
We introduce a new tool to read BGP RIB dump files, called BGPdump2. It has a unique feature, in which users can compare routes from BGP RIB files in the ”diff”-like display format. It is good for checking the correctness of BGP operation by comparing one ISP’s BGP routing table to another ISP’s.
Introduction
BGP is highly dynamic and complex. There’s no single correct state of the BGP routing table; no-one can tell what shape of the BGP full-route routing table is correct, or sufficient, to reach out to the whole Internet, because it's different for every BGP speaker's point of view. Consequently, if a route is missing from the routing table, it can only be found on a case-by-case basis for each IP prefix individually, and it's mostly found by users who wanted to communicate with that network, but couldn’t. Is there a way to confirm to ourselves that our BGP routes are sufficient, rather than having to depend on user complaints ?
A diff-like function of two BGP routing tables is helpful, because it adds some additional information that can contribute to BGP route debugging. BGPdump2 can compare the prefixes listed in our routing table with those listed in someone else’s routing table and can show us the differences, i.e. routes possibly missing in our BGP routing table or possibly missing in theirs. Your next reaction might be: ”But hey, those prefixes are covered by a shorter prefix so that the reachability itself is maintained, aren’t they?”. In order to answer this, BGPdump2 contains a feature to construct a routing table inside the command instance, and to do the longest match routing lookup. Reachability is indeed missing, when the loaded routing table returned a ”route not found” message.
BGPdump2 is written from scratch, in about 4,000 lines of C. It supports bzip2 and gzip compressed MRT TABLE DUMP V2 format, for both in IPv4 and IPv6, as defined in RFC 6396 . It does not yet support the update message format.
In the rest of this blog post, we briefly talk about the speed of BGPdump2, how it ”diff”s two BGP routing tables, and the experiences we’ve made so far with the tool. In the reference section below you can find the GitHub page of BGPdump2 and the presentation slides given during the recent GROW working group meeting at IETF 92.
Speed
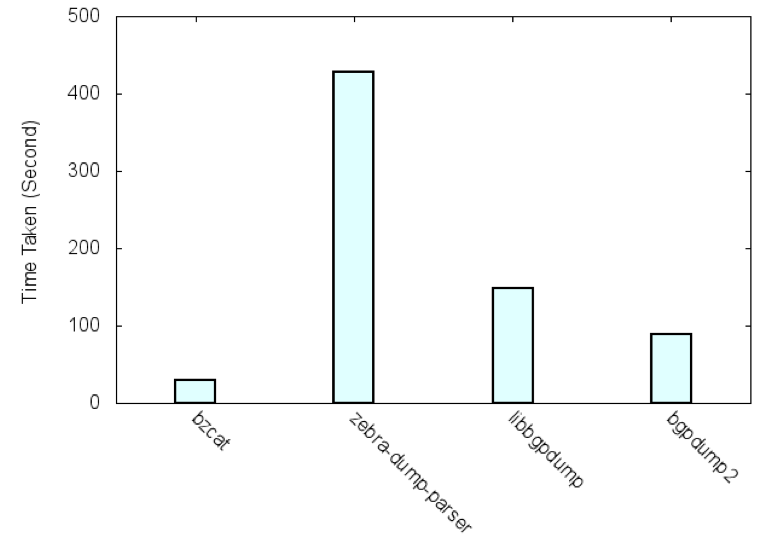
We evaluated the speed of BGPdump2 against Zebra-dump-parser and Libbgpdump, on MacBook Pro with 4-core Intel Core i7 2.3 GHz, 16 GB of memory, and SSD (Retina, 15-inch, Late 2013). The RIB file, rib.20150319.0000.bz2, is obtained from route-views2.oregon-ix.net of RouteViews Project . It took 28.98 seconds (real time by time command) for the bzcat command to process the RIB file, when all the outputs are redirected to /dev/null (this is also done for all the subsequent tests). We can think of the value as the lower bound, for our case of accessing the RouteViews file, since we need to decompress the bzip2 compression anyway.
Zebra-dump-parser, written in Perl (commit e6a64611c73ea71db2a51731), ran in 428.29 seconds. Libbgpdump (1.4.99.11) ran in 148.71 seconds. BGPdump2 (commit 35bc915619c66a6083d8329f) ran in 89.09 seconds. This is illustrated in Figure 1. We attribute the better performance of BGPdump2 to the buffer management; BGPdump2 prepares a relatively larger buf (default 16MB) and reads up to the end of the buffer. It uses a smaller number of read() function calls (thus has a smaller overhead) compared to the small-sized frequent reads of Libbgpdump.

Comparing Two BGP Route Tables with Longest Matching Lookup
BGPdump2 can show the difference between two routing tables by specifying the ’-u -p <peer-id> -p <peer-id>’ command. It can also construct a routing table inside its process instance by using the ’-r’ flag. All together, one can obtain the diff-like output in conjunction with the result of the longest matching lookup. Let's define the peer-IDs specified as the first and the second in the command line as ”left” and ”right” peers.
The newer marks in the diff-like output are explained in Table 1. This format is immediately understandable to anyone who has used the POSIX "diff" command and its various variants. It is easy to use this format to automate updates to historical data, maintain delta files, edit files and so on, using standard UNIX tools such as 'grep', 'sort', and 'uniq'.
| < | The prefix exists only in the left peer’s table, and is not reachable in the right peer’s table. It may become reachable partially, depending on the later processing. |
| - | The prefix exists only in the left peer’s table, but it is also reachable in the right peer’s table, because it is covered by a shorter (less-specific) prefix. |
| ( | The prefix is in the left peer’s table, and is covered by a shorter prefix in the right peer that is unreachable in the left peer (i.e., the shorter prefix is ’>’). This indicates that the prefix is the recovery of the partial reachability, in a larger missing reachability, compared to the other peer. |
| > | The opposite of ’<’. |
| + | The opposite of ’−’. |
| ) | The opposite of ’(’. |
Table 1: Marks in the diff-like output
For example, Figure 2 shows the sample output of ’diff’-ing the BGP tables of Level3 (peer 3) and NTT Communications (peer 19). 88.87.160.0/19 propagates to Level3 and NTT Communications differently, such that Level3 shows just one single /19 prefix, while NTT Communications lists four /21 prefixes. It shows that both ISPs maintain full reachability to the /19, but in a different way.
% ./bgpdump2/src/bgpdump2 ./routeviews/oregon-ix2/rib.20150319.0000.bz2 -u -r
-p 3 -p 19
:
<88.87.160.0/19 4.69.184.193 origin_as: 47680 as-path[8]: 3356 1299 5580 47680
47680 47680 47680 47680
)88.87.160.0/21 129.250.0.11 origin_as: 47680 as-path[7]: 2914 5580 47680 4768
0 47680 47680 47680
)88.87.168.0/21 129.250.0.11 origin_as: 47680 as-path[7]: 2914 5580 47680 4768
0 47680 47680 47680
)88.87.176.0/21 129.250.0.11 origin_as: 47680 as-path[7]: 2914 5580 47680 4768
0 47680 47680 47680
)88.87.184.0/21 129.250.0.11 origin_as: 47680 as-path[7]: 2914 5580 47680 4768
0 47680 47680 47680
:
Figure 2: Comparing two BGP route tables
Note that BGPdump2 assumes that the prefixes in the RIB dump file are sorted in advance (i.e., the prefixes in the file are assumed to appear in the sequence of preorder traversal of depth first search). If the RIB dump is not sorted, BGPdump2’s diff-like function may not work properly. Even though the MRT format specification does not seem to require so, current implementations to produce the RIB dump file (such as Quagga ) typically store prefixes sorted in the output.
Finding Missing Routes
We listed the missing routes in NTT’s routing table by performing the following steps:
The target RIB file is the same with the previous one (rib.20150319.0000.bz2) that is made public in the RouteViews as the snapshot of 2015-03-19 00:00. There were 58 peers in the RIB file, and 39 of them had more than 500,000 routes (these 39 peers are considered to have the BGP full routes). On this RIB file, we issued BGPdump2’s diff-like comparison with the longest-match lookup, comparing NTT’s table (peer 19, as the "left" peer) against all peers (as the "right" peer), producing 58 diff files. By extracting the ’>’ mark from the diff files using 'grep', we obtained the missing routes in NTT’s routing table. (Note that, for simplicity, we ignored all partial (more specific) prefixes in NTT’s table. In other words, we ignored all routes with ’(’ marks). Using ’sort | uniq -c’ among the extracted routes from all the diff files, we could check a degree of severity per prefixes, because the resulting count indicates the number of other ISPs that hold the prefix. For example, the count 38 means that all other ISPs with BGP full routes have that prefix, while only the NTT does not. There were 251 such routes.
Another way to summarise the missing routes is to collect them by the organisation name. We queried the ”riswhois.ripe.net” whois server and resolved the description for each prefix. If we count the number of unique occurrence of each description, we can count the number of missing prefixes for each organisation. There were 534 unique descriptions for the prefixes, and there were 180 prefixes without a description. The first and second in the prefix count ranking appear with 88 and 60 prefixes missing in NTT’s routing table. This kind of information is helpful in debugging the BGP routes; we have just started some of the debugging work.
Conclusion and Future Work
We have developed a tool called BGPdump2, that is useful for checking the BGP route table status from a variety of perspectives. We can find the triggers for the BGP route debugging, such as the IP prefix that is missing, and the organisation's name (description) that seems to originate many missing prefixes.
There are two ways to proceed further with this; in a micro- and a macroscopic way. In a microscopic way we can trace it down for each IP prefix to the detail, debugging how and why the prefix is missing. In a macroscopic way we can provide an overview of the dynamic and complex status of the BGP routing table (and hence the Internet topology), by checking the statistics of BGP routes and ASes, apart from the individual cases.
We will work on continuing development of the software.
Yasuhiro will present this tool at the routing working group session at RIPE 70 .
Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Blake Willis •
you might be able to squeeze a little more performance out of it by switching the compression format from bz2 to xz e.g. http://catchchallenger.first-world.info//wiki/Quick_Benchmark:_Gzip_vs_Bzip2_vs_LZMA_vs_XZ_vs_LZ4_vs_LZO
Yasuhiro Ohara •
Thanks. As far as decompression time is concerned, still gzip exhibits a good performance. Interesting.
Julian M. Del Fiore •
Hi, very useful tool! One question...it says that "It does not yet support the update message format."...I see that this is still like that. Are there any plans of implementing this too?...thanks!