
The DNS is at the core of most interactions on the Internet. Therefore it is essential to ensure proper authentication and encryption of DNS data. There are number of initiatives that can help users in this context.
Encryption is everywhere. It’s an initiative in the technical community that started as a reaction to Edward Snowden’s revelations about the NSA’s widespread surveillance and pervasive monitoring. For many, it was a wake-up call that resulted in advancing security best practices, such as stronger encryption on mobile phones and web traffic security services such as Let’s Encrypt.
All of these efforts are aimed at protecting the complete path between the user and the service. This means authentication and encryption should start at the edge of the network, with the end user. As just about any interaction on the Internet starts out with a query for a domain name, it puts the DNS at the core of achieving the ultimate goal.
This road is not without hurdles, as we’ve managed to make the edge where the end user lives a complicated and perilous place, with NATs on top of Carrier- Grade NATs, firewalls, a mix of IPv4 and IPv6 with translation mechanisms between them, and middle-boxes that rewrite packets or simply drop them on the floor. While traversing all of this complexity, we need to achieve two objectives with regards to the DNS:
- Authenticity and integrity of the DNS data
- Privacy of the user-DNS service transaction
DNSSEC allows for validation of the authenticity of DNS data. DNS-based Authentication of Named Entities (DANE) takes care of the authentication of the service by its public key (which can also be used to set up a TLS session). In this perspective, the DNS stub resolver is a key component to implement end-to-end security and privacy.
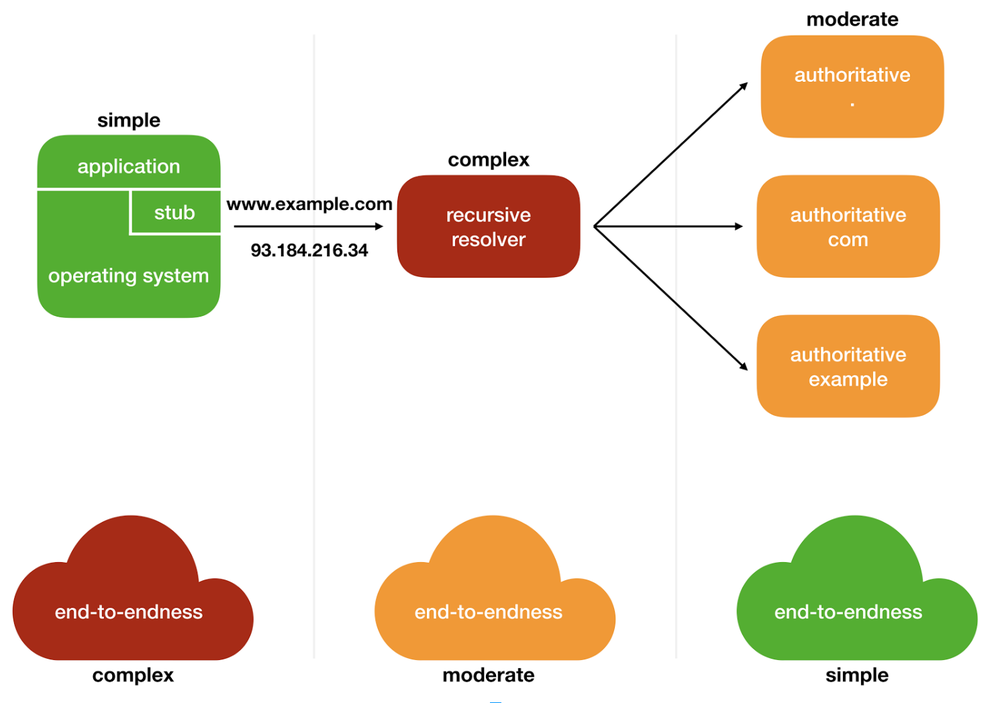
Although the stub resolver is considered a simple component in the DNS infrastructure, it has to work within the complex end-to-end properties illustrated earlier. On the diagram below you can see how the complexity of the DNS services compares to the complexity of the end-to-endness. Stub resolvers have to deal with the most complicated end-to-end properties by far, but don’t forget some DNS resolvers don’t forward DNSSEC data, creating yet another hurdle.

Let’s take a more detailed look at the impediments and the solutions to work around these problems.
DNSSEC challenges for end-points
There are many different kinds of impediments for DNSSEC validation and DANE authentication. This section certainly doesn’t present all cases (including the recent development of DNS-over-HTTP, which in itself would warrant an extended post) but focuses on the most important ones.
DNSSEC roadblock avoidance
Roadblock avoidance deals with DNSSEC validation at end-points that is often severely hampered by home router and modems, but also other middleboxes between the end-point and the service. The IETF DNS Operations working group published a document on DNS Roadblock Avoidance (RFC 8027). It describes sophisticated techniques to assess upstream recursive resolvers to effectively obtain DNSSEC data for validation.
An end-point implementing these techniques can determine the capabilities of the upstream recursive resolvers and can eventually use a fallback strategy to act as a validating resolver, directly addressing authoritative names servers, if all in-between solutions fail.
NAT64/DNS64
In a period of transition from IPv4 to IPv6, the DNS infrastructure has to cope with a specific situation where IPv6-only endpoints need to address IPv4(-only) services. We will probably have to deal with this situation for the foreseeable future, so also, in this case, a robust solution is required.
For IPv6-only environments, NAT64 translates access to IPv4 address space by mapping it to IPv6 addresses within a certain prefix, and DNS64 delivers the synthesised IPv6 addresses. Note that ‘“regular”’ DNS would answer with an IPv4 address of the service. Obviously, these synthesised DNS messages are not authentic and DNSSEC verification would fail.
To make DNSSEC available in NAT64/DNS64 environments, a validating stub resolver must detect it is situated in a NAT64/DNS64 network and do the IPv6 synthesis itself, as described in RFC 7050. This way, the IPv6-only end-point is able to use DNSSEC to verify the DNS reply with the authentic IPv4 address.
A typical example in which you need these capabilities in the stub resolver is when you have configured your device to use privacy enabling recursive resolvers, such as Quad9, in an IPv6-only mobile carrier (or cellular) network.
DNSSEC trust-anchor maintenance
Every time we mention DNSSEC validation, we actually talk about the verification of the signature over the signed DNS data. DNSSEC validation is the construction of a chain of trust, starting from a trusted DNSSEC key and following it down to the DNSSEC key used to sign the DNS answer.
The trusted DNSSEC key you start with for every DNSSEC validation is called the trust anchor, and is typically the key used to sign the root zone (formally called the Root Key Signing Key).
It’s clear that the management of the trust anchor is essential for correct operation of DNSSEC validating (stub) resolvers. As a result, a standard described in RFC 5011 is proposed to track changes in the DNSSEC trust anchor. This standard is written with the idea that the validating resolver is a continuously running process with administrative privileges.
DANE validation is done at the application level and makes use of a stub resolver with user privileges, as illustrated in the diagram above. There is no guarantee when and for how long the application with the stub resolver will run and we cannot rely on RFC 5011 to track trust anchor changes. However, there are no standards describing how applications should do trust-anchor maintenance yet either. A suggested method for user-space applications is a zero-configuration DNSSEC approach that relies on DNSSEC trust anchor bootstrap techniques described in RFC 7958.
Path forward
To scale up security and privacy, a dependable stub resolver is the first requirement. In the DNS resolution chain, the stub resolver is crucial in providing authenticated DNS data and assuring privacy at the end-point.
Something we haven’t covered yet is how to provide verified DNS data and DANE validation to the application. We discussed how a stub resolver is able to reliably receive DNSSEC validated data, but not how the application can access it. It is essential to give application developers an easy to use and flexible API to work with.
Two recent examples of DNS APIs are the systemd-resolved interface and the getdns API project.
Systemd uses systemd-resolved to provide the DNS functionality. Both components are part of the freedesktop.org project and applications can use the D-Bus interface for full-featured access to systemd-resolved, for example for DNSSEC validation status.
The getdns API project is jointly developed by NLnet Labs and aims to provide a flexible and modern asynchronous DNS API to application developers. The API is designed with input from application and system developers to match the requirements and expectations of the people that will eventually use the API.
Either way, some standardisation of a DNS API and making it available on a multitude of platforms is important to improve on the current situation and increase the use DNSSEC and DANE by applications.
To set an eample the getdns API project has implemented many of the recent standards to achieve the goal of DNSSEC validation and DANE authentication at the end-points. This means it includes DNSSEC roadblock avoidance, IPv6 synthesis for NAT64/DNS64 environments, and has zero configuration DNSSEC.
The design and implementation of the getdns API also closely follows the development of the DNS privacy standard (DNS-over-TLS) described in RFC 7858. It provides increased privacy for the user as passive observers can no longer see the DNS queries made by the client. However, keep in mind that you still have to trust somebody to know your questions and provide answers. There is no complete privacy in a system which has intermediates (resolvers) between you and authoritative DNS servers. Even if you ask authoritative DNS servers directly, they know you asked. This is why it’s a good idea to review the privacy policy of the DNS service provider before making a choice.
The getdns API provides DNS privacy for legacy applications through a system component called Stubby. It runs as a daemon on the local machine, sending DNS queries to resolvers over an encrypted TLS connection.
You might wonder how this differs from Unbound, another NLnet Labs project, because that can also be configured as a local forwarder that uses DNS-over-TLS to forward queries. At the moment, Unbound does not have all the TCP/TLS features that Stubby has. For example, it doesn’t support ‘Strict’ mode or pad queries to hide query size and it opens a separate connection for every DNS query (Stubby will reuse connections).
As it stands, Unbound is a more mature and stable daemon but we are working on making Stubby just as robust. Note, it’s also possible to use the two together: Unbound for caching and Stubby for upstream TLS.
Lastly, the getdns API is also convenient and beneficial for app developers for the Android and iOS platforms. Protecting data and privacy for mobile devices is an important subject for the next years to come and plans to support the getdns API for these platforms are becoming more definite.
The way that the Internet grows, develops and thrives has resulted in a complicated landscape. This makes securing it difficult, but there are open standards and running code that prove it can be done, offering security and privacy for everyone.
I presented this topic during the DNS working group at RIPE 75. You can find the slides and the recording here.

Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.