
In this article we will give some insights into the overall architecture of the RIPE Atlas network and how we manage secure communication with our probe flock.
Introduction
In the previous article RIPE Atlas Probes as IoT Devices we talked about the design principles we took into account when we started building the RIPE Atlas network. One very important aspect was security, and more specifically protecting the probe hosts.
In this article, we're going into details about the underlying architecture and the way we're ensuring secure communication between the various components.
RIPE Atlas architecture
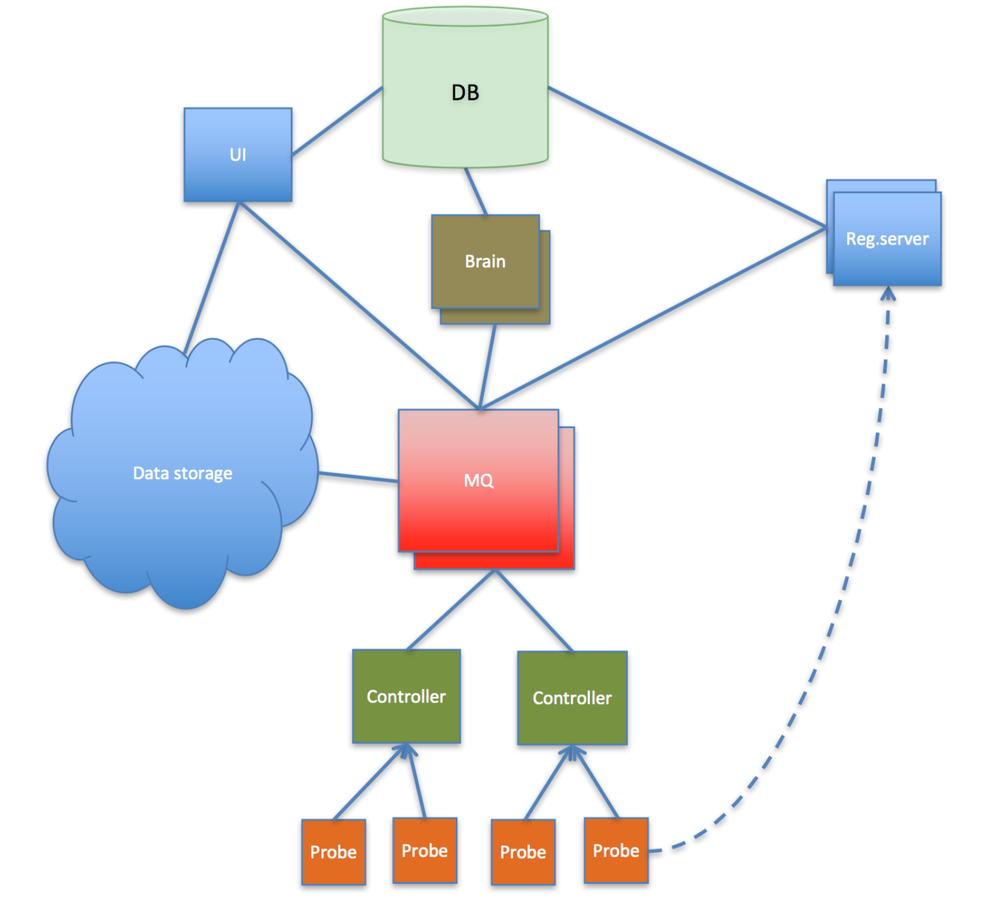
In the image below you can see a high-level overview of the RIPE Atlas infrastructure demonstrating how components are connected to each other:

Figure 1: High-level RIPE Atlas infrastructure (click on it to enlarge the image)
When probes connect to the network, they use the pre-installed trust anchor material (predefined keys and addresses) to our so-called "registration servers". After analysing the probe's geolocation, the current load on the various controllers and other parameters, they decide which "controller" to direct the probes to. The registration servers provide the key of the probe to the controller, and the key of the controller to the probe. Then the probe disconnects from the reg.server and connects to its assigned controller. This connection is maintained for as long as possible.
The controllers, just like many other components, keep contact with other components via a Message Queue cluster in an asynchronous fashion. This message queuing provides a large degree of flexibility to manage our distributed infrastructure; components can be added or removed without the need to synchronise the whole infrastructure. Also, each component (machine) can disconnect from the infrastructure temporarily: messages will be buffered at various levels until connection is restored.
RIPE Atlas probe generations
We have gone through three versions of RIPE Atlas probes and a fourth one is under development. RIPE Atlas anchors are part of the overall infrastructure.
RIPE Atlas v1 and v2 probe
The initial RIPE Atlas probes were custom made and based on the Lantronix XPortPro embedded device. The only difference between them is that the v2 has twice the memory v1 has: 16MB vs 8MB (yes, megabytes!). These devices had pros (e.g. very low power usage) and cons (e.g. long reboot times and the high production costs). There are still around 2,000 v1 and v2 functioning probes out there. They have certainly lived well beyond their expected life time.

Figure 2: RIPE Atlas v1 and v2 probes - with and without case
RIPE Atlas v3 probe
After using the v1 and v2 probes for about three years, we started looking for a new suitable device and found the TP-Link MR3020 that we equipped with a small USB stick. It is is a lot cheaper and faster than the v1 and v2 probes, since it's originally an off-the-self travel router produced in large quantity. Unfortunately we realised recently that the USB disk actually caused more issues than we had anticipated which ended in a temporary decrease of connected probes. Fortunately, this has mostly been resolved by new firmware. Nevertheless, we are now looking into brand new hardware that won't have these issues.
RIPE Atlas v4 probe
We are currently evaluating the NanoPi NEO Plus2. This looks promising, but we are still evaluating it and investigating the logistics: stability, power management, heat dissipation, procurement, casing, software lifecycle, etc.
Communication between probes and the infrastructure
As mentioned above, the probes connect to controllers where they try to keep a a connection active for as long as possible. This connection is used to report their measurement results back to the servers so they can be made available to others, but also to send commands -- i.e. measurements to execute -- to the probe. They also receive firmware updates from the RIPE Atlas infrastructure using these channels.
All communication happens using SSH with port forwardings in both directions. In addition to that individual SSH keys, session keys and allocated ports are used. It's interesting to note that we're using SSH over port 443 because we anticipated that this has a higher chance of success than using the "standard" port 22 assigned to SSH.
Figure 4 below shows how the communication channel is set up in our scenario.

Figure 4: Communication between RIPE Atlas probe and controller
We knew in advance that OpenSSH had good control over local port forwarding. However, restrictions on remote port forwarding is not implemented out-of-the-box for some reason, so we needed to add this.
A lot of work has been done in the field of bi-directional communication technology since we started RIPE Atlas. If we were to start to build the RIPE Atlas architecture today we would seriously consider using web sockets over HTTPS. However, at this point, it does not seem to provide enough benefits over our existing solution to make the change.
Probe security
Each probe uses an individual SSH key in order to authenticate itself and we can disable each probe separately if necessary, for example if there is evidence of tampering. Probes only perform active measurements as described above and can not listen to traffic. Probes do not provide any local services: there is no web server and no local configuration is possible, which limits the attack surface against probes significantly.
The local USB stick on the v3 devices is encrypted with individual probe keys which prevents local firmware attacks. When new firmware is available, probes update in a "lazy fashion": they learn about the new firmware and upgrade the next time they reconnect to the infrastructure, though we also have means to force them to upgrade faster if needed.
Each firmware upgrade is cryptographically verified: the firmwares are signed offline by our development team, and just before upgrading the probes verify this signature using pre-installed public keys. Version 1-3 probes can also upgrade their operating system this way. The RIPE NCC operations team manages the operating system and the probe firmware package of the RIPE Atlas anchors.
Responsible disclosure procedure
Despite all the precautions and the conscious security decision made by design, we all know that bad things can happen. It is important that these incidents get reported back to the RIPE NCC before they can be exploited by others. We provide a responsible disclosure procedure and we have received some such reports since our launch.
We also commission security audits of the entire RIPE Atlas infrastructure on a regular basis, looking at different aspects of our system every time.
Conclusion
It has been fun figuring out how to build such a system over the last seven years (!). Although there are other measurement networks out there besides RIPE Atlas, the unique features for each of these mean that there's no single best practice on how to build one -- which made the building of our system a very exciting experience. I'd like to take the opportunity and give credit to the whole RIPE Atlas development team for recognising and solving the difficult issues along the way!



Comments 2
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Milad Afshari •
Good job! and thanks for useful information.
Besmir Zanaj •
amazing job