

On 23 March 2021, LINX London experienced an outage. As this is one of the very large Internet Exchange Points, this is an interesting case to study in more depth in order to see what we can learn about Internet robustness.
On 23 March, Internet traffic around the London Internet Exchange Point, LINX, showed some dramatic shifts. This was caused by issues on one of the peering LANs at LINX, as described on the LINX incident page:

The issues on the LON1 LAN were clearly visible in traffic stats, as can be seen in Figure 1:
Figure 1: LINX London LANs traffic stats (tweet by DrPeering)
A massive amount of traffic - multiple terabits per second - shifted away from LON1.
When we see outages around such large infrastructures as IXPs, we always want to find out more about the impact they have on routing. As the Internet was designed so it can "route around damage", what we really want to know is whether this indeed happens at a large scale. For the two events we looked at earlier - AMS-IX in 2015 and DE-CIX in 2018 - we concluded that, based on the RIPE Atlas traceroutes we analysed, the Internet, at large, does indeed route around the damage, although for a short period of time there is some loss and instability.
It's probably a funny coincidence that outage events at these large IXPs are spaced apart by three years. One can interpret that as either a remarkable feat of engineering, or a reminder that eventually every piece of infrastructure has to fail at some point.
RIPE Atlas Traces through LINX LON1
As with previous analyses at large IXPs, we use a subset of all RIPE Atlas traceroutes. Specifically for all of the analysis below, we only look at traceroutes between source/destination pairs that have the following two properties:
- The destination address reliably responds
- The traceroute reliably contains an IP address in the LINX LON1 peering LAN
See [1] for an exact definition.
Using this method, we selected 26,258 source/destination pairs (4,291 RIPE Atlas probes, and 815 traceroute destinations) in IPv4. In IPv6, we selected 14,751 source/destination pairs (1,644 RIPE Atlas probes, and 754 traceroute destinations) this way. The remainder of the analysis is only using data from traceroutes between these source/destination pairs on 23 March.
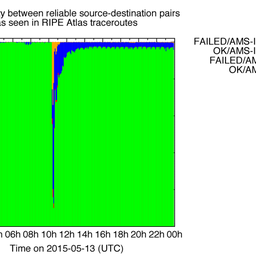
In figures 2 and 3, we show whether these traceroutes, on the day of the outage, contained an IP address in the LINX LON1 peering LAN and whether the destination responded. What we see is very similar to analyses of earlier large IXP outages. Before the outage, we see paths going via the IXP and reliably getting responses from the traceroute target (indicated in dark blue). This is an indication that the source/destination pairs we selected for this study are reliable in detecting these two properties.
Around 11:00 (UTC), we see a small fraction of traceroutes starting to use alternative paths (not via LINX LON1), but these traceroutes still contain responses from the traceroute target (this fraction is indicated with light blue). These are paths that are rerouted, but where end-to-end connectivity is not affected. Then, at around 15:30 UTC we see both a large fraction of traceroutes showing signs of rerouting (light blue), but also roughly 20% of traceroutes fail to reach the intended target (indicated in red). Soon after this, the situation goes back to normal again, although a relatively large fraction of traceroutes show signs of rerouting (light blue). This is mostly similar for IPv4 and IPv6.

Figure 2: Visibility of LINX LON1 peering LAN and end-to-end connectivity in RIPE Atlas traceroutes ( IPv4 )

Figure 3: Visibility of LINX LON1 peering LAN and end-to-end connectivity in RIPE Atlas traceroutes ( IPv6 )
We also looked if we could identify other IXP peering LANs in the traceroutes we are looking at. For this analysis we used all IXP peering LANs that we could extract from PeeringDB. We also flagged all traceroutes where we didn't see any IXP peering LAN IP addresses. Figure 4 is the result of this analysis for IPv4 traceroutes. The drop in use of LINX LON1 is clearly visible at the time of the outage-event.
Figure 4 also contains the five most seen alternatives for paths via the LINX LON1 LAN:
- The first, and most seen alternative is paths that do not contain IXP LANs at all. We didn't look into this in detail (yet), but it's expected that this is mostly paths that started to go via transit, thus potentially causing extra traffic cost.
- The second most used alternative that we saw was diversions of the path via the two other very large IXPs: AMS-IX Amsterdam, and DE-CIX Frankfurt. We see more paths over AMS-IX than over DE-CIX, but it's unclear what causes this. AMS-IX is closer to LINX LON (roughly 5ms round trip delay) than DE-CIX is (roughly 10ms round trip delay). Paths that were diverted via these IXPs likely incurred an extra round trip delay, relative to what the paths used to be earlier that day.
- The third most used alternative that we saw are IXP peering LANs in London. For both LINX LON2 and LONAP we see an uptick in paths when the LON1 LAN had problems, but the uptick is not as big as for the previously described categories.
Not in figure 4 are the next few IXPs were we still see a slight uptick: France-IX, which is an international diversion, but still relatively close to London, and IXManchester, which is at a similar physical distance as Paris and Amsterdam, but within the same country.
What is also interesting in Figure 4 is that after the initial outage of LINX LON1, the number of paths via these alternatives stays elevated. We saw this before in the analyses of outages at other large IXPs. The reasons for this are likely twofold, with network operators keeping their sessions at the affected peering LAN down until they are confident enough to reestablish them, but also in the BGP decision process, with all higher ranking decisions on paths being the same, the oldest path wins. So if a peering session over LINX LON1 was closed and reestablished, the paths that one would receive over it would be "fresh", and if alternatives with similar BGP attributes (preference, path length) existed, these would be selected for routing.

Figure 4: LINX LON1 and alternatives seen in RIPE Atlas traceroutes (IPv4)
In Figure 5, we take a look at the number of paths for LINX LON1 and the alternatives mentioned above, but now we look at IPv6 traceroutes. A similar picture emerges. Paths where no IXP peering LAN is visible are the most seen alternative. In IPv6 traceroutes, we also see that the number of paths via all of these alternatives stays elevated. The most striking difference is that LONAP is relatively more popular in IPv6. The peak of the number of traceroutes going over LONAP in IPv6 in this analysis is slightly higher then the peak for DE-CIX Frankfurt.

Figure 5: LINX LON1 and alternatives seen in RIPE Atlas traceroutes (IPv6)
Conclusion
So, does the Internet route around damage? As with our earlier case-studies around large IXPs and outages, our data and analysis suggests it mostly does. How does it route around damage? In this case, we see that alternative paths that don't go via IXPs are the most used alternative, followed by alternative paths via other IXPs.
Questions/comments/tomatoes/flowers, please leave a comment below, or let us know at labs@ripe.net!
Footnote:
[1] We selected only traceroutes between source/destination pairs where there are at least 48 traceroutes (one every 30 mins) on the day before the outage (2021-02-22) and on this day 100% of traceroutes have a responding target, and 100% of traceroutes contain an IP address of the LINX LON1 IPv4 peering LAN
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.