

BGP Scanner from the Isolario project helped researchers analyse routing data, but it had its limitations. Overcoming these has led to the development of the Micro BGP Suite. It provides a variety of tools that, while each simple and efficient in their own operations, are capable of achieving complex results when combined.
It has been a few years since my colleagues and I at the Isolario project launched BGP Scanner to assist researchers with analysing increasing amounts of routing data in a reasonable time. This has continued to be a passion project of mine and has led me to develop the Micro BGP Suite project. In this post, I’ll discuss its evolution from BGP Scanner, its advantages, and possible uses.
From BGP Scanner to µbgpsuite
BGP Scanner proved to be a useful tool for many network analysis projects, including lib_bgp_data, to wade through the vast amount of MRT data provided by the multitude of benevolent route-collecting projects.
Much of its usefulness is owed to its powerful filtering engine and its easily parsable text output, which allow painless integration with larger data-processing workflows, and possibly scripting languages or external tools, by virtue of simple Unix-style output piping.
Despite this, BGP Scanner has some issues with its filtering capabilities mostly due to backwards compatibility concerns with its predecessor — MRT_data_reader.
This, among other reasons, motivated me to take a rather radical approach, and move the tool to a stand-alone project, rewriting the entire codebase from scratch, taking advantage of my past experience, and freeing myself from the burden of backwards compatibility.
The result of this choice is the Micro BGP Suite (µbgpsuite or ubgpsuite for short, depending on your keyboard proficiency with Greek).
So, How’s the Micro BGP Suite Better than BGP Scanner?
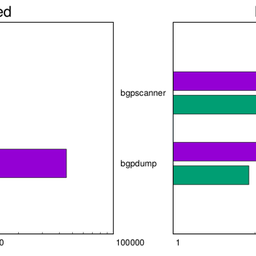
BGP Scanner had a tradition of being fast at what it did. The Micro BGP Suite continues this with recent benchmarks demonstrating that bgpgrep, the successor to the bgpscanner command within µbgpsuite, can deliver between 12% to 20% additional performance on a middle-end laptop.
There are more improvements within bgpgrep too, such as better compatibility with less common MRT dump formats and several bugfixes, which make it more reliable. But, by far, its new command line interface and filtering options vastly outshine any other achievement.
To illustrate, let’s put bgpgrep to use for a significant MRT data set. Assume we wish to find out how many bogon ASNs and bogon addresses appeared during July 2021.
First, we’ll lay down our study by fetching the relevant data from a route collecting project of our choice. In this case, we’ll use RIPE RIS RRC00. By taking the first RIB snapshot of the month and every subsequent update, we obtain 50GB worth of gzip-compressed MRT data (corresponding to about 646GB uncompressed).
$ du -hc rrc00/bview.*.gz | tail -n1 # RIB size
1.4G total
$ du -hc rrc00/updates.*.gz | tail -n1 # updates size
49G total
$ gzip -l rrc00/*.gz | \
awk '{ megs+=$2/1000000 } END { printf "%.2fG\n", megs/1000 }'
645.88GIt is relatively easy to use bgpgrep’s filtering option to find out whether a BGP message contains any bogon ASNs in its AS_PATH. However, it is harder to tell whether a bogon address is present, because bogon addresses change over time. Thankfully, Team Cymru provides an up-to-date list that we can use for our study.
The following script downloads the up-to-date full bogon address list from Team Cymru and adapts it with some sed-fu to generate a suitable filter list for bgpgrep; we’ll save it under our current directory with the name download-fullbogons.sh:
#!/bin/sh
# Be nice and only download bogons once a day.
if [ -f fullbogons.txt ] && [ $(find fullbogons.txt -mtime -1) ]; then
echo "Bogon address list already up to date."
exit 1
fi
# Generate updated bogon list
echo "Writing bogon list to: fullbogons.txt"
( wget -O - https://www.team-cymru.org/Services/Bogons/fullbogons-ipv4.txt
echo
wget -O - https://www.team-cymru.org/Services/Bogons/fullbogons-ipv6.txt
) | sed 's/#.*$//g' >fullbogons.txt
Our resulting directory layout is:
$ ls
download-fullbogons.sh
rrc00Now we are all set for our analysis. For ease of demonstration, we simply print the number of messages containing bogons:
$ sh ./download-fullbogons.sh
Writing bogon list to: fullbogons.txt
$ bgpgrep rrc00/*.gz \
-bogon-asn -or -subnet fullbogons.txt | \
grep -E '^+|^-|^=' | wc -l
1344411The bgpgrep command reads as follows:
For every gzip file in rrc00/, print each BGP message containing bogon ASN, or containing subnets of any prefix listed within fullbogons.txt.Results are piped to grep, which will leave only entries coming from announcements, withdrawals and RIB snapshots, respectively. Every line of output by bgpgrep is prefixed by a character identifying its nature:
- = snapshot
- + announcement
- – withdrawal
- # BGP state change
- …
Events unrelated to BGP updates aren’t subject to filtering rules and might cause miscounts in our analysis if left there. In the end, wc enters into play to count the total number of lines — bgpgrep produces one line of output for every BGP message or event. We choose to include withdrawals in our count; a slight alteration of the grep expression may easily restrict matching to announcements alone.
To dig further into our demonstration, let’s elaborate on this example and do some timing. What follows is not a benchmark, but rather a regular execution under a KDE Plasma session running various applications in the background (such as Firefox), on a middle-end laptop with the following configuration:
- CPU: Intel© Core™ i7-8565 @ 1.80GHz, 4 physical cores, (8 with hyperthreading)
- Memory: 16 GB RAM DDR4
- Hard disk: SAMSUNG MZALQ512HALU-000L1
- Kernel: Linux 5.10.62-1-lts SMP x86_64 GNU/Linux
This is an honest performance you might get analysing that amount of compressed data on a similar machine, under average load.
Timing of the example above:
$ time bgpgrep rrc00/*.gz \
-bogon-asn -or -subnet fullbogons.txt | \
grep -E '^+|^-|^=' | wc -l
1344411
real 59m0,248s
user 58m43,747s
sys 1m41,248sRestricting the match to the first seven days of July, note how the more restrictive the match, the faster the performance:
$ time bgpgrep rrc00/*.gz \
-timestamp ">=2021-07-01" -and -timestamp "<2021-07-08" \
-and \( -bogon-asn -or -subnet fullbogons.txt \) | \
grep -E '^+|^-|^=' | wc -l
273210
real 28m36,568s
user 28m14,241s
sys 1m9,260sObtaining a list of direct peers propagating the bogons:
$ time bgpgrep rrc00/*.gz \
-bogon-asn -or -subnet fullbogons.txt | \
grep -E '^+|^-|^=' | \
cut -f9 -d'|' | sort -u >peerlist.txt
real 49m15,492s
user 49m7,445s
sys 1m36,730This last example further relies on the bgpgrep output format always placing the peer address and ASN of each BGP message at the 9th field, thus making it trivial to extract and process it by itself. With more relaxed filtering specifications, performance is closer to the first experiment.
For reference, what follows is a gross estimate of the decompression overhead. We measure this by simply inflating all data to /dev/null. This serves to better grasp how much time bgpgrep has to pay to solely decompress its input — a necessary cost unless MRT data is decompressed in advance:
$ time zcat rrc00/*.gz >/dev/null
real 30m57,084s
user 29m38,916s
sys 0m36,911sTake a Dive Into the Suite
bgpgrep is a decent Swiss Army knife for quick and dirty network analysis on huge MRT data sets. Its flexible and intuitive filtering options, coupled with a convenient output format, go to great lengths to provide interoperability with other familiar command line tools and scripting languages.
The Micro BGP Suite strives to provide similar tools, essentially simple and efficient in their operations, capable of achieving complex results when combined. Clear task division and effective interoperation are encouraged, rather than hidden behind a wall of complexity. Such flexibility is key to overcoming unanticipated needs.
There is more where bgpgrep came from, including peerindex — see my post on The Micro BGP Suite.
If you want to know more, be sure to check out The DoubleFourteen Code Forge website and its git code repository.
This article was originally published over on the APNIC blog.
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.