I'm a data scientist at the RIPE NCC. I'm a chemist by training, but have been working since 1998 on Internet related things, as a sysadmin, security consultant, web developer and researcher. I am interested in technology changes (like IPv6 deployment), Internet measurement, data analysis, data visualisation, sustainability and security. … More
While at this point it is still unclear what exactly happened at Facebook this morning (27 January), we collect data on the Internet control plane (BGP) and data plane that allows us to provide some insight into what happened with Facebook's connectivity to the rest of the Internet.
Control Plane (BGP)
News reports show that many people saw a "something went wrong" webpage on Facebook in the early morning of 27 January (UTC), which indicates that the Facebook network remained reachable. However,
the number of updates we receive in BGP
(the Internet control plane) is a first clue that something happened with regards to the connectivity of the Facebook network to the rest of the Internet. This is shown in Figure 1 below.
Figure 1: The number of BGP updates for AS32934 (Facebook)
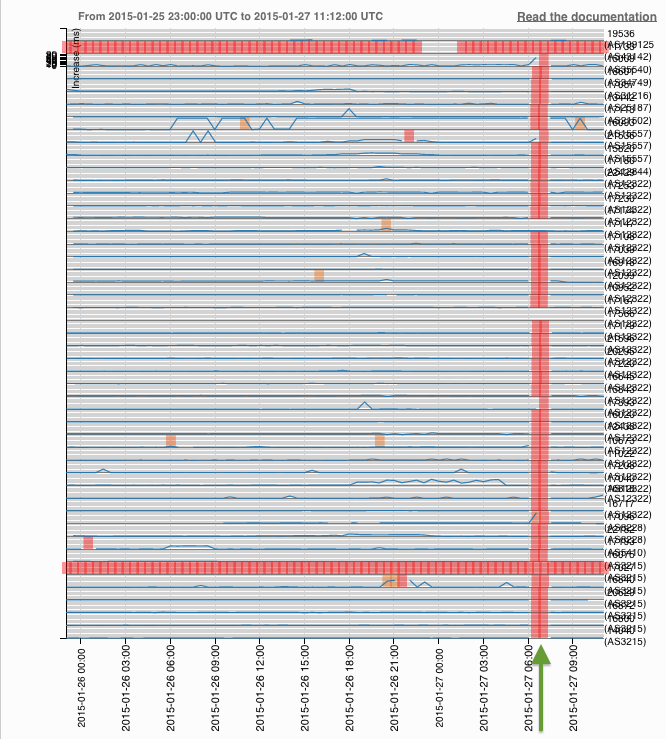
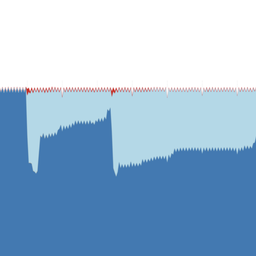
If we look closer at the individual networks that Facebook announces to the Internet (see Figure 2), we see that some networks were withdrawn from the Internet at the same time as the reported outages, while others stayed up. The networks that stayed up are shown as continuous horizontal lines. The networks that were withdrawn are shown as horizontal lines with interruptions. As you can see in the image below, the problem mainly affected IPv6 networks, and for most networks this started about 6:15 (UTC) and lasted until 7:10 (UTC) on 27 January.
Figure 2: Visibility of prefixes of AS32934 (Facebook) in the last 24 hours
While initially these interrupted lines look pretty bad, if you look closer at the data in terms of user connectivity to the Facebook network, it is not as bad as it seems. For the networks that were disconnected, there were covering prefixes that stayed up, which in effect would allow any Internet traffic to still reach the Facebook network, although it would potentially reach the network in a different location. If the traffic, once in the Facebook network, was still routed towards it's intended destination, the withdrawal of these networks does not necessarily mean IP level connectivity was disrupted.
The more-specific networks that were withdrawn are possibly used for traffic engineering, such as making Internet traffic flow into their network at a specific location.
As Facebook reported an internal glitch as the cause of their problems
, it could be possible that their Internet traffic engineering configuration was part of the glitch.
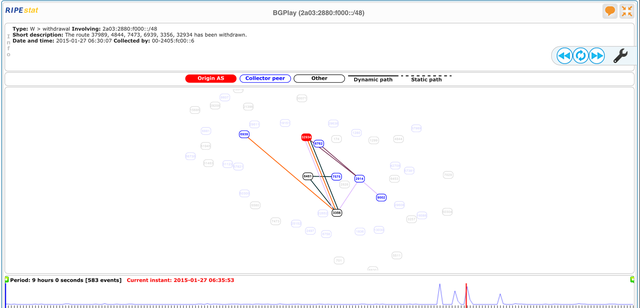
To account for ghost routes and low-visibility routes, our definition of a visible route in Figure 2 is as follows: 10 or more RIS peers see this network. If we look more closely at what's going on with specific prefixes, we see a different picture, however. For instance, if we look at 2a03:2880:f000::/48 with BGPlay, we see that during the outage period there was a stream of updates and withdraws for this network, which may have hampered consistent IP-level connectivity. A screenshot of the BGPlay view is shown in Figure 3 (
click here to see the animated version in RIPEstat
).
If we look at this from the data plane with
RIPE Atlas
, there is an
IPv4-ping measurement towards www.facebook.com from 50 RIPE Atlas probes in France
that suggests IP-level connectivity was disrupted. This is shown in Figure 4. Red areas in this figure indicate ping-tests of IP-level connectivity that were not successful. The vertical red area (indicated with a green arrow) shows two rounds of measurements where IP-level connectivity to Facebook mostly failed. This is the same time as the reported Facebook outage. Figure 4 also shows two probes that continuously had connectivity problems to Facebook (red horizontal areas). Most likely these are not outage-related problems, but related to the setup of these specific RIPE Atlas probes.
Figure 4: IPv4 ping measurements from RIPE Atlas probes in France towards www.facebook.com. Each horizontal line represents ping measurements from a single RIPE Atlas probe. Failing ping tests are shown in red.
Internet Traffic Volume
We don't have visibility into global Internet traffic volumes, but a quick scan across various public statistics pages of Internet Exchange Points (IXPs) does show a noticeable dip in
IPv6 traffic across the Amsterdam Internet Exchange AMS-IX
at the same time as the reported problems at Facebook. This is shown in Figure 5. It is unclear what part of this missing traffic can be attributed to less IPv6 traffic to Facebook; potentially Facebook IPv6 traffic was temporarily not going via the IXP, or this dip is not Facebook related at all.
Figure 5: IPv6 traffic volume on AMS-IX on 27 January 2015. The traffic volume decrease, correlated to reported Facebook problems, is indicated with a red arrow.
Conclusion
For a network operator it can be useful to have visibility into when your own networks become disconnected from the rest of the Internet. We are working towards faster detection of events relevant to network operators. For that we use the RIPE NCC measurement infrastructure (
RIPE NCC Route Collectors
and
RIPE Atlas
), but we're also looking into new methods of detecting significant events. We know it is important to provide easy access to the data the RIPE NCC makes available, so we are working towards having
RIPEstat
(the main interface to this data) show relevant data for events like Facebook's problem today, in near-real time.
I'm a data scientist at the RIPE NCC. I'm a chemist by training, but have been working since 1998 on Internet related things, as a sysadmin, security consultant, web developer and researcher. I am interested in technology changes (like IPv6 deployment), Internet measurement, data analysis, data visualisation, sustainability and security. … More
I'm a data scientist at the RIPE NCC. I'm a chemist by training, but have been working since 1998 on Internet related things, as a sysadmin, security consultant, web developer and researcher. I am interested in technology changes (like IPv6 deployment), Internet measurement, data analysis, data visualisation, sustainability and security. … More
I'm a data scientist at the RIPE NCC. I'm a chemist by training, but have been working since 1998 on Internet related things, as a sysadmin, security consultant, web developer and researcher. I am interested in technology changes (like IPv6 deployment), Internet measurement, data analysis, data visualisation, sustainability and security. … More
I'm a data scientist at the RIPE NCC. I'm a chemist by training, but have been working since 1998 on Internet related things, as a sysadmin, security consultant, web developer and researcher. I am interested in technology changes (like IPv6 deployment), Internet measurement, data analysis, data visualisation, sustainability and security. I'd like to bring research and operations closer together, ie. do research that is operationally relevant. When I'm not working I like to make music (electric guitar, bass and drums), do sports (swimming, (inline) skating, bouldering, soccer), and try to be a good parent.
Comments 2
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Antonio Ojea
•
Could you obtain the network prefix visibility graph from this post from the API or a widget?
Emile Aben
•
Thanks for your interest in this. Currently it's not easily available. Via various calls you could get the associated prefixes for an AS (announced-prefixes widget/API call), and then for all of these prefixes get BGP update/withdraws (bgp-update-activity widget/API call). You'd then have to keep state for all of the RIS peers to see if a prefix "goes down" or up again.
Longer term, we plan to have things like this more readily available in RIPEstat.






Comments 2
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Antonio Ojea •
Could you obtain the network prefix visibility graph from this post from the API or a widget?
Emile Aben •
Thanks for your interest in this. Currently it's not easily available. Via various calls you could get the associated prefixes for an AS (announced-prefixes widget/API call), and then for all of these prefixes get BGP update/withdraws (bgp-update-activity widget/API call). You'd then have to keep state for all of the RIS peers to see if a prefix "goes down" or up again. Longer term, we plan to have things like this more readily available in RIPEstat.