
BGP Route Flap Damping (RFD) is recommended to suppress BGP churn. Default RFD configurations in routers have been shown to be harmful. Current configuration recommendations by the IETF and RIPE, however, are based on a study from 2010 which focused on IPv4 only. This article presents our recent measurement study which shows that the old parameter recommendations are valid for today's Internet in both IPv4 and IPv6.
Route Flap Damping (RFD) is a mechanism to locally suppress BGP update churn on the Internet. RFD default configuration parameters in routers are too strict and cause unwanted prefix update suppression, which leads to reachability issues. In 2010, Pelsser et al. determined configuration parameters to avoid these issues.
This post presents results from a 2021 study in which my colleagues and I (from Freie Universität Berlin, IIJ/Arrcus, Université de Strasbourg, and HAW Hamburg) reproduced and extended the study from 2010 in order to also consider IPv6 and one other router vendor (Juniper).
We found that the current recommendations - BCP 194 and ripe-580 - are still valid today and will be valid in the future if current trends continue, considering IPv4 and IPv6. We recommend network operators check their RFD configurations for harmful vendor defaults and suggest that Juniper and Cisco update default values in their RFD implementations.
This blogpost is split into three parts:
- The first presents an up-to-date view of BGP churn on the Internet
- The second describes our measurement setup that we use to assess the RFD algorithm based on real-world BGP churn
- The third explains how we determined the correct configuration parameters for RFD
This research was originally published at IEEE/IFIP TMA 2021. Visit rfd.rg.net for more details.
3% of All IPv4 Prefixes Caused 53.9% of BGP Updates
We measured BGP churn using the public route collector projects Isolario, RIPE RIS, and RouteViews. We removed BGP duplicates (all attributes match) because they did not trigger best path selection and were most likely related to iBGP update activity in the vantage point network (see Labovitz et al. and Park et al.).
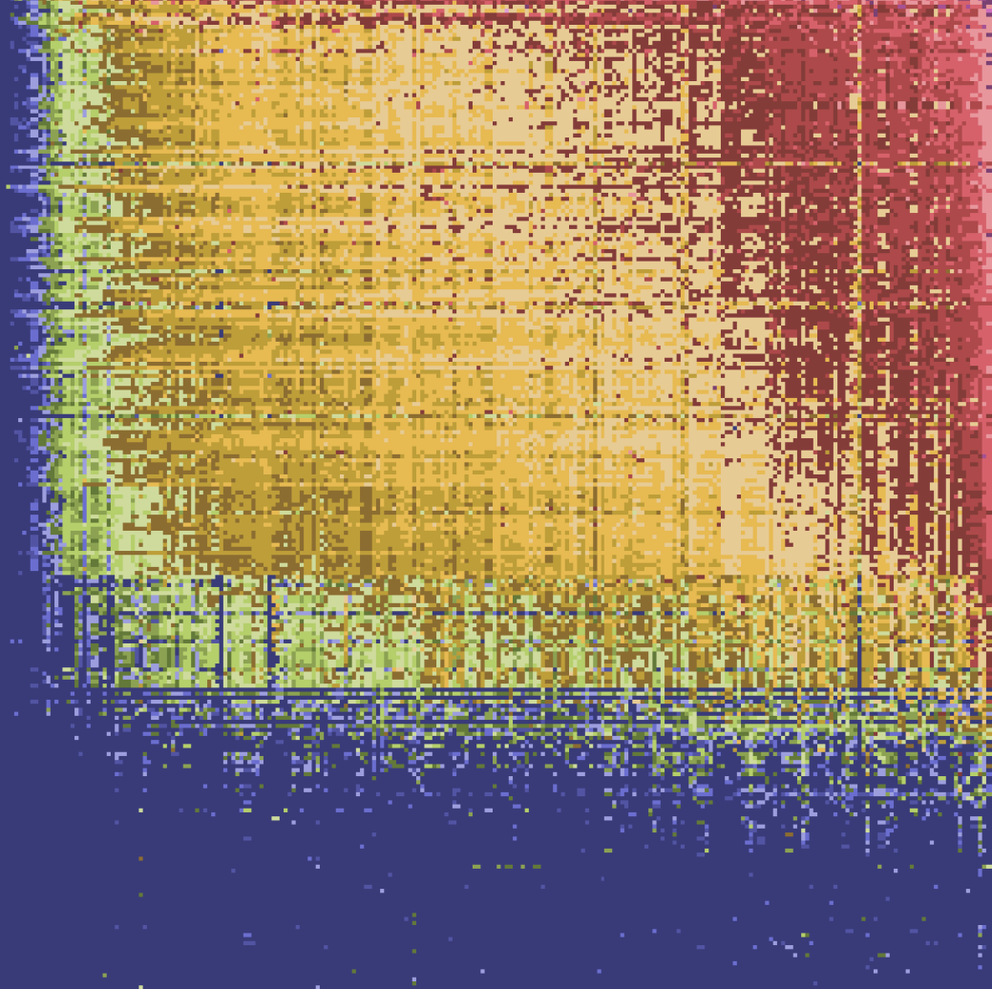
Figure 1 shows (below) that absolute BGP churn increased over the last ten years. But it has been shown that this growth is proportional to the number of active ASes on the Internet (topology size) (Jia et al.). Also, IPv6 seems to exhibit a much larger update activity per prefix and in total. This difference between IPv4 and IPv6, when normalised by the Internet topology size, is constant over time. At least from this perspective, the growth of routing activity complies with common expectations.
We can also see in Figure 1 how update activity is distributed across prefixes in 2020 and 2010. First, inactive prefixes (left part in the plot). Second, prefixes with some update activity (majority in the middle). Third, the most interesting group, heavy hitters (right part in the plot). To put this into perspective, in 2020, 3% of all IPv4 prefixes caused 53.9% of BGP updates (74.8% in IPv6).

Figure 2 provides a closer look at the hourly update rate for a week of the top 50 heavy hitter prefixes. The churn behavior of a prefix is periodic if the update rate is above 10 updates per hour during the entire measurement period, and otherwise erratic. Darker lines show that a set of prefixes have the exact same update rate because the lines are drawn with a low alpha value. When looking at these prefixes for a longer period, for example using RIPEstat, these plots extend for weeks and often multiple months (example). We do not see a reason why this update activity is useful.

RFD Measurement Setup
Similar to the BGP churn measurement above, we are using public route collector projects Isolario, RIPE RIS, and RouteViews. But this time we select a representative subset of vantage points consisting of 25 ASes of which 5 are hand-picked Tier-1 providers and 20 other ASes were chosen randomly. Our measurement period for 2020 is the first week of June.
We implemented Route Flap Damping based on its RFC and additional minor tweaks that are used in vendor implementations. This emulation takes the stored BGP updates and their associated timestamps as input and acts as if each vantage point is a neighbour (RFD suppresses per prefix per peer). In the next section, we analyse the penalty values across the week for each prefix and peer.

So What Are Optimal Configuration Parameters for RFD?
Configuring RFD basically means tweaking the suppress-threshold. A good suppress-threshold is neither too low nor too high because you do not want to suppress prefix announcements caused by normal BGP churn, nor do you want to allow for worst-case churn (heavy hitters).
To fully understand the impact of an inimically configured router, Figure 4 shows the share of prefixes damped at least once across our set of vantage points. The dashed lines indicate the share of prefixes that have been damped by at least one vantage point. The boxplot below the dashed lines shows the range of suppression levels across vantage points.
With the Cisco default suppress-threshold (2000), 29% IPv4 prefixes and 37% IPv6 prefixes have been damped and were therefore unreachable by at least one vantage point! Unsurprisingly, the share of suppressed prefixes varies significantly across vantage points. But we cannot make individual recommendations per network and therefore 2000 (and also 4000), can by no means be the generally recommended suppress-threshold.

But which suppress-threshold is too high? In Figure 5, we have plotted a different visualisation of how prefixes were damped on average at different suppress thresholds. A given row (for a suppress-threshold) shows all prefixes, sorted by the total number of updates from low to high, how long their are being suppressed.
At the Cisco default suppress-threshold, prefixes from all levels of churn are being suppressed at least once. At 6000, many fewer prefixes are being suppressed while most of the top 3% are still being suppressed. We still believe that a suppress-threshold upwards of 6000, at most 12000 is most reasonable as a general recommendation. Advanced users of RFD could start at 6000, watch what share of the routing table is being suppressed and then adjust the suppress-threshold to their needs.
You may wonder why for 97% of prefixes the colour distribution in the below plot looks rather similar for both IP versions, even though absolute churn in IPv6 is much higher. This is because the median update count across prefixes is identical in both IP versions while the mean is ∼4× higher in IPv6, that is, fewer prefixes cause more updates in IPv6.

We have determined an RFD parameter recommendation for today's Internet but what about the future? The RFD mechanism implements exponential decay based on a half life. This means that the amount of (common) BGP updates needs to increase exponentially to render current thresholds unusable. Since such an increase is a very unlikely scenario, RFD parameter recommendations very unlikely need change in the future. If our prediction of BGP churn is wrong and operational prefixes exhibit significantly more churn in the future, other issues will be much more of a concern.
Ideally, default configuration parameters are updated in vendor implementations. We understand that it may surprise network operators who rely on the default values. But, vendors could implement a simple warning saying that the current configuration is out-of-date and should be replaced.
RFD Parameter Recommendations
| RFD parameter | Cisco Default | Juniper Default | Recommendations: BCP 194 / RIPE-580 |
|---|---|---|---|
| Suppress-threshold | 2000 | 3000 | 6000 |
| Re-advertisement penalty | 0 | 1000 | 0/1000 |
| Attributes change penalty | 500 | 500 | 500 |
| Withdrawal Penalty | 1000 | 1000 | 1000 |
| Half-life (min) | 15 | 15 | 15 |
| Reuse-threshold | 750 | 750 | 750 |
| Max suppress time (min) | 60 | 60 | 60 |
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.