
When a senior engineer at FreeAgent, an accounting software provider, got a tweet about their servers running slowly, he turned to RIPE Atlas to help solve the problem.
The following article was written by Nathan Howard , a Senior Operations Engineer at FreeAgent. RIPE Labs would like to thank FreeAgent for allowing us to publish this article, which first appeared on their engineering blog, Grinding Gears . FreeAgent retains full copyright.
Last Monday evening we received this tweet:

Naturally we take anything like this seriously so we started digging. First stop was New Relic, which shows us average application and browser response times as well as a whole host of other useful metrics. Everthing looked normal. OK, time to hit the logs in search of any long-running requests.
We store all our logs in ElasticSearch , which we can search using Kibana . This combination has proved invaluable to us and once again it started to point us in the right direction.
While searching for all long-running requests, we noticed a few patterns. Firstly, that the long-running requests were only long-running on the load balancers and not the application servers. Secondly, that most of these long-running requests were from BT-owned IP addresses.
Then as suddenly as this started, it stopped. This isn’t the first time we’ve had issues with BT. Guess they had some incident which they resolved.
Along comes Tuesday evening and again:

Two disruptions in two nights, each lasting only a couple of hours. This was odd. I decided that if this was going to happen again, I wanted to be ready for it.
Let's rewind a few months. A friend of mine told me about the RIPE Atlas project and kindly gave me some credits to try it out. The RIPE NCC is trying to build the largest internet measurement network by giving probes away to people to host on their networks. In return for hosting a probe, you gain credits which can be used to query other probes.
The great thing about these probes is most of them are hosted on residential internet connections and not in data centres, which usually have lots of bandwidth and redundant links.
I applied for a probe and a few weeks later it arrived.

With users reporting problems which we believed to be network related, it was time to test this out.
I set up two measurements:
- Find 10 UK probes and ping our app every 5 min.
- Find 10 BT probes and ping our app every 5 min.
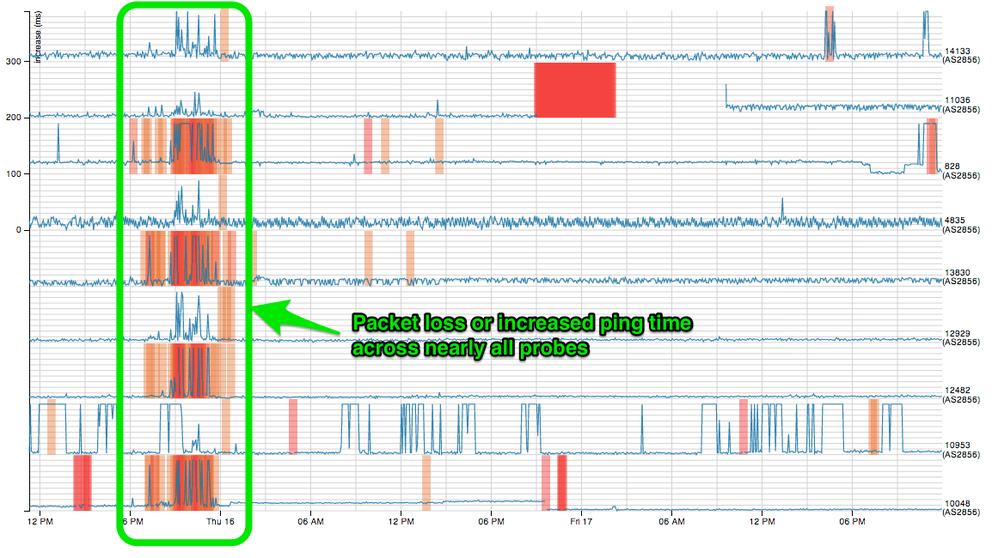
The results were interesting and confirmed exactly what we were seeing. The results from the UK-wide probes showed that only BT was having.


As it happens, the problem turned out not to be with BT at all but with a company our hosting provider has a BGP peering with. BT customers were favouring this route, which was flapping causing the packet loss and slowness our customers were seeing.
Of course we used other tools , which might be the subject of a future blog post, to find exactly where the problem was, but the RIPE Atlas project provided a lot of useful information.
Thankfully this issue is now resolved and we’ve been carefully monitoring it over the last week or so.
If you’re interested in this technology, you can help @RIPE_Atlas expand their network by hosting a probe for them.


Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.