
Please find in this article insights into solutions that mid-size organisations need to deploy on the DNS and BGP level. We are monitoring success using, among other tools, RIPE Atlas.
This post originally appeared appeared on the GitHub Engineering blog.
GitHub is at a scale that provides exposure to interesting aspects of running a major site and are working to mature and level-up many parts of our infrastructure as we grow. One of the areas where this is evident is in how your requests find their destination using DNS and make their way into our sites over transit and peering. Many organisations are either too small to need to tackle these sorts of problems or so large they have groups to maintain existing solutions for each portion of them. It is really compelling to be able to directly work on such projects and closely with great engineers who are solving others still.
Network ingress
The foundation is built with links to Internet providers referred to as transit. Conceptually they’re similar to the connection you have at home, a link through which you can reach any other point on the Internet. The biggest difference is that IP blocks can be announced as reachable through the link via BGP. Like your home connection the link will have an IP address, but in contrast that IP address is an implementation detail and not directly used by us to serve github.com. We instead announce blocks of IP addresses, for example 192.30.253.0/24. When an ISP sees packets with a destination address in that range, they will forward them towards the best source of the announcement. Another difference is how transit is priced, typically billed by bandwidth in Mbps, megabit per second, at the 95th percentile.
We have multiple providers in each of our regions with diverse links spread across routers. These links are commonly referred to as cross-connects and are physical strands of fiber optic cable that run from our device to theirs within the same facility.
In early 2015, 100% of our requests arrived over transit links directly into our IAD data center. In the past two and a half years we’ve grown that substantially, now landing over double that capacity at each our IAD and SEA edge sites. As part of that move we’ve gained access to high quality peering. Broadly speaking peering is a connection established directly between two networks. The main difference between peering and transit is that peering only allows you to reach things on the peer’s network. You generally can’t “transit” them to reach others.
We have two types of peering currently in use. The first is private network interconnect (PNI), a direct connection between their routers and ours. This is generally used when a sufficiently large volume of traffic regularly travels between the two networks. For us it can consist of a single pair of 10Gbps links or many pairs as required by the bandwidth and availability needs. The other type of peering we do is over Internet exchanges. In the case of exchange based peering instead of direct connections between the two networks’ routers, a connection is made through an intermediate network specifically for connecting peers. Through the exchange hundreds of other networks can get access to us and vice versa. Since there’s no per-peer physical resources being used beyond the initial exchange connection it’s effectively free to peer in this way and in fact exchange based peering is commonly settlement free, meaning no money changes hands. This is often the case for PNI as well.
While peering can cut costs, that’s often a secondary benefit. The real upsides are in performance and availability. Having a direct connection means that traffic between the two networks is 100% in the control of two parties who are able to communicate with each other. It also means fewer hops between the source and destination which can improve latency considerably and avoid congestion.
The increases in our transit capacity, addition of a second region, and the work on GLB, our load-balancing tier, has allowed us to handle volumetric DDoS attacks that in the past would have impacted our users. We’re very proud of that progress and always working to improve it further.
Traffic engineering
The first step in the process of contacting GitHub is to direct things to the closest region. We use DNS, specifically GeoDNS to return a record based on the geographic location of the IP address doing the lookup. We conduct network level measurements using tools like RIPE Atlas and instrument our applications to collect similar information on real user requests. This data allows us to make choices on which locations should be serviced in SEA and which are best sent to IAD. We configure our split authority DNS providers with the results.
Now that your request has a destination, network routing takes over. There are dozens of last hops your requests can take into our sites and nearly boundless options for getting to that point. To take a seemingly intractable problem and solve it millions of times per second at each point in the network, things have to be simplified. This is accomplished by localising decisions.
Each hop along the path between yours and our network makes its own choice using an algorithm like BGP route selection. This allows an extremely quick next hop decision to be made for a packet. There are a number of inputs into the process, but conceptually each device has its own idea of the best link to send a packet down in order to get it closer to its ultimate destination. We have the ability to influence the decisions by withdrawing or modifying our announcements, but ultimately control rests with the network devices and operators who set local preferences based on costs, capacity, health, and other factors. The adjustments we make are most often in response to large incidents with our direct or indirect providers, and aim to shift the traffic away from a specific trouble spot or temporarily remove a provider altogether.
It’s important to note that at this level there’s no fundamental difference between transit and peering. Both use the same mechanisms to make next hop decisions, it’s that the best next hop when peered directly with someone is almost certainly over that connection when things are operating normally. Take away that link and the algorithm would fall back to its next best option, likely a transit link.
Current state
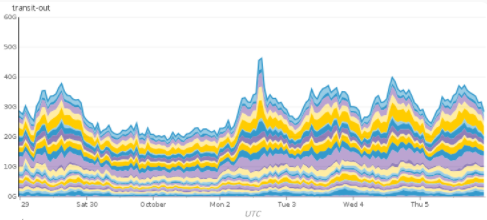
To recap, we have two major types of connectivity - transit and peering. Within peering, we have two sub-types, PNI and IX. We’ve talked previously about our internal network metrics and we have the same types of data for our points of ingress/egress.

The image above shows our ingress and egress traffic for the past week across transit, PNI, and Exchange links. Especially interesting is that peering accounts for 60-70% of our traffic. That’s a huge deal, it means that three quarters of our bandwidth has an optimal path between its origin and destination, providing best case performance and cost savings for both parties. If you happen to have an exchange connected network check out our PeeringDB page and reach out if you’re interested in connecting.
Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Shane Kerr •
It's a pity that after all of this network engineering work there's still no IPv6 for GitHub. 😢
Gert Döring •
Shane beat me to it - when can we expect to hear about your experiences with IPv6? It's 2017... there is no excuse anymore.
Ross Chandler •
Yes, very disappointing that GitHub still don't support IPv6. It is hard to believe they can't at least make a start on it as they already use a CDN for some of their content delivery.