
tdns is part of the 'hello-dns' effort to provide a good entry point into DNS. tdns is small enough to read in one sitting and shows how DNS packets are parsed and generated.
tdns is part of the 'hello-dns' effort to provide a good entry point into DNS. This project was started with my 'DNS Camel' presentation at the IETF 101 in London in which I showed that DNS standards have now grown to 2,500 pages, and that we can no longer expect new entrants to the field to read all that. After 30 years, DNS deserves a fresh explanation and hello-dns is an attempt to do just that.
Even though the 'hello-dns' documentation describes how basic DNS works, and how an authoritative server should function, nothing quite says how to do things like actual running code. tdns is small enough to read in one sitting and shows how DNS packets are parsed and generated. tdns is currently written in C++ 2014, and is MIT licensed. Reimplementations in other languages are highly welcome, as these may be more accessible to programmers not fluent in C++.
The goals of tdns are:
- Show the DNS algorithms 'in code'
- Implement protocol correctness, except where the protocol needs updating
- Be suitable for educational purposes
- Display best practices, both in DNS and security
- Be a living warning for how hard it is to write a nameserver correctly
The target audience of tdns is anyone thinking about implementing, or actually implementing an authoritative nameserver or a stub resolver.
Non-goals are:
- Performance (beyond 100kqps)
- Implementing more features (unless very educational)
- DNSSEC (for now)
Besides being 'teachable', tdns could actually be useful if you need a 4-file dependency-light library that can look up DNS things for you.
Features
Despite being very small, tdns covers a lot of ground, implementing all parts of 'basic DNS' (as defined by the 'hello-dns' pages):
- A, AAAA, CNAME, MX, NS, PTR, SOA, NAPTR, SRV, TXT, “Unknown”
- UDP & TCP
- Empty non-terminals
- AXFR (incoming and outgoing)
- Wildcards
- Delegations
- Glue records
- Truncation
- Compression / Decompression
As a bonus:
- EDNS (buffer size, flags, extended RCode, no options)
What this means is that with tdns, you can actually host your domain name, or even slave it from another master server.
What makes tdns different?
There is no shortage of nameservers. In fact, there is an embarrassing richness of very good ones out there already. So why bother? The biggest problem with DNS today is not the great open source implementations. It is the absolutely dreadful stuff we find in appliances, modems, load balancers, CDNs, CPEs and routers.
The DNS community frequently laments how much work our resolvers have to do to work around broken implementations. In fact, we are so fed up with this that ISC, NLNetLabs, CZNIC and PowerDNS together have announced that starting in 2019 we will no longer work around certain classes of breakage.
In addition, with the advent of such RFCs as RFC 8020, sending incorrect answers will start wiping out your domain name.
However, we can't put the all of the blame for disappointing quality on the embedded and closed source implementation community. It was indeed frighteningly hard to find out how to write a correct authoritative nameserver.
Existing open source nameservers are all highly optimised and/or have decades of operational expertise (and trauma) worked into their code. What this means is that actually reading that code to learn about DNS is not easy. Receiving and answering millions of queries per second does not leave the luxury of keeping code in an accessible or educational state.
tdns addresses this gap by being a 1600 line long server that is well documented and commented. Any competent programmer can read the entire source code in a few hours and find out how things should be done.
That sounds like hubris
In a sense, this is by design. tdns attempts to do everything not only correctly but also in a best practice fashion. It wants to be an excellent nameserver that is fully compliant to all relevant standards and DNS operational lore.
I hope that the DNS community will rally to this cause and pore over the tdns source code to spot everything that could potentially be wrong or could be done better.
In other words, where tdns is currently not right, we hope that with sufficient attention it soon will be. Bikeshed away! Some great words on bikeshedding and "cameling" may be found in Geoff Huston's excellent post 'Stuffing the camel into the bikeshed'.
How did all those features fit in ~1600 lines?
Key to a good DNS implementation is having a faithful DNS storage model, with the correct kind of objects in them.
Over the decades, many nameservers have started out with an incorrect storage model, leading to pain later on with empty non-terminals, case sensitivity, setting the 'AA' bit on glue (or not) and eventually DNSSEC ordering problems.
When storing DNS as a tree, as described in RFC 1034, a lot of things go right “automatically”. When DNS Names are a fundamental type composed out of DNS Labels with the correct case-insensitive equivalence and identity rules, lots of problems can never happen. Tonnes of conversion mechanics would not need to be typed in (or forgotten in some places).
The core of tdns therefore is the tree of nodes as intended in RFC 1034, containing DNS native objects like DNSLabels and DNSNames. These get escaping, case sensitivity and binary correctness right 'automatically'.
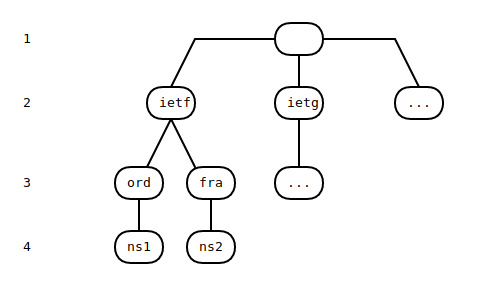
The DNS Tree
Of specific importance is the DNS Tree as described in RFC 1034. Because DNS is never shown to us as a tree, and in fact is usually presented as a flat 'zone file', it is easy to ignore the tree-like nature of the DNS.

To find nodes within the DNS tree, start matching from the top. This zone is called org, so at depth 4 we can find ns1.ord.ietf.org, after first matching nodes called ietf, ord and finally ns1.
If this tree is embraced, it turns out that a nameserver can use the very same tree implementation three times:
- To find the most specific zone to be serving answers from
- To traverse that zone to find the correct answers or delegation
- To implement DNS name compression
By reusing the same logic three times, there is less code to type and less to explain.
Interestingly, when asked (via Paul Vixie), Paul Mockapetris indicated he was surprised that the DNS Tree could in fact be reused for DNS name compression. This 2018 discovery in a protocol developed in 1985 turns out to work surprisingly well!
Putting the tricky bits at a fundamental level
DNS names look surprisingly like text strings, but they very much are not. For starters, DNS is case insensitive in its own special way, and such rules must be obeyed for DNSSEC to work.
Furthermore, despite appearances, DNS is 8-bit safe. This means that individual DNS labels (usually separated by dots) can contain embedded 0 characters, but also actual dots themselves.
A lot of code 'up the stack' can be simplified by having basic types that are fully DNS native, like DNS Labels which are case insensitive, stored in binary and length limited by themselves.
Code that uses “strings” for DNS may struggle to recognise (in all places!) that www.PowerDNS.COM, www.powerdns.com, www.p\079werdns.com. and www.p\111werdns.com are all equivalent, but that www\046powerdns.com is not.
The inner symmetry of DNS
In what is likely not an accident, all known DNS record types are laid out exactly the same in the packet as in the zone file. So in other words the well known SOA record looks like this on our screen:
ripe.net. SOA manus.authdns.ripe.net. dns.ripe.net. 1523965801 3600 600 864000 300
# mname rname serial ref ret exp minAnd in the packet, this very same record looks like this:

DNS Records need to be:
- Parsed from a message
- Serialised to a message
- Parsed from zone file format
- Emitted in zone file format.
It turns out these four conversions exhibit complete symmetry for all regular DNS resource types.
This means we can define one conversion 'operator':
void SOAGen::doConv(auto& x)
{
x.xfrName(d_mname); x.xfrName(d_rname);
x.xfrUInt32(d_serial); x.xfrUInt32(d_refresh);
x.xfrUInt32(d_retry); x.xfrUInt32(d_expire);
x.xfrUInt32(d_minimum);
}And actually reuse that for all four cases:
SOAGen::SOAGen(DNSMessageReader& dmr) { doConv(dmr); }
void SOAGen::toMessage(DNSMessageWriter& dmw) { doConv(dmw); }
SOAGen::SOAGen(StringReader& sr) { doConv(sr); }
std::string SOAGen::toString()
{
StringBuilder sb;
doConv(sb);
return sb.d_string;
}
Exploiting this symmetry does not only save a lot of typing, it also saves us from potential inconsistencies.
Next steps
It is my hope that tdns is educational and will lead to a better understanding of DNS. tdns is not yet done and we anxiously await comments from the rest of the DNS community, as well as reimplementations in other languages (like Go and Rust).
tdns is described more fully in its README. In addition, the code is richly commented with Doxygen annotations, which can be seen here. The code itself meanwhile is on GitHub.
Enjoy!


Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Daniel •
I'm a bit confused. Bert Hubert, shareholder of Open-Xchange, the parent company of PowerDNS is fed up with PowerDNS behavior around EDNS workarounds removal. Why is this not solved within Open-Xchange?
bert hubert •
Hi Daniel - I think you may be confused about what I said, maybe because I did not explain it very well? The open source nameservers do EDNS correctly and will also try to work around other servers not supporting it correctly. The open source resolvers together have decided to stop working on such workarounds per February 2019. So this is not a problem we can solve internally - the rest of the world has to clean up its act.
Job Snijders •
I think you may misunderstand. Bert, PowerDNS, and various other Open Source projects are fed up with having to maintain workarounds for some poorly constructed EDNS implementations. As a result, this is being resolved, by removing those workarounds: https://blog.powerdns.com/2018/03/22/removing-edns-workarounds/