
We've made some extensive improvements to the RIPE NCC Routing Information Service (RIS) which is an integral part of RIPEstat and heavily used by researchers and network operators. More changes will come and we need your feedback! Please note the questions at the end of this article.
Introduction
The RIPE NCC collects and stores Internet routing data from several locations around the globe, using the RIPE NCC Routing Information Service (RIS), since around 1999. RIS data is collected by a number of RIS route collectors (RRCs) located all over the world. RIS data can be accessed via RIPEstat . The raw data is also available.
Current Status of RIS
There are currently 12 active collectors: one multihop collector in Amsterdam and 11 local collectors at Internet Exchange Points (IXPs) around the world. The data collection is based on Quagga. It stores BGP updates in MRT format every five minutes and s tores BGP table dumps in MRT format every eight hours. The looking glass function of Quagga is remotely queryable via RIPEstat. This setup h as been static for some time now after the last new RIS collectors were added in 2008.
Database back-end history
The original design of RIS was documented in the document ripe-200 , where the prototype service description was published. At that time, it was decided to use the Zebra routing software, combined with a MySQL database to store the data. It was noted in this document that the MySQL database may not be able to cope with the data requirements.
Since then (until recently), the system had stayed roughly the same. Zebra was replaced with Quagga (a fork of Zebra), and MySQL was still used as the database for a long time, although it had been heavily sharded and spread across multiple MySQL servers and master/slave replicas in order to try and cope with the incoming data.
As new collectors are added, and the size of the BGP routing table has continued to grow, along with a corresponding growth in BGP update activity, the MySQL-based system has continued to struggle to keep up with the incoming data.
In recent years, several revisions at replacing the database back-end have taken place. The back-end databases moved to using Hadoop as a storage and processing architecture, via several iterations of a system we called the Internet Number Resource Database (INRDB). (For more information on the INRDB, see Intro to INRDB and RIS and the INRDB ). This was mostly completed last year, when the last MySQL servers were removed from production.
The new Hadoop architecture now provides us with a horizontally-scalable processing and storage cluster. It also performs data import, processing, and aggregation of historical data. HBase now serves live queries via RIPEstat.
Collector scaling issues
While the issue of storing and processing the incoming data has (for the moment) been addressed, we now must turn to look at the other scaling bottleneck in the system - Quagga.
The current Quagga implementation is single-threaded which is n ot as scalable on modern multi-core CPUs. It locks updates during table-dump process and requires that the table dump completes before the hold timer expires, otherwise the BGP session will drop.
There were also s ome data consistency issues. The update files can contain updates that have been received by the collector but not yet applied to the Routing Information Base (RIB) when the table-dump occurs. This makes it di ffi cult to accurately rebuild BGP state at intermediate times, if updates and the RIB dumps are not necessarily consistent at a given time.
Much of the reason for this, is that Quagga does everything! It performs the following tasks:
- BGP speaker, talking to our peers
- Internal transport of the BGP messages between the Quagga subsystems
- Maintaining an internal Loc-RIB (Routing Information Base)
- Recording received BGP messages in MRT file format (every five minutes)
- Recording periodic Loc-RIB dumps in MRT file format (every eight hours)
- Providing remote access to query the Loc-RIB (looking glass)
Performing all of these tasks within one process results in a number of design constraints with Quagga that limit its scalability.
We decided to address these issues by breaking out all of the above components into separate processes, and develop suitable solutions for each component in a modular way.
New collector architecture
We worked on a new design of the entire system over the last two years. In 2014, a prototype was developed by Wouter Miltenburg as part of his bachelor thesis at Hogeschool van Amsterdam. Two RIPE Labs articles describing the architecture: Researching the next generation RIS route collectors and Building the next generation RIS route collectors .
After the encouraging results of the prototype indicated that this new design should work in principle, we began developing the production version of the new architecture. This is now in a beta stage, and we hope to be able to move it to production soon.
RIS Collector design
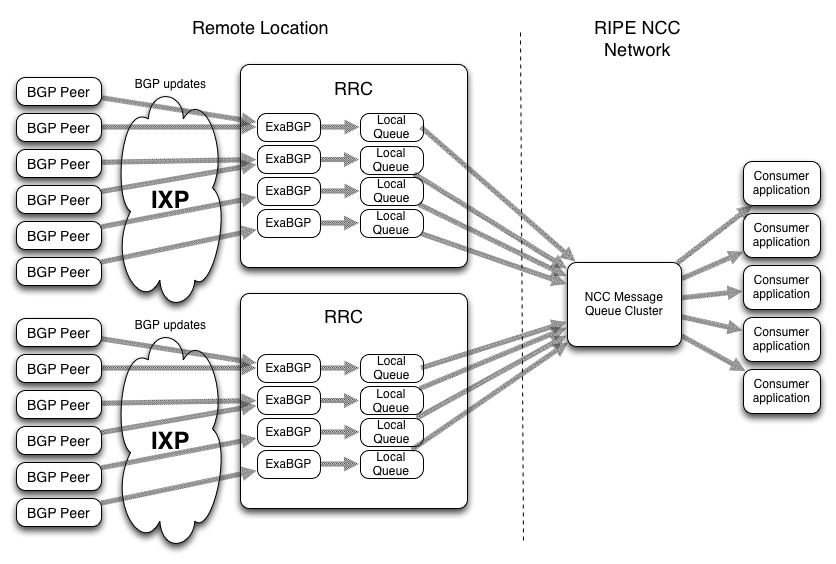
The following diagram illustrates the model used for the new route collectors at the remote locations, as they transport their data to the RIPE NCC:

Figure 1 : Model for new route collectors at remote locations, as they transport their data to the RIPE NCC
RIS data consumer applications
The following diagram illustrates the model used for the back-end applications at the RIPE NCC, which receive the data streamed from the collectors:

Figure 2: Model for back-end applications at the RIPE NCC
Discussion
There are several key points to note about the above diagrams.
- The first key change is that the collectors themselves are no longer involved in the processing of any of the data. They are simply a BGP speaker which establish a BGP session with the collector peers, and record the messages they receive into a queueing system. From there, the messages are transported in near real-time to the RIPE NCC network. All but the BGP speaker function of Quagga have been relocated to software components which are data consumers. For this reason, we also switched to using ExaBGP , as it is simply a programmable BGP speaker.
- The second key change is that each of the boxes in the diagram are not necessarily a single process or server. They should be thought of as a single component in the system. In reality, most of the consumer applications are actually Hadoop Map/Reduce processing jobs which are distributed across our Hadoop clusters. However they are not tied to being so, and can be re-implemented individually if any given application needs to be.
- The third key change is the use of a message queueing system as a transport for the recorded data. Assuming no network bottlenecks etc, we can transport the messages from the collectors to our infrastructure in the order of seconds.
- The fourth key change is that we can now add new applications/functionality easily. A new application is simply another data consumer. New data consumers can be added without impact to any other functionality
The main idea was to take all the functions previously performed by Quagga, and break them out into separate components which can be developed independently of each other, while using a message queueing system as the transport for the data.
This design decouples the production of the data from the applications that consume the data, and permits them to operate at different speeds, with different latency requirements, etc.
Comparison with Quagga
A good visual comparison is in the following diagram. This diagram compresses the previous two diagrams into one, and then highlights which components were previously performed by Quagga:

Figure 3: Model for new route collectors and back-end applications in one diagram
In the above diagram, every component previously performed by Quagga is within the green boundaries. This was all performed within one single-threaded process on each RRC!
The new architecture is a massive change to the previous design (as described in ripe-200), and gives us more flexibility to optimally design and implement each component for its specific task.
New capabilities
In addition to improved collector scalability, the queuing transport also gives us a live feed of the data.
To provide a comparison, here is a rough outline of the previous way the BGP data was ingested into our systems:
- Every five minutes on the collector, Quagga has finished writing to an MRT updates file.
- Every five minutes on the collector, a job checks for completed MRT files, and compresses them.
- On the back-end, every five minutes an rsync task attempts to retrieve the compressed MRT files, and store them in the raw data archive.
- On the back-end, every 10 minutes, a job checks for the presence of new files in the raw data archive, and then unpacks them and begins any necessary processing tasks.
With this previous design, there is a minimum of 15 - 25 minutes (depending on exact timings) before data can be made available.
With the new architecture, the data is transported within seconds to the back-end. An individual consumer application (such as one that is optimised for processing bulk data) may choose to simply store this for a while before processing it. However, if an application wants live data, it can have it available almost immediately.
Streaming Interface
We are currently developing a prototype public interface to the stream of live data (indicated by the stream consumer component in the diagrams shown above)
This is currently using the same design as the RIPE Atlas streaming interface that was recently made available.
This will provide users access to the live RIS data, to develop their own applications for this data. For an example, the popular BGPlay application for visualising BGP path changes over time, has been extended to support real-time updates, allowing live visualisation of path changes for a prefix. Please see the recent article by Massimo Candela for a demonstration of this.
It is hoped that the streaming interface will permit novel applications that can react to BGP events in real-time. We hope to develop some of these applications, but also permit others to use the data stream to create their own applications.
More information on the streaming functionality will be published as the service develops.
New RIS route collectors
This new infrastructure allows us to add new collectors and collect more data. As part of a pilot phase, three new route collectors have been installed recently :
- RRC18 at CATNIX in Barcelona, Spain
- RRC20 at SwissIX in Zurich, Switzerland
- RRC21 at France-IX in Paris, France
Currently, we are collecting data from BGP peers at these locations, and the data is being used to test and validate all the new components in the system.
At the moment we are in a heavy testing and bug-fixing stage with the new collectors - as we have had to reproduce a large amount of the existing processes performed by Quagga, we also must ensure that the data we produce is equal or better in quality compared to the existing system. For example, we must ensure that we correctly produce RIB table dumps from the incoming stream of updates, following the same decision algorithm, to produce accurate RIB data.
Once we are confident that we have fixed all the issues and have reliable data coming from the new system, we will begin publishing the new data in our archives, and make the data from the new RRCs available via RIPEstat queries as well. We will publish an announcement when the new RRCs are officially launched.
Existing Quagga collectors
We will run the old setup and the new setup in parallel for a period of time.
The focus on this will be to test the new system and ensure that we are confident of the data quality and stability of the new architecture.
Once we are confident, we will then look at replacing the existing Quagga-based collectors with the new architecture. At that point, we expect to permit new peerings on some of the collectors that currently cannot accept new peerings due to Quagga scaling limitations.
Feedback
We would love to hear any feedback on the new architecture and in particular the proposed live streaming enhancements:
- Do you think the live BGP streaming is useful?
- Are you interested in developing applications using this? What kind of applications can you think of?
- Would you be interested in a full stream of all the available BGP data, or just a subset? What criteria would you want to filter it by? (e.g. RRC, origin ASN, prefix, etc)
- Would your application need the stream to be resumable, or is it not important if you miss messages when you are disconnected from the stream?
Please leave any comments below or send mail to the RIPE Routing Working Group .

Comments 3
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Paul Jakma •
Neat. Just one comment, if it's possible to scale-out ExaBGP by running multiple processes of it, surely you could have just done the same with Quagga bgpd? Then consolidate the MRT dumps in post-processing with other tools, as you do anyway? Quagga's bgpd is quite happy to take specific IPs and ports to listen on as arguments anyway.
Colin Petrie •
Hi Paul, Indeed, there's many things like that which we could do. But we just wanted a BGP speaker on the collector, and then Quagga bgpd is overkill as we don't need most of what it does :-) We also wanted to relocate as much of the additional functionality away from the collector, so the collector could focus on only being a collector. We did play with the idea of using Quagga/Bird/OpenBGPd, and ripping all but the bgp-speaking code out of them, but we decided it was easier to use something that was just designed to be a BGP speaker only. And although we could merge the MRT files later, we'd have to add extra hooks into bgpd to give us the live stream - or have something that constantly tails the MRT update files to try and inject them into the queueing system, etc etc. This design made it easier to individually focus on each component. We could even build the back-end applications by injecting the BGP messages from the queuing system back into a Quagga bgpd for the looking glass, MRT RIB dump generator etc, if we wanted to :-) Regards, Colin
Paul Jakma •
Yeah, I can see the advantages in "componentising" the architecture. It'd be nice to try slowly do something in Quagga bgpd over time, to "libify" portions, and to make it easier to deploy as a toolkit of stuff. Quagga bgpd isn't there now, and I can see the attraction of the above, sure. It's just the "Collector Scaling Issues" section and the section stating "The current Quagga implementation is single-threaded which is not as scalable on modern multi-core CPUs" is just a little frustrating, when the primary scaling mechanism you've adopted - running multiple BGP speaker processes - applies to Quagga equally well.