

At the recent RIPE 61 meeting in Rome and at earlier meetings, we heard that connectivity over 6to4 is not very dependable, which hampers IPv6 deployment. I wondered how bad it really is and started measuring it. This article describes what I measured and shows the results. Spoiler: It's pretty bad.
Introduction
In the transition from IPv4 to IPv6, the preferred solutions for network endpoints is to have both, native IPv4 and IPv6 connectivity (i.e. dual-stack). If a site cannot get native IPv6 connectivity, the IPv4 network endpoints can chose from a number of conversion technologies to connect to the IPv6 Internet. Our IPv6 measurements at end-users and DNS resolvers suggest that the most commonly used conversion technologies are: 6to4 , Teredo , and tunnel-brokers . At RIPE 61 and previous RIPE meetings we heard that 6to4 connectivity is quite often broken. We were interested to find out how broken it really is.
Measurement Results
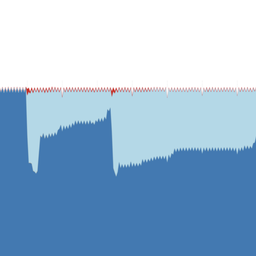
In Figure 1 below you can see the percentage of 6to4 connections to dual-stack and IPv6-only objects on our measurement webserver that fail, binned per day. See footnote [1] for the methodology of these measurements.

Figure 1: Failure rate of 6to4 connections over time
As our measurements only count failures on the return path (as we cannot see packets that don't arrive at our measurement machine), the real failure rate will be even higher. As you can see from the graph, the failure rate we measured is quite significant (around 15%). A weekday-weekend pattern is also clearly visible.
| Day | Failure rate |
|---|---|
| Monday | 15.5% |
| Tuesday | 14.7% |
| Wednesday | 18.6% |
| Thursday | 16.3% |
| Friday | 20.0% |
| Saturday | 9.2% |
| Sunday | 9.8% |
Table 1: Failure rate of 6to4 connections per weekday
In Table 1 we zoomed in to the weekday-weekend pattern, which shows a failure rate on weekdays of 15-20%, whereas in the weekend it drops down to a little under 10%. This drop in the weekend could be caused by lower Internet use from corporate sites during the weekend. We expect corporate sites to do more filtering on 6to4 packets (by corporate 'stateful' firewalls) on the return-path.
Table 2 shows a categorisation of the types of 6to4 nodes that try to connect to our measurement site and the associated failure rates. This categorisation is based on the last 64 bits of the IPv6 address. The table shows that 6to4 implementations that use the embedded IPv4 address as the last 32 bits of the IPv6 address (e.g. 2002:a:1::a:1) are the major part of 6to4 connections we see, and also have the highest failure rate. Close to 15% of failures we see is likely due to the rogue RA-problem that is described in Tore Anderson's RIPE 61 presentation .
| 6to4 Node Type | Failure rate | Likely Cause |
|---|---|---|
| EUI64 (7.4% of connections) | 4.7% | (rogue) RA |
| Privacy extentions (8.1% of connections) | 9.7% | (rogue) RA |
| Embedded IPv4 repeated in last 32 bits (84.4% of connections) | 15.8% | Machine local 6to4 (likely Windows) |
| 2002:XXXX:XXXX:1::1 (0.18% of connections) | 29.3% | Machine local 6to4 (likely Mac OS X) |
Table 2: 6to4 failure rates per 6to4 node type
Conclusion
The 6to4-brokenness we measured is quite significant, as all stories about 6to4 already indicated, so the "6to4 must die"-sentiment we picked up during the RIPE 61 meeting is understandable.
Content providers will not be affected much by the 6to4 breakage we see, as long as operating systems and applications prefer native IPv4 over auto-tunneled IPv6 (6to4,Teredo) by default, and as long as they prefer native IPv6 over everything else. Luckily, with the latest fix to Mac OS X (10.6.5), all major operating systems behave the way it is described above. As Mac OS users upgrade to 10.6.5 or newer, there is hope that overzealous use of 6to4 by end users will eventually cease to be a major concern for content providers that want to go dual-stack . Keep an eye on Tore's breakage stats .
With the free IPv4 address pool depleting, we expect IPv6-only content to appear in the near future. For these content providers the situation is not pretty. IPv4-only users that want to reach their content will have to face the significant 6to4 breakage we measured.
For hardware vendors it makes a lot of sense to make products not enable 6to4 by default , otherwise users of their products will have to face 6to4 breakage by default.
How much access providers and end-users will feel the 6to4 breakage depends on the situation. Using the latest versions of operating systems, the effect should be minimal as long as the content is IPv4-only or dual-stack. For IPv6-only content it really matters if the access provider is IPv4-only or dual-stack. If the access provider has not upgraded to dual-stack yet, its IPv4-only customers will have to use a technology like 6to4, and face breakage. This may cause customers to switch provider (which paradoxically will help IPv6 deployment).
Moral of the story: Go dual-stack. Now.
Footnote:
[1] Methodology: A description of the measurement setup can be found in this earlier RIPE Labs article: Measuring IPv6 at Web Clients and Caching Resolvers (Part 3: Methodology) . The measurements are made to objects that are either available over IPv4-only, dual-stack, and IPv6-only. On 11 May 2010 we started to keep tcpdump-trace files of traffic to and from 2002::/16. From these traces we determined the number of 6to4 connection attempts by looking for TCP SYN packets. We view a connection as successful if we see at least 1 data packet in the connection, i.e. a packet without SYN-flags. For our measurement setup we are not running a 6to4 relay ourselves, but rely on upstream providers to provide 6to4 for the return-path. We've seen traceroutes to 2002::1 from our measurement machine land in Surfnet's network, and we have not seen signs of outages in their 6to4-service in our measurements. So not running a 6to4 relay ourselves should not affect these measurements significantly.
Comments 17
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Anonymous •
(as this is not yet proven, please be careful when trying)<br /><br />As far as the content side is concerned, some people do believe that placing a 6to4 relay near your stuff might help. At least by doing so you have more control over the return path as the traffic will leave your network as IPv4 and you no longer depend on anycast and a 3rd party to handle the conversion for you.<br /><br />Some people even argue the best solution is to activate 6to4 on the webserver itself, making 2002::/16 a local route and have it hit the wire as IPv4.<br /><br />Now I think the big question is, could you measure the difference by doing this trick on some of the targets ?
Anonymous •
Marco,<br /><br />Clearly, ensuring that you have a working return relay close to the content will help ensure there's no trampolines, packet loss, or in general degraded performance. However, if you run it on the web server itself, on another router in the same data centre, or even if it is operated by a third party operator in the same city/geographic region (provided that you can trust the third party to maintain the relay well and ensure it's not overloaded), won't make much of a difference.<br /><br />There's one thing you need to make sure of when setting up your own return relay (even if it's on a dedicated machine, as a service on an existing router, or on the web servers itself), and that is that the outbound IPv4 packets must have an IPv4 source address of 192.88.99.1. The 6to4 standard doesn't mandate this, as far as I know, but in practise you might run into problems with stateful firewalls that look at the (src,dst,ipproto) triple in order to identify «established» flows. By using any other IPv4 source address than 192.88.99.1, such firewalls might might the traffic from returning to the end user.<br /><br />Furthermore, even after you've made sure about this, you also must make sure that all the egress points in your network (ISPs/transits/peers) allow the packets through as uRPF/static ingress filtering might cause them to be dropped.<br /><br />So if you want to run a local 6to4 relay, you better know what you're doing. It might be easier for most folks to buy internet service from a transit/service provider that is operating their own distributed relays which are covered by the overall SLA.<br /><br />Emile: Marco's comment made me realise that your footnote says you traceroute to 192.88.99.1 to determine the closest relay, which won't tell you the information you're after. You need to traceroute to 2002::/16 in order to determine where the return relay you're using is located. Apologies for not noticing this earlier!<br /><br />Tore<br />
Anonymous •
Our return path is consistently with Surfnet (thanks Tore for pointing the s/192.88.99.1/2002::\/16/ error, I've fixed that in the methodology), and I don't have reason to believe their relays are flaky. If they were blackholing we'd see 100% failure rate. Looking at the data in a bit more detail, almost all relay-sources (determined by first 48 bits of the IPv6 source) either fail or succeed in creating 6to4 connections consistently (only for 0.6% I see both fails and succesful connections).<br /><br />It may be interesting to do a follow-up experiment where we alternate between using 6to4-relays on the return path: one that uses it's own IPv4 source IP for the return packets, and one using 192.88.99.1. This may allow us to measure the breakage due to the stateful firewalls that look at (src,ip,proto) versus other breakage.<br /><br />
Anonymous •
I'm pretty sure that hosting a 6to4 node (or at the server level) will no do any good for this problem.<br />The problem is not the 6to4 node which transforms ipv6 to ipv4. It's the client's network that blocks ipv6 packets encapsulated in ipv4 packets. There's nothing you can remotely do against it. 6to4 client implementations should first *check* that their 6to4 connectivity is more than theoretical and connect to known working ipv6 addresses before using it.<br /><br />Better. ISP should provide it. Now. We're nearly in 2011, all major carrier and network hardware providers support ipv6, all common software run it, there's no excuse not to provide ipv6 connectivity. If your hardware does not support it, wait for the renewal of hardware. If you just renewed your hardware, you messed up.<br /><br />Aris
Anonymous •
Not only, as Tore described there is more to it and I have seen to many networks advertise 2002::/16 and acting as traffic sink
Anonymous •
A 1% failure rate would be outrageous. A 10% rate? Time to throw away the technology!<br /><br />This real-world data seems enough to author a "6to4 Considered Harmful" Informational RFC, I think.
Anonymous •
Shane,<br /><br />This document is not specific to 6to4, but I think it is pretty much what you're asking for anyway:<br /><br /><a href="http://tools.ietf.org/html/draft-vandevelde-v6ops-harmful-tunnels-01" rel="nofollow">http://tools.ietf.org/[…]/draft-vandevelde-v6ops-harmful-tunnels-01</a><br /><br />Tore
Anonymous •
I'd also like to see academics step in here. This paper ( <a href="http://repository.upenn.edu/ese_papers/537/" rel="nofollow">http://repository.upenn.edu/ese_papers/537/</a> ) models IPv4 to IPv6 migration, but doesn't include IPv4->IPv6 conversion technology (because the assumption is either v4 or dual stack content). One of their results from this modeling is pretty interesting:<br /><br /> Do not make translation gateways any better than you have to<br /><br />Which makes sense, because if translation is too good why would people switch? (and we'd be stuck in translation forever).<br />So I guess there is a sweet spot for translation gateways between too good for people to switch, and so bad that it hampers deployment. I'd be interested to see where that point is.
Anonymous •
Here we go ... debugging networks via Facebook comments. <br /><br />On Sept 1'st 2010 Hurricane Electric added a 6to4 & teredo relay in Amsterdam (hence close to RIPE NCC’s Internet connection). All our 6to4 and teredo relays are anycasted globally with relays deployed in many locations in Asia, North America and Europe. In Amsterdam we instantly saw around 700 Mbps of 6to4/teredo traffic being relayed; with no reduction of traffic at any other European relay. On Sept 24'th 2010 we added a relay in Paris. On Sept 30'th we added a relay in Stockholm. Paris relayed less than 100Mbps of traffic and Stockholm 200 to 300 Mbps. Once again, we saw no reduction in traffic anywhere else in Europe. We could deploy more and more relays while still not sopping up all the required relaying.<br /><br />The logic is simple. The 6to4 protocol (and hence how relays work) is an asymmetric protocol. This means that the 6to4 relay used in one direction of a TCP flow most likely is not the same relay that's used for the opposite direction. In many cases that will imply that if you place a 6to4 relay within your network you can solve (at best) 50% of your 6to4 woes. Convincing the other side of your communication path to do the same is more complex as the Internet is global and you could be communicating with remote networks that potentially don’t have a good return path to a 6to4 relay.<br /><br />Add to this a slight technological failure; ones seen by many network operators. Two forms of failure have been observed. First issue: The 6to4 implementations that are prevalent on global networks are simply four-line core-router configuration commands to turn on 6to4 processing within a network. Sometimes only in one or two locations. This can cause long paths between source and relay and destination. Latency is not your friend; but more importantly some networks then announce the anycast routes globally and end up drawing in relay traffic from locations all over the globe. This adds to the latency issue. The second observed issue was throughput. In some cases 6to4 relays observed in the field have been severely underpowered. We have seen core-router configurations top out below 100Mbps because of cpu-load vs. interface speed issues. We have seen significant congestion while still providing the perception to the network operators that they are providing a working service. Even our deployment; which started with a well-known hardware vendor showed these issues and we quickly replaced the service with dedicated linux boxes with tuned kernel drivers. We saw significant (sometimes greater than 10:1) improvement in bandwidth handling. We removed the flat-top graphs with something that’s more in-line with what we expected. Add to that experience we also made sure our deployment of relays was global, so that each and every POP has a relay. This reduced latency as much as we could for our side of the TCP path.<br /><br />That all said; we still are not at to the root of the problem. The asymmetric nature of the 6to4 protocol says that we can do only so-much to solve this issue.<br /><br />Here’s an example of how much of an issue this is. A global backbone recently informed us that their 6to4 relay and teredo relay traffic was globally routed into one specific NREN (a customer), which in turn is routed into a small college who just stood up a new relay. (Customer routes beat peering routes mainly because of localpref rules.) That’s global backbone was in the process of changing it’s policy on listening to global anycast routes so that they are filtered from customers and will deploy it’s own 6to4 relays globally. That’s progress; but that’s just one out of many backbones. There are plenty more that don’t work so well.<br /><br />The summary of the Hurricane Electric experience is that even if you deploy the largest 6to4 relay service; you will still only deal with half the issue. We have found that measuring 6to4 performance to be a mixed bag of results. We know that it sometimes is a major win and sometimes it’s a bust. It all depends on where the traffic is flowing. Overriding all of that is one other issue. The bulk of the 6to4 relay traffic is actually coming from the teredo relay protocol and if you don’t deploy teredo relays adjacent to the 6to4 relays (or in the same kernel in our case) you simply exacerbate the 6to4 problem. It took us a while to understand that subtle point and once we did we had a whole new respect for the 6to4 protocol and what it could do.<br /><br />We encourage more work by RIPE NCC in this area; alas you can’t just RFC 6to4 away.<br />
Anonymous •
I concur.<br /><br />I've seen the same.<br /><br />Basically it goes along these lines: Lots of ISPs with many customers deploy bandwith-throttling techniques that limits eg. p2p-traffic. Most does, I'd say.<br /><br />So the application identifying bandwidth-throttling devices, they can't identify Teredo (it *is* hard to do), so end-users running a p2p application that can use IPv6, like bit-torrent, can end up with orders of magnitudes more bw over IPv6 than IPv4 (I've seen 60x).<br /><br />So the base of your Teredo relay users are now every home user everywhere, and the bandwidth source that amounts to, which is basically immense.<br /><br />And what happens is that 6to4 needs to rendezvous with Teredo, and this amounts to most of this traffic.<br /><br /><br />I've also seen exactly this preferred customer thing Martin mentions (not sure if it's me he's referring to or not :) )<br /><br /><br />Here are the graphs of the project I ran at our dormitory, AS48514: <a href="http://martin.millnert.se/docs/ipv6-relay-experiment-over/" rel="nofollow">http://martin.millnert.se/docs/ipv6-relay-experiment-over/</a><br /><br />We couldn't continue to bear all this traffic, plus, some of the paths our Teredo created were really sub-optimal. Then again, if we can conclude that Teredo is virtually never ever used to look at web content, but rather mostly bulk data transfers, latency isn't that big of an issue as the content people usually considers it.
Anonymous •
I am very interested in this kind of research. There is an increasing amount of scare-story noise about IPv4 depletion, but little insight into what will actually happen in the next few years.<br /><br />I recently wrote about the likelyhood of ISP market disruption driving the rate of IPv6 deployment<br /><br /><a href="http://wp.me/pLN1x-7B" rel="nofollow">http://wp.me/pLN1x-7B</a>
Anonymous •
I wrote about 6to4 and my experience with it at:<br /><a href="http://www.avonsys.com/blogpost366" rel="nofollow">http://www.avonsys.com/blogpost366</a><br /><br />I suspect a lot of 6to4 issues are related to the discovery of MTU size and sending Packet To Big (PTB) messages.<br /><br />WAND distribute a nice tool to test PMTUD on IPv6: <a href="http://www.wand.net.nz/scamper/pmtud.php" rel="nofollow">http://www.wand.net.nz/scamper/pmtud.php</a><br /><br />I wish it would be standard in many distributions as it gives good insights on what is happening.<br /><br />I had to disable my 6to4 gateway at home on my Apple Airport extreme as it would fail way too often... I debugged extensively but could not pinpoint the issue. Is is with the Airport Extreme or the 6to4 gateway in Australia?<br /><br />We need better tools!
Anonymous •
- I'm running Teredo and 6to4 relay on one server, and announce it to my clients and peers. It is about 20-30 mbit/s flow from Teredo to 6to4, and back. Really funny ;)<br /><br />I think not 6to4 or Teredo is a bad thing. The bad is to prefer not so native IPv6 like this over to IPv4 direct connection. As well as huge timeouts lead to unusable dual-stack connections at all.
Anonymous •
I was asked how many of the failed 6to4 connections attempts have an embedded RFC1918 address; these connections can never succeed because the return packet cannot be routed back to the source.<br />I checked this with the data from the experiment and out of a sample of 53586 failed connection attempts I saw very low levels of embedded RFC1918 addresses:<br />192.168/16 49 (0.091%)<br />172.16/10 4 (0.0075%)<br />10/8 11 (0.021%)<br /><br />combined: 0.12%
Nusrat •
Just turn off your firewall, or select the other computer(s) network adapter to the "trusted" list
kwiz •
Hello, I did a performance analysis of 6to4 and manual tunnelings Some one can explain me why in all applications , manual tunneling is performing better than 6to4 tunneling in all metrics. Thanks
Nathalie •
Hi Kwiz, One possible reason 6to4 tunnels are performing worse is because the 6to4 relay servers are sometimes not very well (read: pretty badly) maintained and traffic is asymmetric by nature. This is one of the reasons 6to4 tunnels are nowadays discouraged.