
Last week I attended the Passive and Active Measurement (PAM) conference in Berlin. In this article I present some highlights and take-aways.
The conference name - PAM - may be a little cryptic if you don't know that it's about Internet measurements. In these circles, "active" means research is done by sending and receiving packets to investigate the Internet (ping, traceroute). RIPE Atlas is an example of an active measurements platform. "Passive" means investigating packets sent by others, for instance looking at packet captures.
Research meets operations
In an introductory presentation on behalf of the programme committee, Rob Beverly calculated the probability of a paper being accepted based on keywords appearing in the paper. The word 'the' had no predictive properties, but 'IPv6' and 'geolocation' had. While this was a tongue-in-cheek-type of presentation, the fact that there was attention on IPv6 and geolocation was, to my mind, a sign that the focus of this part of the Internet research community is quite in sync with the interests of network operators.
On the other hand it was quite disappointing to hear that, in a Q&A after a presentation, a researcher had to admit that their research didn't include an IPv6 component, because their institute got IPv6 only a few weeks ago.
Christian Kreibich gave a keynote about differences between academia and industry. A key take-away for me was his point about negativity in academia and how to get rid of it. During discussions it became apparent that there are many organisations and collaborations out there that are trying to bridge the gap between academia and industry. That was encouraging to hear and reinforces the importance of initiatives such as the RIPE Academic Cooperation Initiative (RACI), which brings academics into network operational meetings. An interesting term from Christian's keynote that I hadn't heard before was "data lake". I guess it's a sign of the times that, since we collect so much data now, much of it just sits in lakes sometimes.
Open Access, open science
It felt a bit anachronistic that there are still paper proceedings and USB sticks handed out. This is because the publisher behind the conference will eventually put the accepted papers behind a paywall. There is apparently an active discussion going on with the publisher Springer about how to move to open access papers. After looking at some of the papers from this conference, it looks like many are findable through google scholar and readable from the authors personal web-pages and/or things like Sci-Hub, which IMHO proves the point of the failed business model of putting publicly funded research behind commercial paywalls.
There are also models like ScholarlyHub that advocate open access and open science, that would be interesting to explore further.
Another noticeable development with regards to transparency and openness in research was that a surprising number of papers had code repositories on github: open data access and/or even the paper itself written such that it can directly be interacted with (see below). The goal is re-usability of research results, for instance: papers you can interact with or code that can be debugged and re-used by others.
Research highlights
The papers that were accepted were an interesting mix, all offering avenues of discovery for various aspects of the Internet. For network operations, the most interesting things were probably around layer3 and Interdomain routing, but there is also interesting research going on higher up the stack. I'll pick out a few of my favorites:
Characterising a meta-CDN
What I found refreshing from this research is that it really dug into the ecosystem of meta-CDNs; i.e. methods of using multiple CDN providers to deliver content (also called multiCDN), which has evolved rapidly in the last few years. This work drills down into the methods that multiCDN provider Cedexis offers, for instance how it is used in the wild. It also contains measurements indicating that roughly 200 domains out of the Alexa 1M use these services.

Number of domains using Cedexis out of the Alexa 1M list
In rDNS We Trust
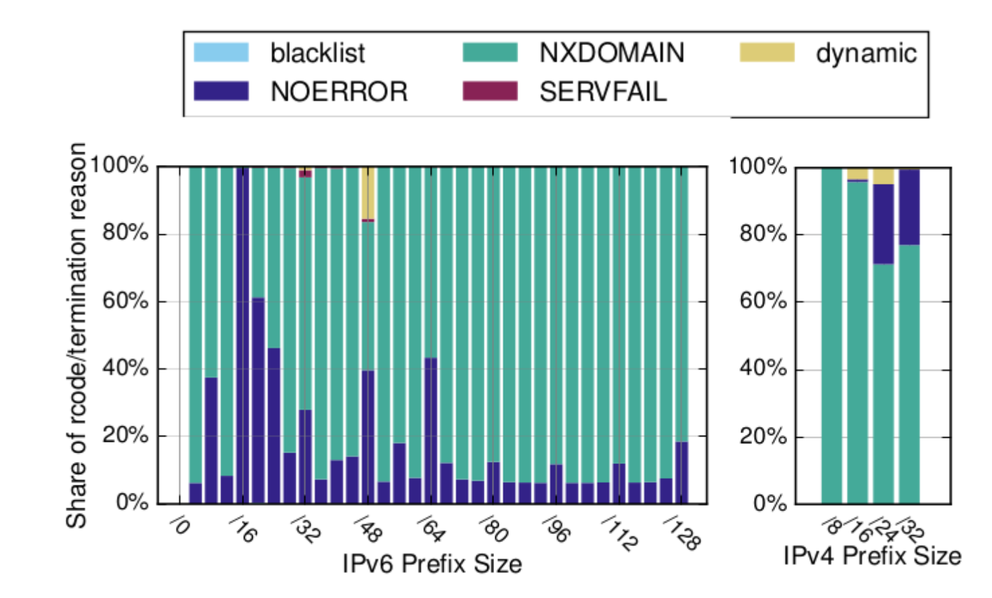
This research looks into the reliability of rDNS as a data source. What I found fascinating is the use of an old trick to walk the ip6.arpa tree. The results indicate that only a relatively small number of /32 and /48 IPv6 prefixes are not walkable automatically, indicating that people have been actively trying to block this or are dynamically generating names for all pieces of that IPv6 address space.

Figure 1: rcodes in active measurements
Exploiting SPF
This work is an interesting mix of network-research, security-research, protocol design and ethics. It explores how the SPF protocol (which can be used as a defence mechanism in the war-on-spam) can be used for DoS and network reconnaissance (specifically detection of otherwise hidden DNS resolvers). The problem is a minute difference between the intent of the protocol specification, and the way it was written down (i.e. a difference between the code of law, and intent of law). Because of this difference one can set up SPF records in such way that a mail server has to do a lot of DNS queries to "SPF resolve" a single email address. Details in the paper and presentation.
Revisiting the Privacy Implications of Two-Way Internet Latency Data
The privacy implications of Internet latency data, like RIPE Atlas, are important, not only for participants in measurement networks, but also for protocol specification in the IETF. This work looked at the privacy impact of Internet RTT information and concluded that it's not location sensitive when source IP addresses are known. There is an potential issue for the case when addresses are redacted and very low RTT (< ~10 ms), as well as a potential issue with inferring activity across an access link close to the measurement point.
A very nice feature of this work is that it's openly available on GitHub (paper and code). There is also a remote telemetry experiment that you can interact with.

Brian Trammell presenting about privacy implications of Internet latency data
Final thoughts
As for the data sources that researchers use, it is always good to see that both RIPE Atlas and RIPE RIS are solidly in the toolkit of researchers, and interesting observations about the Internet come out of research that was made possible using these infrastructures.
There was more interesting research published so if this eclectic summary leaves you thirsty for more, the PAM programme committee collected many of the presentations, available on this webpage.
And keep an eye out for a separate RIPE Labs post about a new way to estimate the reliance of an network on other networks. This work, called "AS Hegemony", was also presented at PAM.
Comments 1
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Alexander Isavnin •
Can you recommend other "Internet measurements" conferences? Which of them RIPE NCC will attend? (well, MAT at RIPE meeting is the best, could you recommend runners-up ;) )