | |
| 20:00 | Majority of ERX zones handled | ERX import zones (2 delegations) and rfc2317 zones |
| Fri, 15 June | ||
| 7:30 | All regular zones restored including last remaining 2 ERX zones | All zones, incl. ERX imports, fully functional, with the exception of 31 RFC 2317 delegations that were not discovered to be missing their CNAME records. |
| Mon, 18 June | ||
| 11:00 | Discovered error with 31 delegations lacking RFC 2317 CNAME records | |
| 13:45 | Restored remaining RFC 2317 delegations |
Immediate Actions Taken
We acknowledge that our operational performance was not up to the standards the RIPE community expects from the RIPE NCC in this instance and apologise for the considerable inconvenience caused. We have taken the following immediate steps and we will take further actions once the events have been fully analysed:
- We have started ad-hoc backups of the bind zone files
- We have re-emphasised the 4-eyes principle in case of operational irregularities
- We have clarified the service announcements procedures

Comments 23
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Ben Hayes •
Poor procedures here "14:00 We discover backups are not available" we pay a small fortune to be a Ripe member and would expect a much more professional approach to backups and incident management with much tighter policies, very disappointing.
Mark Jones •
It might be good for a team of RIPE members to be invited to oversee and review the system processes in use at RIPE. If this happened in a commercial environment then the HR people would have been involved and possible suspension of relevant personells while an investigation is taking place.
randy •
you are to be commended for an open post mortem. there are lessons for us all in it. luckily none of us real operators have such problems :) interesting that nothing happened on the weekend. ahem. and the "Listen to audio for this captcha" on this comment entry page plays a very different captcha!
Mark Jones •
The other thing that is noticeable from the hand drawn diagram is that you do not the systems/processes documented?
Nick Hilliard •
Daniel, thanks for the candid update. Never nice to have to admit in public that you had 4 discretely identifiable problems to cause a cascading sequence of failures, but it does happen from time to time. It's also unfortunate that they had such far-reaching consequences in this situation. I hope when you're reviewing the engineering build of this system that you can find ways of inserting fail-safe mechanisms so that if there are failures in future, the consequences will be less serious. Most experienced operators have had to deal with backup failures during critical systems failures. The only solution to this is test, test and test again as part of your DR management framework. This is as unimaginably tedious as it is necessary. Difficult to imagine how HR involvement would help things - I've never noticed that HR personnel had much skill in the area of engineering management. However, I have found that exposing the engineering underbelly of an failure like this to the court of peer scrutiny is an acutely honed means of ensuring that problems like this won't happen again. There are a lot of engineers in this community. We like to dissect things, including failure dissections. Peer analysis can be highly procedurally redemptive. I look forwarding to reading the final report on this incident.
Daniel Karrenberg •
One response to all comments so far:Of course back-ups should have been there. We are still investigating exactly why they were not. My suspicion is that in practice this happens much more often than is generally admitted. No information was lost, no updates were lost. We consider ourselves very professional but not infallible. If anyone with appropriate credentials and experience were to offer a free review of our processes under appropriate conditions, I would seriously consider it. What good could come from "suspending" any staff in connection with incidents like this? We would end up with less people to help investigate what happened, get less information from the people who know the most and having to do all the other work with less people too. Not to speak about what it would do to morale. That is not professional. Professional is to analyse, draw conclusions and then take appropriate action. Such action may very well include consequences for those responsible for design and operation of systems, but it is only very rarely professional to discuss those in public. There was no need to work in the weekend. We were back in business by 07:30 Friday and for all practical purposes the evening before. P ost-mortems are not weekend work. And rest assured that we were monitoring closely during the weekend. Of course we do have our processes and software documented. Sharing the detailed documentation here would neither be useful or appropriate. My choice was either to use the hand-drawn figure or to delay publication and waste resources on a "professional" version that would contain the same information. I opted for timely publication and saving resources. And you get an original Karrenberg to boot. Frame it! Personally I strongly believe in openness, learning lessons and sharing them. This culture helps to improve systems and to avoid repeating mistakes. Therefore I welcome constructive comments, even more so once the analysis is complete and we have reported our conclusions. Personally I can also deal with the not-so-constructive comments. However, should they appear to remain the majority, it will become difficult to defend and nurture a culture of openness. So thank you Nick for your remarks.
tzn1 •
You can only learn from failure. Errors are inevitable. I congratulate you on the open approach.
Mark Jones •
Daniel, My apologies if my comments were a bit strong. It's based on experience in similar situations in commercial organisation where senior managements insist on certain steps/processes to be followed in any subsequent investigation. It's unfortunate that this does have a commercial impact on our customers who have to rely on us to ensure that their email can be delivered without being blocked.
Avoiding posting from my PI... •
I would echo the appreciation for the frank nature of this post, while most of the information had previously been released on an Ad hoc basis, it is refreshing contrast to both commercial and mutual operators.. some of whom could appear to hide behind non-disclosure clauses when communicating details of incidents which affected double digit percentages of the Internet population. While probably out of scope for a post on the engineering blog, I do feel there is a conspicuous absence of information on the time line relating to how and when the incident was communicated to both LIR 'customers' and the broader user base who may have been impacted. The fact this post specifically apologises for the operational failings is a positive step; however despite the statement that RIPE "have clarified the service announcements procedures", I doubt that I am alone in looking forward to clarification on why it took several hours between it being discovered "that several zone files are missing" and somebody thinking it might be useful to communicate this... Lastly on the topic of the 'hand drawn' diagram, in this industry it could be argued that your credibility is lacking if there isn’t at least one network or Internet facing system still in use which you personally designed on a napkin or the back of a beer mat :)
Svein Tjemsland •
There was no info on the trouble with 212.in-addr.arpa on your service announcement after it was discovered, it should have been posted earlier (as soon as it was seen).
Roger Jørgensen •
Nice drawings just to mention that. Been there done those mistakes that happen, (forget to disable transfer etc), it is so easy in the heat of the moment, but that don't make it acceptable from a profesional part like RIPE NCC. However, I hope you learn from these incident and train for handling total disaster and completely unexpected failures so it won't happen again :-)
Ian Eiloart •
I guess that's a typo at 10:45, 14 June? "We discover the that 212./231.in-"… should read 212./213….?
Daniel Karrenberg •
Svein, when we finally discovered that 212./213in-addr.arpa were incomplete it was fixed within a couple of minutes. So an update on that discovery would not have been useful. Earlier in the morning we were not updating because there was nothing new to report. We simply did not know what was going on, whether it was us or negative caching somewhere else, or ... . With hindsight we now realise that we should have given an update earlier that morning saying "We heard the reports of ongoing problems and are investigating." We will review our communications procedures to make sure that such "We have heard reports and are working on it." messages are indeed sent. We are also reviewing the channels you can use to reliably report problems 24/7. We will report on this later.
Daniel Karrenberg •
Ian, typo corrected.
Daniel Karrenberg •
Avoiding posting ..., the communications time-line is preserved at http://www.ripe.net/lir-services/service-announcements/reverse-dns-services-issues . We will cover this in the final report.
Martin Stanislav •
Daniel, thanks for sharing. Regarding the drawing, can you please update the overview for a case when rDNS zone updates are propagating to zonelets from RIPE DB through rDNS Prov? That's a flow when a user update to an ERX zone within the RIPE DB has to make it all the way to another RIR's authoritative name server. I presume the "zonelets to rDNS Prov" arrow would turn into a two way one. Were there any ERX zones affected concerning the depicted flow?
Anand Buddhdev •
Hi Martin. You are right. The DNS provisioning system also generates zonelets for address space registered in the RIPE Database, but whose reverse DNS zone is managed by another RIR. These zonelets are generated at 30 minutes past each hour, and published to the RIPE NCC's FTP server, in the directory /pub/zones, so that other RIRs can pick them up and insert the relevant records into their reverse zones. This is a slower process, and so it can take a few hours before such an "ERX delegation" appears in the relevant parent zone. During the outage, our provisioning system was not generating these zonelets, so the other RIRs had nothing to pick up (not even empty zonelets). Therefore, they made no changes in the zones they manage. As a result, the ERX delegations were still available. The slowness of the inter-RIR zonelet transfer process was a benefit in this case.
Daniel Karrenberg •
Martin, I made this drawing specifically as a graphical aid to reading the time-line in this article. Therefore I left out system details that are not relevant for reading the time-line. Zonelet generation is one of these details. Anand has already explained why this part of the operation was not affected.
Jallaledin Sharifi •
Daniel, thanks for sharing. Regarding the drawing
Charles Martin •
Real operators, AKA _for profit_ operators have no lack of skeletons in their closets. The only difference here is between the culture of openness and responsible disclosure compared to the culture of hiding behind corporate doublespeak. So, the sharing of information is very appreciated, thanks! My 2 cents.
K Attard •
The important thing is that now things are ok. Having an open fair lessons learnt process is very remarkable. 2 things I would suggest which are internal processes reviews and dr processes. We are all human so we are prone to mistakes. Hopefully there is no next time
Fred Arendse •
Dear Daniël, I am behind the keyboard since 1974 and can assure you that ANY methode you choose or how much money you would spend for it to keep backups safe will eventually explode in your face. My advise which I can give to RIPE is as follows: NEVER, EVER run a primary DB (DNS/rDNS) server out in the open. Always run a primary DNS server on private IP's, use NAT translation towards selected public secondary DNS server which do the actual advertising for you. NEVER, EVER trust one single OS to run DNS. If you use the method above, it is possible to pick up the zones on different platforms. (Even mainframes like IBM/TPF could be included also) Bind/SQL DB: reconstruct your DB from source files every 24 hours. Bring the original down for 1 second and swap the names of the live DB with the rebuilded DB. This methode comes directly from airlines which evidently run the biggest DB's worldwide... You could even run integrity checks before you publish the new DB. Hope it helps...
Daniel Karrenberg •
Short status update: We have implemented a number of changes to operational and communications procedures. We are in the process of improving things further. The full report will take some more time because we intend to make it a good read.It will be published mid-September.