

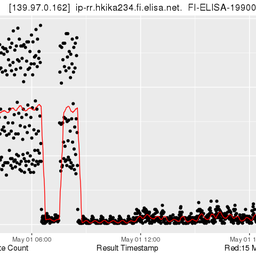
On Wednesday 13 June 2012, an unknown error caused the removal of several zone files from the configuration of our reverse DNS provisioning system. Following up from the initial report published on RIPE Labs, we further analysed what caused the incident and implemented a number of procedures to decrease the likelihood of this happening in the future.
Due to a combination of human error, software failure and procedural faults, this incident had an impact on reverse DNS resolution for a large number of delegations. For details, please refer to the previous report on RIPE Labs: Timeline of Reverse DNS Events .
Root cause of incident not found
Despite a thorough analysis of this incident we could not find an explanation for the root cause (the removal of the zones). A potential correlation with a BIND upgrade, earlier on the same day, was investigated in depth, together with the supplier. However, we could not find any evidence that this caused the incident. It is very unsatisfying that we still don't know what caused this event. Therefore we are working to install more logging mechanisms, including logging of command-line activities (comparable to an in-flight "black box"). Obviously, we will do this step by step and with due consideration of security aspects.
Technical and procedural enhancements
As reported earlier, zone files from DNS provisioning system were missing from the backup scheme. This error had been overlooked in a previous transition of the backup configuration. In order to prevent this from happening again, we introduced a number of procedural enhancements such as establishing a process to regularly review the availability and usability of backup files for all systems and re-enforcing the four-eyes principle for any major changes, especially for any non-routine events.
We also realised that the provisioning system took too long to complete a cold start, and Early Registration Transers ( ERX ) delegations took even longer, because raw information of ERX zones was not tailored for the use of cold-start provisioning. We are now building a 'lean' provisioning system for cold-start scenarios, including ERX delegations. We also changed the mechanism for creating and distributing files at a cold start of the provisioning software, i.e. no incremental zone updates.
Communications
This incident also showed us that we need to be reachable at all times and not just through email. In November, we launched the RIPE NCC Technical Emergency Hotline. In addition to that, we improved our critical incident communication procedures to ensure that the community receives immediate and regular updates when an incident occurs, even if it’s just to report that something’s happened and we’re investigating. In the event of a serious outage or security incident, we email the RIPE community and RIPE NCC members, update the Service Announcements page on www.ripe.net , post a news announcement on the front page and spread the word on our social media platforms (@RIPE_NCC on Twitter, facebook.com/RIPENCC and the RIPE community group on LinkedIn).
Summary
The reverse DNS incident that took place on 13 June exposed a number of gaps in our procedures, as well as some faults in our software. Even though it is unsatisfying that we could not identify the root cause, we learned from this incident and included additional checks and safety measures and improved our communication procedures. We will continue our policy of openness about such incidents, because we feel that it is appreciated by the community.

Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.