
IP anycast is a popular way to scale up and distribute services across the Internet, with the aim of getting closer to end users. Using anycast, the IP address of a service is available in multiple places on the Internet — so-called anycast instances or sites — and Internet routing defines which instance of the service will reach users.
Root DNS nameservers, large CDNs and many ccTLD and gTLD DNS operators employ anycast strategies to achieve resilience, load-balancing and distribution of services.
However, blindly trusting the Internet routing system (BGP) brings uncertainty to the mapping between users and anycast instances, and this directly affects service performance (latency) and, hence, raises several questions: how many sites does my anycast service need to provide good latency? Could the latency observed by users be better? What has the greatest impact on latency: number of instances, or their local connectivity?
We sought to answer these questions in our recent study, the results of which we presented in our 2017 Passive and Active Measurement Conference paper, and which I’d like to share with you in this post.
Studying relationship between latency and anycast using RIPE Atlas
We studied the relationship between latency and anycast deployment of four Root DNS servers (C, F, K and L), and used more than 7,000 vantage points (VPs) worldwide from RIPE Atlas.
To determine the catchment (that is, the user to anycast site mapping), we used DNS CHAOS queries. Replies to these queries typically include a string that identifies the answering anycast instance.
We also measured the RTT between all VPs and each of the anycast instances of the Root letters we studied, to identify whether the catchment was optimal in terms of latency.
Latency across root servers is pretty good
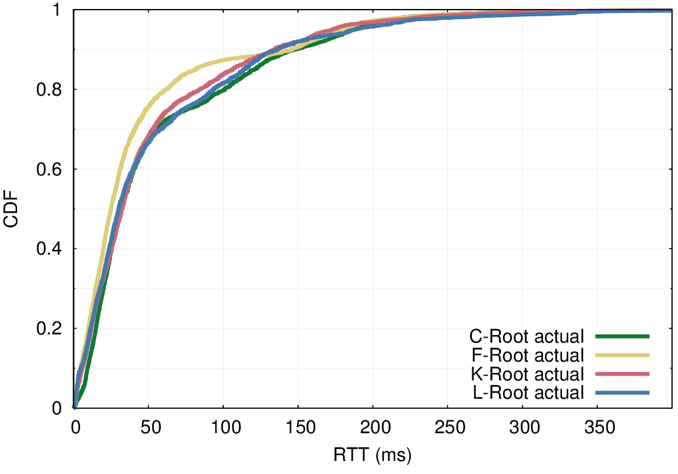
Overall median latency (RTT) to all root server is between 25 and 32 milliseconds (Figure 1), which is pretty good.

The similar latency across the studied letters is somewhat surprising, given that the size of anycast deployments are very different: from 8 anycast sites of C-Root, to 144 of L-Root (at the time of measurement).
This suggests that simply adding more sites to an anycast deployment does not necessarily improve overall latency of the service.
Triggered by the long tail of the latency distribution, we decided to investigate the locations of those vantage points that see higher latency.
Figure 2 shows the median, the 25th and 75th percentile of the latency distribution to L-root, and vantage points grouped per country. On the left side of the figure, among those countries with higher median RTT, we see that few VPs do experience low latency (as indicated by the lower 25th percentile).
This leads us to conclude that although geographic distribution does not necessarily mean a good network topological distribution, it can promote good network topological dispersion.

Routing policies remain a barrier to better latency
Another major barrier to better latency is routing policies.
Take the Philippines, for example. From the figure above, out of the 20 VPs, 7 are mapped to the L-Root instance located in the Philippines and, hence, we see a low latency to the service. The other 13 VPs, however, which are routed to Australia and to the USA, experience much higher latency.
Cases like these show that careful engineering of peering agreements and routing policies is needed to achieve good latency, in addition to the number of sites of an anycast service.
The answer is 12
Now, answering our main question, that of our work’s title.
After carefully studying four very different anycast deployments, we claim that 12 anycast sites would be enough for good overall latency. Two sites per continent, in well chosen and well connected locations, can provide good latency to most users.
While a greater number of sites may not necessarily improve overall latency, more sites do help with reducing the number of users that experience higher latency in badly connected networks/regions — especially if routing policies and peering are well tuned.
If you want to know more about our work, please read our paper.
Thanks to my research partners Ricardo Schmidt at the University of Twente, and John Heidemann from the ANT group at the University of Southern California/Information Sciences Institute.
This article was originally published on the APNIC blog.
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.