
On the night of 9 April 2018, DE-CIX Frankfurt experienced an outage. As this is one of the largest Internet Exchange Points, this is an interesting case to study in more depth to see what we can learn about Internet robustness. We plan to update this article if new information/corrections flow in.
The information we received (for instance here and here) about the DE-CIX Frankfurt outage indicates a component of this Internet Exchange Point (IXP) lost power. We analysed an outage at another very large Internet Exchange point in 2015, and repeated this as another case study for "how the Internet routes around damage".
How we performed our analysis
In short, we repeated what we did for the 2015 AMS-IX outage. First we tried to find the traceroute paths in RIPE Atlas that indicate successful traversal of the DE-CIX Frankfurt peering LAN on the day before the outage (see footnote [1] for the technical details). In the data, we find a total of 43,143 source-destination pairs where the paths between them stably and successfully traverse DE-CIX Frankfurt [2].
To give some impression on the diversity of these pairs: there are 5,108 unique sources (RIPE Atlas probes), and 1,051 unique destinations in this data. An important caveat to make at this point is that, in this study, we can only report on what RIPE Atlas data shows, which is hard/impossible to extrapolate to the severity of this event for individual networks, which is likely different for different networks in different parts of the Internet topology.
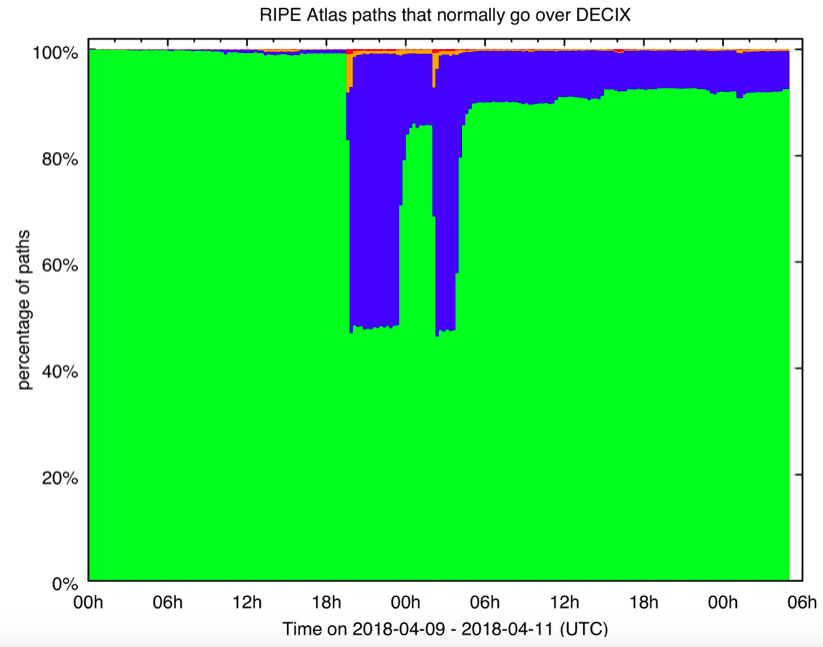
With this set of source-destination pairs we looked at the period of the reported outage starting on 9 April 2018. The result of this is shown in Figure 1:

Figure 1: RIPE Atlas paths that normally reliably traverse the DE-CIX Frankfurt infrastructure
What you see in Figure 1 is how the characteristics of paths that RIPE Atlas monitors during the DE-CIX Frankfurt outage change during and after the outage. Normally these paths will traverse DE-CIX Frankfurt and they 'work' - i.e. the destination is reliably reached. During the beginning of 9 April this is also what we see, as indicated in green in Figure 1. Starting at around 19:30 UTC we see, in blue, that a large fraction of paths still 'work', but we don't see DE-CIX Frankfurt in the path anymore. This indicates re-routing took place at that time. For a small fraction of paths (in orange and red) we see that the destination was not reached anymore, indicating a problem in Internet connectivity for these specific paths.
What our data indicates is that there were 2 separate outage events. One from 19:30-23:30 on 9 April, the other from 02:00-04:00 on 10 April (all times UTC). For these events, the paths mostly switched away from DE-CIX, but data also indicates the source-destination pairs still had working bi-directional connectivity, i.e. "the Internet routed around the damage". It would be interesting to see if other data (maybe internal netflow data from individual networks?) reveals anomalies that correlate to the two outage intervals we detected.
From the information we gathered, we think these are the times that many networks lost connectivity to the DE-CIX route-servers [4]. What's interesting to note is that, between these two outage events, many paths switched back to being routed over DE-CIX. The other interesting thing about the graph is that, more than a day after the events, in the order of 10% of paths haven't switched back to DE-CIX. This could be due to network operators keeping their peerings at DE-CIX Frankfurt down, or it could be the automatic fail-over in Internet routing protocols at work. For the network techies: the BGP path-selection process at work. If all of the other BGP metrics (local pref, AS path length, etc.) are equal, the oldest path (or currently active path) is selected. So if the DE-CIX peering session was down for a while, and another path with similar BGP metrics was available, then the BGP path selection process would select this other path.
Validation
Packet Clearing House operates BGP route collectors at various IXPs. They release routing table updates from those collectors. The rate of advertisements and withdrawals around network reconfiguration is important - as routers drop connections, they will propagate updated state to their neighbours in an attempt to locate alternative paths, or cease propagating an advertisement they can no longer carry.
Without digging deep at all, the rate of updates helps us pin down exactly when the DE-CIX outage took place:

Figure 2: BGP update rates from PCH route collectors at DE-CIX infrastructure in Germany
The signal is extremely clear: there are two periods where the collectors stop observing any updates at all: between 19:43 UTC and 23:28 UTC on 9 April, and between 02:08 UTC and 03:51 UTC on 10 April.
What we'd love to explore...
We intend to make data available from this analysis [3], so others can dig deeper into what happened here and what can be learned from this. Some specific questions that can be interesting: How much of this is anycast networks being rerouted? Can this be correlated to other datasets?
So does it route around damage?
Back to the larger question: Does the Internet route around damage? As with the 2015 event our case study indicates it mostly does.
Feedback, comments are, as always, appreciated as comments at the end of this article. We'll try to incorporate feedback into the main article.
Footnotes
[1]: For all of the RIPE Atlas traceroute data on 8 April 2018, we select the source-destination pairs that stably see the DE-CIX Frankfurt peeringLANs (as derived from PeeringDB). We define this as: the path between the source destination is at least measured every hour, the destination always sent packets back, and the peering LAN is always seen.
[2]: This is to the extent that one can detect this in the traceroute data we collect
[3]: Please let us know by email if you are interested in this at labs (at) ripe.net
[4]: From data we gathered from https://lg.de-cix.net/ , we estimate that 40% of networks connected to the route server got disconnected to both DE-CIX Frankfurt route-servers.
Comments 2
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Matthias Š •
we at AS1764 kept the peering down, until we got the clear signal the incident is over. As easy to see, we did enable DE-CIX peerings again in the night after the incident.
Georgios Smaragdakis •
Nice article! It is important to clarify, that it was not a DE-CIX outage, but a power outage at one of the affiliated datacenters that hosted an edge switch of the DE-CIX. I take this opportunity to mention that we provided a method to infer full or partial outages at peering infrastructures that may involve only one/some of the affiliated datacenters/colocation facilities: "Detecting Peering Infrastructure Outages in the Wild" SIGCOMM 2017 https://dl.acm.org/authorize?N33926 This outage also shows that colocation/peering facilities have evolved to be critical Internet infrastructures and additional steps have to be taken to guarantee that they will be 100% up. Our study shows that there are at least 10-15 such events around the globe every year and multiple networks are affected, even networks that are far away from the epicenter of the outage. Using RIPE Atlas with the help of Emile, we also noticed that in some cases the end-to-end RTT increased dramatically, up to 100s of msecs, during the outage. It is also important to note in this blog, and in the previous one by Emile ("outage at another very large Internet Exchange point in 2015") that some of the paths do not return, even days after the event. We also noticed that the reaction of the networks varies dramatically. Some of the networks reroute their traffic using other peerings within seconds, while for others it takes minutes or even hours.