
Engineers from the Wikimedia Foundation and the RIPE NCC recently collaborated on a project to measure the latency of Wikimedia sites for users worldwide. Together, we identified ways to decrease latency and improve performance for users around the world.
During RIPE 67, Faidon Liambotis ( Principal Operations Engineer at the Wikimedia Foundation) and I got into a hallway conversation. Long story short: We figured we could do something with RIPE Atlas to decrease latency for users visiting Wikipedia and other Wikimedia sites.
At that time, Wikimedia had two locations active (Ashburn and Amsterdam), and was preparing a third (San Francisco), to better serve users in Oceania, South Asia, and US/Canada west coast regions. We were wondering about the effects on network latency for users worldwide for this third location and Wikimedia wanted to quantify the effect that turning up this location would have.
Wikimedia runs their own Content Delivery Network (CDN), mostly for privacy and cost reasons. Like most CDNs, to geographically balance the traffic to their various points of presence (PoPs), they employ a technique called GeoDNS: a user will, based on the DNS request that is made on their behalf from their DNS resolver, be specifically directed to one of the data centres based on their or their resolver's IP address. This requires the authoritative DNS servers for Wikimedia sites to know where to best direct the user to. Wikimedia uses gdnsd for authoritative DNS to dynamically respond to those queries based on a region-to-data-centre map.
Some call this " stupid DNS tricks "; others find it useful to decrease latency towards websites. Wikimedia is in the latter group, and we used RIPE Atlas to see how this method performs.
One specific question we wanted answered is where to "split Asia" between the San Francisco and the Amsterdam Wikimedia location. Latency is obviously a function of physical distance, but also the choice of upstream networks. As an example, these choices determine if packets to "other side of the world" destinations tend to be routed clockwise or counter-clockwise.
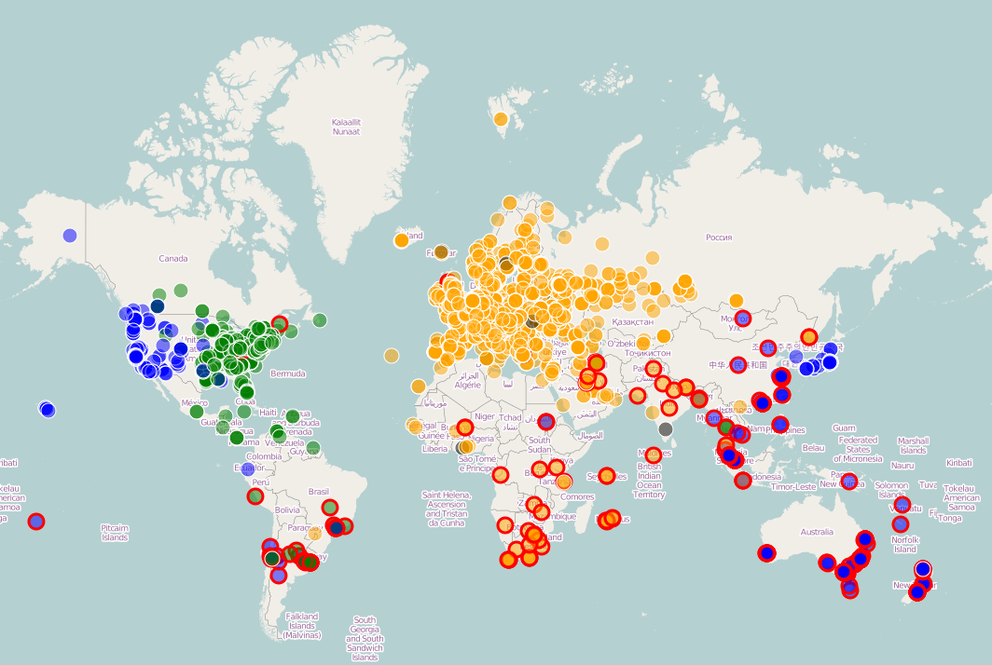
We scheduled latency measurements from all RIPE Atlas probes towards the three Wikimedia locations we wanted to look at, and visualised which data centre showed the lowest latency for each probe. You can see the results in Figure 1 below.

This latency map shows the locations of RIPE Atlas probes, coloured by which Wikimedia data centre has the lowest latency measured from that probe:
- Orange: the Amsterdam PoP has the lowest latency
- Green: the Ashburn PoP has the lowest latency
- Blue: the San Francisco PoP has the lowest latency
Probes where the lowest latency is over 150ms have a red outline. An interactive version of this map is available here. (Note that this is a prototype to show the potential of this approach, so it is a little rough around the edges.)
Probes located in India clearly have lower latency towards Amsterdam. Probes in China, South Korea, the Philippines, Malaysia and Singapore showed lower latency towards San Francisco. For other locations in Southeast Asia the situation was less clear, but that is also useful information to have because it shows that directing users to either the Amsterdam or the San Francisco data centre seems equally good (or bad). It is also interesting to note that all of Russia, including the two most eastern probes in Vladivostok, have lowest latency towards Amsterdam. For the Vladivostok probes, Amsterdam and San Francisco are almost the same distance, give or take 100 km. Nearby probes in China, South Korea and Japan have lowest latency towards San Francisco.
There is always the question of drawing conclusions based on a low number of samples, and how representative RIPE Atlas probe hosts are for a larger population. But having some data is better than no data in these cases, and if a region has a low number of probes, that can always be fixed by deploying more probes there. If you live in an underrepresented region you can apply for a probe and help improve the situation.
With this measurement data to back it, Wikimedia has gradually selected Oceania, Southeast Asian countries and US/Canada states/provinces to which RIPE Atlas measurements showed minimal latency to be served by their San Francisco caching PoP. The geoconfig that Wikimedia is running on is publicly available here .
As for the code that created the measurements and created the latency map, this was all prototype-quality code at best, so I originally planned to find a second site where we could do this, to see if we could generalise scripts and visualisation and then share.
At RIPE 68 there was interest in even this raw prototype code for doing things with data centres, latency and RIPE Atlas, so we ended up sharing this code privately, and have heard of progress made on that already. In the meantime we've put up the code that created the latency map on GitHub . Again, it's a prototype – but if you can't wait for a better version, please feel free to use and improve it.
Conclusion
A couple of interesting things are in the pipeline: Wikimedia is rolling out more locations, such as their new Dallas, Texas data centre and potentially more caching PoPs in the future. Based on the success with their San Francisco PoP, Wikimedia intends to incorporate RIPE Atlas data into the decision process for turning up those locations as well. Moreover, Wikimedia intends to expand the use of RIPE Atlas for other purposes, such as network monitoring using RIPE Atlas status checks .
Wikimedia is also going to host RIPE Atlas anchors at their data centre locations, which act as enhanced probes with greater measurement capacity.
If you have an interesting idea but have no time, or other things are stopping you from implementing it, please let us know! You can always chat with us at a RIPE Meeting , regional meeting , via email or any other channels. We don't have infinite time, but we can definitely try out things, especially ideas that will improve the Internet and/or improve the life of network operators.
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.