
At RIPE 67 we presented our ideas on infrastructure geolocation. We received positive feedback for developing this idea. This article shows the current thinking on how to develop router geolocation further. Any feedback will be appreciated.
Introduction
We gave a presentation at the MAT Working Group at RIPE 67 , to see how much interest there is in improving router geolocation. Internet geolocation databases are predominantly tailored towards finding the approximate location of end-users, by IP address. These databases are pretty accurate, but typically lack good quality information about IP addresses that are used on Internet infrastructure such as servers and routers. Geolocation information for infrastructure is important because it helps understand what physical path packets actually take on the Internet. This is helpful for troubleshooting routing, but also has potential for making decisions about extending networks, or figuring out what is going on during a natural disaster or other events affecting the Internet.
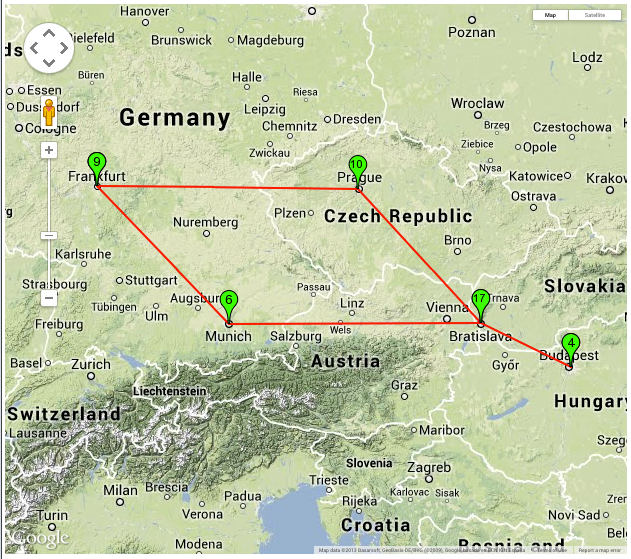
One thing better infrastructure geolocation, especially router geolocation, would allow is visualisation of traceroute data on a map, as is shown in Figure 1 below.

Figure 1: Example of 'traceroute-on-a-map'. In this example the forward path from a host in Budapest to Bratislava is shown on a map. The plotted path detours via Frankfurt and Prague.
From the feedback that we received we understand that people find router geolocation an interesting topic and would like us to advance the state-of-the-art in this field. It was also suggested on the MAT Working Group mailing-list to consider DNS LOC records.
Our current plan is this to improve router geolocation in the following way:
Find multiple sources of data from which we can derive potential geolocation. The sources we have this far identified are:
- Hostnames obtained through reverse DNS lookup
- IXP prefixes
- Existing IP geolocation databases
- Triangulation by round trip times (RTTs)
- Traceroute measurements
- DNS LOC records
By combining information from all of those sources and appropriately weighing each data source we can come up with a list of likely locations for a given IP address, together with a score on how likely this is correct. For instance for a given IP address the answer could be:
- 95% Bakel, The Netherlands
- 4% Bakel, Senegal
Let's focus a bit more on each individual data source:
Reverse DNS lookup of hostname
If we do a reverse DNS lookup for a given IP address, for a lot of infrastructure we get back a hostname that contains a lot of clues about the geolocation of the IP address in use. Quite often hostnames contain airport codes, abbreviated or whole city names and sometimes also clues about data centers. We'd like to see if we can extract these clues, both in an automated fashion or alternatively by crowdsourcing this.
IXP prefixes
IXPs are quite often specific to one or few easily identifiable locations. There are databases, like peeringdb and the Euro-IX IXP directory , that contain a lot of useful information about IXP peering LAN IP addresses combined with their physical location. This type of data provides a strong clue about the wereabouts of the infrastructure that is using these IP addresses, but it is certainly not bulletproof: IXPs can serve multiple data centers that are not necessarily within the same city, and peering LAN IP addresses can be in use in locations far away from the IXPs switching fabric ("remote peering").
Existing IP geolocation databases
Existing IP geolocation databases typically focus on end-users. What we've seen for network infrastructure IP addresses the information in these databases is typically directly derived from RIR databases. So for instance large blocks of IP addresses all geolocate to the headquarters of organisations, while the IP addresses seem to be in use all over the world. That said, for networks that have a smaller scope, for instance networks that are only in a single city, this information can still be useful, if only to provide a baseline on which the other sources of data can incrementally be build.
RTT Triangulation
The speed of light puts an upper bound on how fast information can travel on the Internet, so if a response to an ICMP echo request packet is received in a certain number of milliseconds it's easy to calculate what the maximum distance between sender and responder is. Signals on the Internet typically travel through fiber, in which information travels at roughly 2/3 of the speed of light in vacuum. This, together with a large number of points from which to send ICMP packets spread around the globe (through RIPE Atlas ), allows us to confine the possible location of the device that responds to ICMP. One potential complication in this is that sometimes devices respond "on behalf of" other devices.
DNS LOC records
It's been suggested to look at DNS LOC records. These are DNS records that link a hostname to a geographic location. In an initial search we found 54,119 LOC records in 16 separate domains, identifying a total of 708 unique locations. Of these records 37,225 were with a single organisation in Hungary. After removing these we find an interesting mix of incumbent telcos and research and education networks using LOC records:
- francetelecom.net (5,862 records found)
- eurorings.net (3,823 records found)
- switch.ch (2,784 records found)
- opentransit.net (1,485 records found)
- internet2.edu (1,454 records found)
- uninett.no (893 records found)
- kyla.fi (335 records found)
- nordu.net (121 records found)
Domains for which we found less then 100 LOC records are omitted from this list. The list of entities using LOC records seems low, but it's easy to include, and further on, it can provide an easy input loop for people who want to influence the system we plan to set up.
Crowd sourcing
We intend to provide an interface that facilitates both input of geolocation info for IP resources and correction by a human. This human input can be used to refine the inferences we made.
Cooperation
We have reached out to other organisations that are doing work in this area to see where we can cooperate. This far that has been: CAIDA , the IXmaps project and the spotter project .
Additional considerations
We identified 3 granularities at which geolocation data could be most useful: country-level, city-level and PoP-level. For now we think we should limit ourselves to country- and city-level, but whatever we end up with should also be extensible to work at the PoP-level if people would like to also see this.
We intend to make the method and data coming out of this open, so existing geolocation databases and other geolocation projects can also benefit from this if they want.
Although we haven't specifically planned for anycasted resources, ie. IP addresses used in multiple places at the same time, our probabilistic model should be able to show the multiple locations where the IP addresses are in use with roughly equal probability.
If people have any additional comments or input on this plan, please let us know. Either in comments below, or email us at labs@ripe.net .
Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Mike Hughes •
As the retro individual who suggested it, interesting to hear that DNS LOC records aren't completely dead!
Konstantin Bekreyev •
Very valid question I was asked in MaxMind on my request #61692: How can we know in what prefixes in Internet have DNS LOC records? We'd like to avoid scanning all of the IPv4 and IPv6 space. It may be worth adding to the RIPE DB attribute in the object domain like this: dnsloc: yes
Emile Aben •
Thank you for your comment. The scanning is already done, so one just needs to pick out and select from that I think: https://scans.io/study/sonar.fdns There are efforts in the RIPE DB for better geoloc support: https://github.com/RIPE-NCC/whois/wiki/geolocation