
Why and how our open source web platform switched to a more responsive code delivery. And how this has already changed.
Planet 4 is the codename for the open software that powers Greenpeace websites, our own content management and engagement platform. It's a global project for the whole network of Greenpeace national and regional offices, developed following Open Source principles. Creating "in-house" expertise, sharing resources in a more efficient way, engaging with volunteers, enabling collaboration between different offices. And in the end building a better and more sustainable product.
At the end of April, Planet 4 switched from a (weekly-based) fixed deployment schedule to Continuous Delivery (CD), a software development methodology in which iterations are delivered frequently, without following a regular release schedule. While the final production deployment is manually triggered, the idea is that whenever new code is merged, it’s considered production-ready and a new release can be deployed.
Soon after switching to CD, we also switched to bi-weekly sprints, which seems to allow us to do bigger chunks of work than before and have the team be more focused.
Switching to Continuous Delivery helped us fix, test, respond, deliver and iterate faster. It also helped improve both development and the UAT (User Acceptance Testing) process. As we grow confidence in our testing and deployment process, our code quality is also improving. With this change we also got closer to the well-known Open Source principle: "Release early, release often".
What CD changed for Planet 4
- Responsiveness — With the previous, fixed release schedule, blocker issues had to wait a week to get to production sites. The team wants to better support the P4 community and respond quicker to stakeholders’ emergencies. Releasing increments as soon as they are ready is a good step in that direction.
- Code Quality — The team’s efforts to expand and improve automated tests and review processes gradually brought P4 to a point where the merged code is considered production-ready and deployable at any time. Continuous Delivery of increments brought in more tests and reviews, pushing the team to write better code. Better code means better product.
- Reliability — With more frequent releases, the number of actual code changes in each deployment decreases, making the discovery (and fix) of any problems easier and quicker. As before, the pipeline can automatically roll to a previous version if anything happens to fail.
- Faster contribution process — If supported by parallel services described in the Architecture of Participation (onboarding process, communication channels, github repo etc) Continuous Delivery enables quick integration of anyone willing to contribute at any point in time, for all magnitudes of work.
Challenges and mitigation
While Continuous Delivery was expected to bring in all the above-mentioned pros — and it did — it also brought some challenges as well:
- Confusing the community — A key part of shipping the increment into the product is making sure the impacted parties are aware of the change, and warned if such change has a critical impact. It’s easy to miss something, when upgrades are frequent, so we had to make sure the P4 community is involved and informed, but not spammed. The right mix of automated and manual communications, notifications in chats and Jira labels had to be found.
- Updating documentation — Frequent releases bring in frequent changes that can potentially affect the work of everyone working in P4, from admins to editors. We had to find the right way to document all changes at the right time. This was especially important for the tickets with the FLAG label (which critically impact the frontend or the content management experience).
- Aligning with contributors — At Planet 4, we want to leverage open-source contributions right within our Community Strategy. Incorporating work from the open source community while adapting to the CD process required us to pay close attention to make sure FLAG tickets do not end up in the github repo, in order not to miss announcing the community of any such important work that might suddenly appear as part of a release.
- Switching instant messaging (IM) channels — Shortly after our switch to CD and the two weeks sprint, the Greenpeace network transitioned to Slack. The challenge here was to implement the new instant messaging tool and make sure no one in the community got left behind or missed information.
Communication cycle
To make sure the P4 community is up to date and properly informed about relevant changes, the idea is to keep everyone informed with a mix of automated and manually crafted messages, supported by constantly updated documentation.
After a couple of trials (and errors :) , we got to the following solution:
- An automated message is sent via email and Slack whenever a deployment has started, with a list of what is being changed and a link to the P4 changelog.

- To inform the community what’s planned to be done on short, medium and long term, the P4 team sends a bi-weekly email roundup (after the sprint is planned). FLAG labelled tickets and future initiatives worth mentioning have a section on their own in the email.
- After the bi-weekly roundup, FLAG tickets are also shared in Slack, to make sure the community is not missing important information.

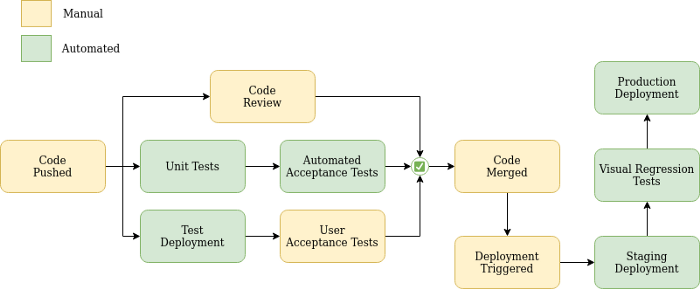
Development Cycle
In the Continuous Delivery scenario, each time a new Pull Request is created, automated tests and peer code review are immediately taking place. By using a test instance to deploy the change, the engineer in charge can ask other team members to verify it during User Acceptance Testing (UAT).

The P4 Git branching strategy also changed with Continuous Delivery. We were using Git-Flow, with two main branches (master, develop) and one for the next release. But that was replaced by Github-flow, where there is only one main branch (master), constantly updated with great quality code, ready to be deployed in production sites.

For UAT to take place before “merge”, a branch needs to be deployed on a test instance. We created a swarm of test instances that can be used by the engineering team to deploy the changes and a dashboard to show their availability in color coded way.

Finally, a new data sync automation was implemented in our CI, allowing us to sync these test instances with content from any production instance.
If your organisation is planning to or has completed the switch to Continuous Delivery as well, if you have any thoughts, questions or comments or just want to share anything related, please shout via email. Planet 4 is an Open Source project built with transparency in mind, and we welcome any contributions to our work.
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.