
This is the second part of a research project investigating the possible replacement of the current Remote Route Collectors (RRC) used for the Routing Information Services (RIS). In the second phase we developed a prototype based on the requirements determined in the first phase. Both parts of this research project were done as part of my bachelor thesis at the Hogeschool van Amsterdam (HvA).
Note: The full bachelor thesis can be seen in Appendix A .
Introduction
In the previous article Researching Next Generation RIS Route Collectors , we listed the requirements for replacing the current RIS Route Collectors and presented possible solutions. Finally we decided to develop a prototype based on ExaBGP and to make it more scalable and modular. This prototype will allow us to check if all current requirements are met and if future requirements can be accommodated. The application should provide us with a stream of data and most of the pipeline should be event driven.
Brainstorming
Different applications should have access to the data and not be dependent on each other. Do we want to store the data somewhere? Should applications connect to the RRC and receive information? Or should we insert everything in a database? We liked the queueing concept, as you may have read in the previous article, and used RabbitMQ in this project. We also need to keep the MRT formatted files for backwards compatibility. As was outlined in the research stage, a separate application should maintain the RIB state. An application that provided us with this feature needed to be developed, as well as a library for creating the MRT formatted files.
Modular approach
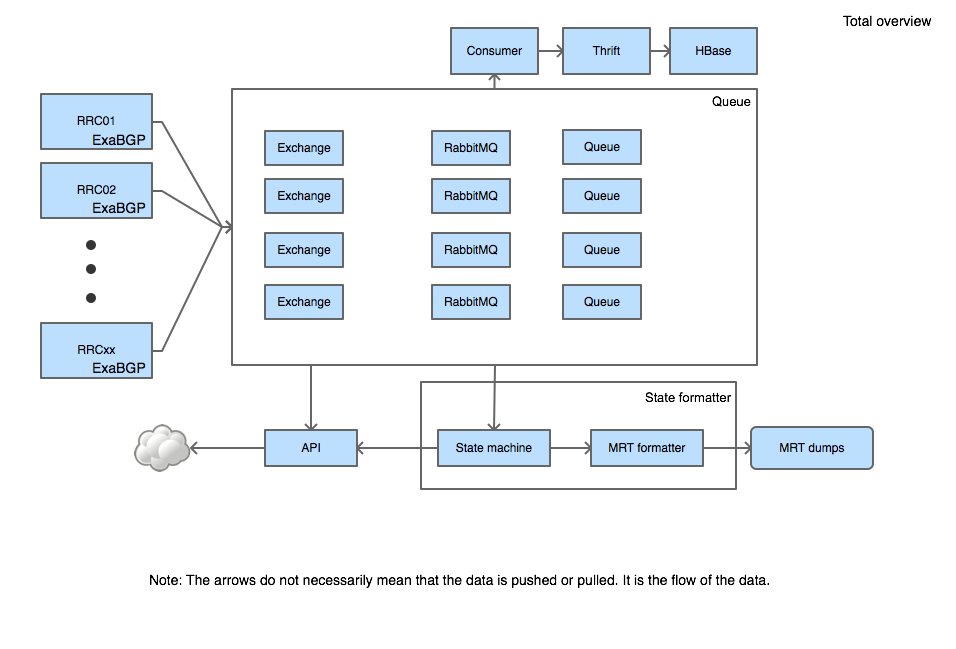
After the brainstorming sessions we wanted to create the prototype. This prototype had to be modular, so that future requirements can be met as well. This required to develop several applications that were pushing or pulling data to the queue. The main applications that we will talk about in this article are the producer, state machine and the HBase consumer.
The producer is an application that resides on the RRC and pushes data to the queue. On another machine we have the state machine, which is a separate application, and processes the data from the queue. It is independent in the sense that it is not directly connected with the RRC itself. The state machine uses the data that is produced by the RRC, but it uses the queue for getting the data. Finally, there is the HBase consumer, an application that consumes data from the queue, and inserts it in HBase.
Producer
ExaBGP can launch a helper application and sends it received data to that application. In the configuration file of ExaBGP you can specify the messages that the helper application is willing to receive. A helper application is in fact the application launched by ExaBGP that is willing to receive the messages from ExaBGP. In our case the producer is the helper application and sends the data it received from ExaBGP to a local queue. When the broker 1 can connect to one of the nodes in the cluster, it will relay the messages to the cluster itself. All the data is then made available on the RabbitMQ cluster, where different applications can consume the messages.
1 = In this context the term "broker"/"message broker" is used to indicate the application that takes care of the routing of the messages in the queue to the cluster. It also verifies if the messages have successfully been added to the cluster and connects to one of the nodes in the cluster.
State machine
The state machine is an independent application that processes the messages on the queuing cluster, maintains state, and creates the MRT formatted files. The MRT formatted files are used both by the community and the back end processing. The application reads from multiple queues, since you can launch multiple ExaBGP processes on one RRC and add these messages to different queues. You might wonder how we preserve the ordering reading from different queues.
We are certain that the messages in one queue are ordered. Ordering is important per neighbour and since we only connect to a neighbour once we are assured that the messages that are saved in the queue are ordered.
The state machine is configured to periodically dump the MRT formatted files. It therefore has a 'maximum allowed timestamp' built in, which is used to compare the timestamps of the ExaBGP messages with the 'maximum allowed timestamp'. If the state machine receives a messages here the timestamp exceeded the 'maximum allowed timestamp' we stop reading from that queue. When there are no queues left to read from we start creating the MRT formatted files.
HBase consumer
There is also the HBase consumer, which was developed to test the possibility of inserting the messages directly in HBase. It's not really an advanced application, since it only reads from one of the queues. This also has performance benefits, since the application’s sole purpose is to pull the messages from the queue and insert it in HBase.
The idea behind building this application was to see if it was feasible to develop such an integration between HBase and ExaBGP. It could allow for certain use cases where RIPEstat applications directly use 'fresh' information that resides in HBase. However, this requires the applications to use data that is differently formatted than the data is now. It would require more work to standardise the data format and the way the applications utilise the data (which was out of scope for this project).
Extensibility
The most important aspect of the new RRC implementation was that is should be scalable and be built in a modular fashion. When you look at the previous sections, you can see that the applications were all built with modularity and scalability kept in mind. The queuing cluster can be expanded, you can launch multiple ExaBGP processes each connecting to a subset of the neighbours, and the queuing setup allows for extensibility.
For example, if there is an API that provides access to the data in the queue, we need to couple the API with the queues on the queueing cluster. It is a matter of creating one extra queue and modify the exchanges accordingly.
The image below shows how the appl ations are connected with each other and how the applications rely on each other. It also shows the queuing cluster where the messages are temporarily stored unill they are pulled by the consumers (you can enlarge the image by clicking on it).

Next steps
The prototype needs to be thoroughly tested before it can be used in production. Some tests have already been done with some promising results. However, the back-end system would have to be moved from a batch oriented process to a more stream oriented process. This will take time, but since the state machine creates the MRT formatted files, it is still possible to use the legacy system, which allows to work on the new system at the same time.
Acknowledgements
I want to especially thank Thomas Mangin from Exa Network, the main developer of ExaBGP. During my internship at the RIPE NCC I received some great help from Thomas and he was willing to include some of the changes I made to the code of ExaBGP. He also implemented some of the feature requests himself and had intense contact during testing. It's definitely worth taking a look at the ExaBGP project: https://github.com/Exa-Networks/exabgp .
Also see Thomas’s article on RIPE Labs: ExaBPGP – A new Tool to Interact with BGP
Appendix A
Bachelor Thesis by Wouter Miltenburg: Replacement of RIS Route Collectors
Comments 2
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Tim Kleefass •
Hi there, the link to the Bachelor Thesis returns an redirecting loop for me :/
Mirjam Kühne •
Hi Tim, thanks for letting us know. Should work now. Sorry about that.