
With last month’s cuts in two major Baltic Sea Internet cables now successfully repaired, and another cut having occurred in the meantime, we analyse these events and delve deeper into the question of how exactly the Internet has remained resilient.
In November, we shared our preliminary analysis of the analysis of the Baltic Sea cable cuts. Digging into the results of ping mesh measurements routinely performed by RIPE Atlas anchors, we were able to provide an initial sketch of how this affected connectivity between the countries at both ends of both cables.
According to that sketch, changes in latency and packet loss were actually quite minimal. In fact, we didn’t detect extra packet loss at all, and only a small portion of the path (20-30%) had measurable latency increases. It therefore seems to us that the Internet once again did what it was designed to do and routed around the damage.
But what underpins this resilience? How exactly does the Internet adjust when one path gets cut off? In this article, we take a closer look at data around the Baltic Sea cable cuts to explore different layers of resiliency in Internet routing.
In the meantime
Before we move on, let’s start by zooming in on a few relevant events that happened since the initial Baltic Sea cable cuts occurred on 17 and 18 November.
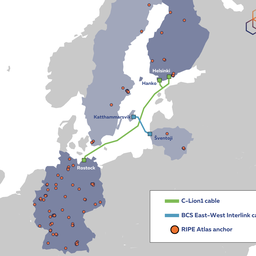
Finland-Sweden terrestrial cable cut
Though Internet cable cuts are not all that rare, the current geopolitical situation meant the Baltic Sea cable incidents became headline news and speculation is still rife as to whether this was an act of sabotage, though some voices argue this was unlikely to have been a deliberate act. It was therefore no surprise that when another terrestrial cable connecting Sweden and Finland was cut on 3 December, this also made the news.
Applying our RIPE Atlas anchor-mesh latency analysis to that terrestrial cable cut, we detected a notable increase in latency around 03:15 UTC (Figure 1). Changes in latency like this are a tell-tale sign of changes in end-to-end connectivity due to such events as cable cuts. Roughly 5% of paths between Finnish and Swedish anchors were affected and, in this case, we also saw some noteworthy changes in packet loss.
Interestingly, there wasn’t much information out there about the exact timing of the event, but the fact that we saw evidence of a prolonged latency increase between some anchors in Finland and Sweden at the indicated time is a good example of how we can track events like this when there are enough RIPE Atlas anchors observing the affected infrastructure.


C-Lion1 repair
On 28 November 2024 at 17:30 UTC, the C-Lion1 cable repair ship reported leaving the area after successful repair. We repeated our analysis again, focussing on Finland-Germany anchor pairs at the reported repair time, and as you would expect, we saw evidence of the cable being put back into use again:

Figure 3 is an example of how we can see latency changes for paths between RIPE Atlas anchors in Finland and an anchor in Germany. This is just one instance, and we see many latency profiles not changing, but this what’s shown here is fairly typical of the changes we observe - i.e., a large latency spike around 21:00 and some paths shifting to a lower latency.
If we look at the aggregate packet loss between the anchors in Finland and Germany (Figure 4) we see a temporary increase in loss that correlates with the latency spike in Figure 3 at around 21:00 UTC on 29 November.

It's unclear what exactly causes these latency effects and the temporary increase in packet loss. We would love to hear from experts in the industry how this works. Could it be a side effect of how a cable gets reactivated again at the circuit level? Or is what we see here caused by a "thundering herd" of connections over the reactivated path, causing all the TCP connections to ramp up so as to get as much bandwidth as is available?
A deeper dive into the Baltic Sea cable cuts
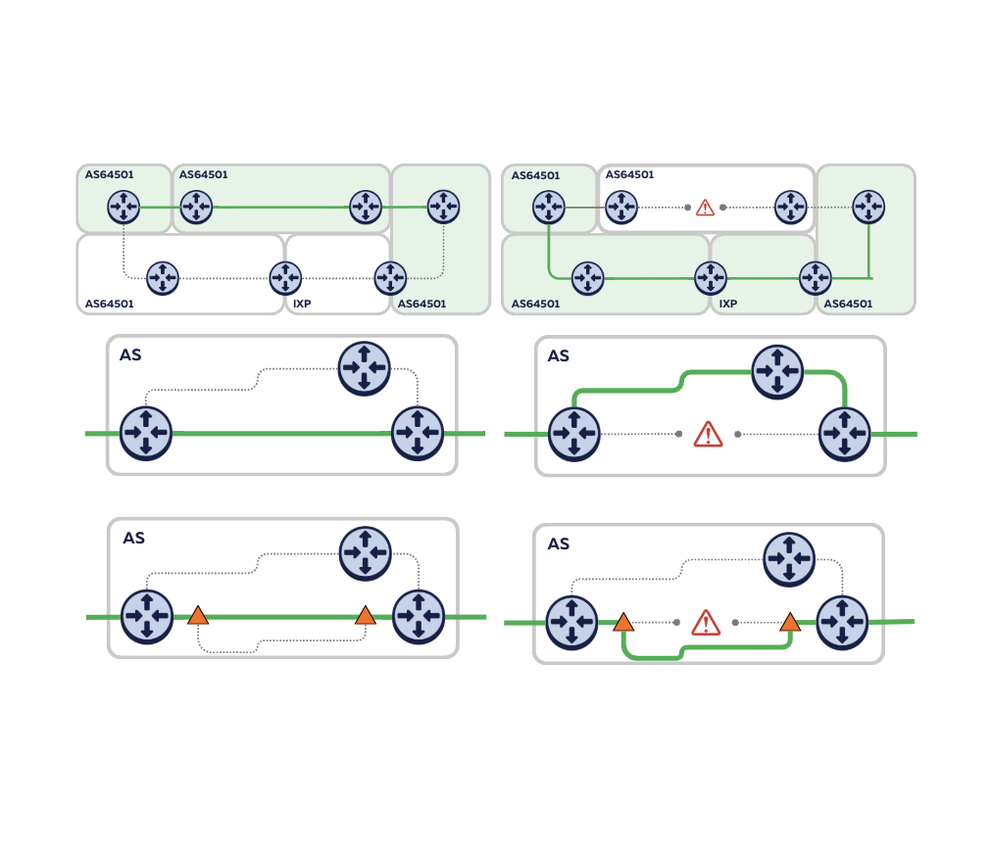
Coming back to the original cable cuts of 17-18 November, we started diving deeper into the data that the RIPE Atlas anchor mesh collected. Our initial analysis was based on ping (end-to-end latency) data, and in this more in depth analysis that follows we will be using traceroute data, to examine how the paths actually changed while end-to-end connectivity was maintained. More specifically, we look at the resiliency at these three different levels:
- Inter-domain rerouting - between networks (ASes)
- Intra-domain rerouting - within networks
- Circuit-level rerouting - within links between routers (also known as path protection)

How did things actually get rerouted - traceroute analysis
Traceroutes show end-to-end latency, but they also show latencies for devices on the forward path between source and destination anchors. Or more precisely we see latencies between the source of our measurement (the RIPE Atlas anchor) and IP addresses for devices on the path toward the destination (another RIPE Atlas anchor). We use this (as detailed in footnote 1) to classify both forward and reverse paths between RIPE Atlas anchors in Finland and Germany, focussing on latency changes for each of the three levels of resilience described in Figure 5. We use data for this particular cable cut because we have independent evidence of the cable being repaired and this cable cut had the most RIPE Atlas anchors at each end of the cable: 100 in Germany and 12 in Finland. Figure 6 gives an overview of latency effects we saw.

Internet routing is designed to route traffic along the best path. When that best path becomes unavailable, an alternative is selected, which often has a higher latency. The plots in Figure 6 show evidence of significant latency changes (changes of over 3ms, highlighted by the orange areas) relative to the baseline. As you can see in all three categories, there are paths with increased latency, which indicates that we see multiple levels of resilience in action.
Of the 2,141 bidirectional paths between RIPE Atlas anchors in Germany and Finland that we used for this analysis, we get the following break down across our three categories:
Inter-domain changes for 637 anchor pairs (29.8%)
Inter-domain rerouting is what you’d typically think of when talking about routing around damage. BGP, the inter-domain routing protocol, was designed to do so. And out of the total set of anchor pairs, we do see 29.8% where the networks on the paths are different after the cut, as compared to the baseline before the cut. Some part of this will be the inevitable churn in inter-domain routing, but we clearly see a large part of this (25%) has an increased latency of over 3 milliseconds. We chose 3 ms as a conservative cut-off for increased latency. If latency changes were distributed at random, you would see an equal amount of anchor pairs that see decreased latency (the start of the graph), and we clearly don’t see this. So the asymmetry of this graph is evidence of a state change correlated with the cable cut. We expect that with further calibration in the future we can increase robustness of the methodology about what fraction of the inter-domain rerouting is usual churn on the Internet and what fraction is related to a specific event.
Intra-domain changes for 1,044 anchor pairs (48.8%)
Next we look at differences in the IP addresses seen after the cut, relative to the baseline before the event. We see 48.8% of anchor pairs where we don’t see network-level changes, but we do see changes at the IP address level. Again, some of this will be churn in intra-domain routing, not related to the cable cut, but for 38% of these we additionally see a latency increase of 3 ms or more. With some margin for noise, these represent the paths were intra-domain routing caused ‘routing around damage’, with no inter-domain routing protocol involved.
No inter-domain and intra-domain changes for 460 anchor pairs (21.5%)
The final set of paths that we consider in the rightmost plot have identical IP addresses before and after the cut. These paths look unchanged, if we only consider the IP-level information. We can’t directly map the IP level path onto what cables are being used for them (this information is private to the individual network that uses the IP addresses on their routers), but we can see if the path latency differs before and after the cut, at a distinct bump at a little over 3 ms. For 5.2% of these paths, we do see latency increases of 3 ms or more, which indicates circuit-level changes. While these could be physical layer, this could also be caused by virtual-circuit technologies like MPLS.
While 3 ms may not seem much, it is notable and corresponds to roughly 300 km of round-trip over fibre and suggests rerouting taking place at the circuit level. These extra 300 km might hint at a terrestrial back-up path taking over from the broken C-Lion1 cable.
Our understanding of this part of the industry is limited, but from conversations with network operators we know that many circuits can and will be offered with a backup path ("protected") or without ("unprotected") depending on if the cable operator will provide a backup-path in case the primary path gets disrupted. These backup paths should be running on different fibre strands in different ducts, and via different geographical paths, to hedge against the risk of disruption, for instance due to digging during roadworks, scavenging for copper, etc.
Which networks were involved in rerouting?
Now that we have network-level information that we retrieved from traceroutes, we can also see if there are networks (IXPs or ASes) that lost or gained paths after the cable cut in as far as we can see between RIPE Atlas anchors.
In total, we have 100 ASes that host an anchor in this analysis, and a total of 89 ASes and 49 IXPs that we see on the paths between them. In table 1, we show the top 10 networks in terms of change. Please note that this is very specific to our pool of RIPE Atlas anchors and the specific event, and should not be taken as an indication of quality for the involved networks. Instead we want to show this to give an indication of the diversity of network paths available.
| ASN / IXP | pre event count | difference |
|---|---|---|
| DE-CIX Frankfurt | 1,352 | -39 |
| AS47605 | 1,125 | 81 |
| AS6667 | 958 | -1 |
| AS1299 | 849 | 0 |
| AS24940 | 603 | 71 |
| AS9002 | 491 | 1 |
| AS208722 | 473 | 0 |
| AS13238 | 469 | 1 |
| AS719 | 452 | 0 |
| AS6939 | 441 | -6 |
The DE-CIX Frankfurt IXP LAN is seen in most paths, which is not a surprise given the prominence of this IXP LAN, but also given the fact that we have 100 anchors in Germany versus 12 anchors in Finland that contribute to this analysis - i.e. the analysis is biased towards Germany relative to Finland due to this number difference. Another interesting observation here is that many networks in this top 10 hardly see any change pre/post event.
| ASN / IXP | pre event count | difference |
|---|---|---|
| AS2603 | 366 | 167 |
| AS47605 | 1,125 | 81 |
| AS24940 | 603 | 71 |
| FICIX 2 Helsinki | 89 | 47 |
| AMS-IX | 151 | 41 |
| DE-CIX Frankfurt | 1,352 | -39 |
| AS1759 | 44 | -29 |
| AS680 | 250 | 11 |
| AS20965 | 25 | 11 |
| AS2914 | 74 | 8 |
AS2603 NORDUnet, the Scandinavian NREN, saw the most change. An additional 167 paths were seen post-event, on top of the 899 that were seen before the cable cut. Next is AS47605 FNE, a Finnish transit network, which was seen on 2,331 paths pre-event, and after event an additional 81 paths were seen. AS24940 Hetzner follows at 1,277 pre and 71 extra post-event. In this case, it is worth mentioning that Hetzner is a network based out of Germany, but crucially, we have a RIPE Atlas anchor hosted in Finland in the Hetzner network. The fact that this network is seen so often is an example of the bias that our analysis has in favor of networks hosting a RIPE Atlas anchor. With more diversity per country this bias decreases.
After these three ASNs, we see three IXPs with significant changes. FICIX 2 Helsinki (baseline 89, increasing by 47), AMS-IX (baseline 151, increasing by 47), and DE-CIX Frankfurt (baseline 2665, decreasing by 39). DE-CIX Frankfurt mediates a lot of paths between Anchors in Germany and Finland, so it’s no surprise that it is affected. And the fact that a few other IXP LANs pick up change is the sort of "waterbed effect" we saw in earlier analyses with regards to routing around damage.
One other thing that is fascinating is the diversity of IXP LANs we see. We see a total of 49 different IXP LANs in a dozen countries. Given the length of the relevant table, we moved this to footnote 2. We denoted the IXP LANs that we know are in facilities in multiple countries in the table below, in these cases it is less clear, or even unlikely that paths traversed the specific country that the IXP LAN is registered at, per PeeringDB data.
Some of the IXP LANs that are seen are surprisingly far to the east and west. Furthest the east we have MSK-IX in Moscow, Russia, and to the west we have NYIIX in New York, USA. The MSK-IX paths are correlated with the Yandex Finland RIPE Atlas anchor, and NYIIX is caused by AS2603 NorduNET handing off traffic there to AS201011. Even if the speculation about the cable cut being deliberate were true, we currently can’t find evidence of an act like this having effects like forcing paths into a certain direction. For both paths via NYIIX and MSK-IX we see the same number of paths before and after the cut.
In praise of resilience
Part of the RIPE NCC's mission is to actively contribute to the stability and evolution of the Internet, by serving the community as a neutral source of information and knowledge. The RIPE Atlas Anchor mesh measurements have been running for many years, and can provide very fine-grained insight into how the Internet is performing in response to different kinds of threats.
As for the measurability of this type of event, we were lucky with the amount of RIPE Atlas anchors deployed in this region, as 100 anchors in Germany and 12 anchors in Finland provided a useful and diverse enough wealth of data to analyse to do a deep dive. The table in footnote 3 shows the current deployment on a per country-level and diversity in terms of the number of cities and networks RIPE Atlas anchors are deployed at. If we consider five RIPE Atlas anchors with some diversity in geography and topology (i.e., in different networks and different physical locations) the bare minimum per country there is some work to do to get this measurement capability in all of our service region, and more ambitiously, worldwide.
In the case of the Baltic Sea cable cuts, measurements from the RIPE Atlas anchors reveal something important - Internet resilience emerges naturally from multiple layers of provisioning redundancy. At the lowest level, protected circuits allow automated failover when one path is damaged. Organisations build their own internal networks using many such connections, allowing traffic to bypass damage to a single point of presence. And if an entire organisation becomes impassable, inter-domain routing naturally kicks in to allow other organisations to take their place in delivering end-to-end traffic.
We saw evidence of all of these mechanisms at work in the seconds following the Baltic Sea cable cuts, working together to provide natural defence in depth against local damage. And after the damage is repaired, similar mechanisms returned the network to something much like its original state, in which all of the provisioning factors affecting traffic delivery are once again balanced: cost, reliability, latency, throughput. It's remarkable to watch it in action.
We can think of resilience as a reservoir of alternatives that are "filled" according to expectations for redundancy. Providers can use protected circuits. They can build redundant networks among the cities where they have points of presence. They can purchase transit from multiple providers and can participate in peering at multiple IXPs. All of those choices fill the reservoir of alternatives, so that there were many good choices to draw from in order to route around damage in the early seconds of an event.
This raises a natural question: what would it take to cause a more serious European Internet outage? It is somewhat reassuring that it is really complex to model this, raising the question if it be done at all, due to the multiple levels of resiliency. In practice, the only way to really plumb the depths of the reservoir is to observe the network's response to damage at various scales and measure the impacts, as we do every day with the RIPE Atlas mesh measurements.
It's possible to imagine an alternative future for the Internet in which cost pressures erode the Internet's traditional engineering bias toward redundancy, or in which platform centralisation brings "too many" critical services within the network footprint of "too few" organisations. For now, though, the reassuring data measured during the Baltic Sea cable cuts suggest that this small region of the European Internet maintains an ample reservoir of decentralised connectivity, built from inter-provider transit diversity and interconnection at geographically diverse IXPs. Measuring and monitoring these resiliency trends can be an important collaborative goal for industry, government, and the RIPE NCC community.
Footnotes
1. Traceroute methodology
Normally in a traceroute, you only have the forward path, but since our anchors are used as sources and destinations, we have both directions. This is important because, when it comes to Internet routing, the path there and the path back are typically not the same. If we combine traceroutes in both directions we can look at network and IP changes in both directions between each anchor pair. We use this to distinguish between the three types of rerouting shown in Figure 5. For the traceroutes we use PeeringDB and IPInfo data to map IP addresses to IXPs and ASNs. Note that IP to AS mapping is not always 100% accurate, but should be accurate enough to get a picture of the networks that a path traverses. Note that we have a bidirectional path per address family, and as most anchors are on both IPv4 and IPv6 we typically have two bidirectional paths per anchor pair.
We compare traceroute data over two periods: a period of four hours ending 15 minutes before the event which is our baseline, and one period of four hours starting 15 minutes after the event, which represents the changed state of the network after the cable cut. Note that comparing these periods gives us an upper bound for the changes that happened due to the cable cut, since other path changes could have happened during our observation time that are not related to the cable cut.
We treat IXP peering LANs as separate networks in what we call a 'network-level' path - i.e., the sequence of IXPs and ASes we see. So for each anchor pair we have a forward and reverse network-level path, and if we see any change between pre- and post-event networks in either forward or reverse path we classify this as inter-domain rerouting between this pair of anchors. For intra-domain rerouting, we consider all the anchor pairs where the networks did not change pre and post-event, but the set of IP addresses we see did. All anchor pairs that are not in the first two categories, but do see latency changes we classify as circuit-level rerouting.
2. Table showing pre and post-event path counts per IXP
| IXP | baseline count | post event count | annotation |
|---|---|---|---|
| Germany | |||
| DE-CIX Frankfurt | 1,352 | 1,313 | |
| BCIX | 102 | 104 | |
| DE-CIX Hamburg | 80 | 80 | |
| DE-CIX Dusseldorf | 65 | 65 | |
| DE-CIX Munich | 63 | 59 | |
| MegaIX Hamburg | 56 | 55 | |
| MegaIX Dusseldorf | 30 | 30 | |
| Community-IX | 28 | 28 | |
| MegaIX Frankfurt | 21 | 22 | |
| LOCIX Frankfurt | 18 | 18 | |
| Equinix Frankfurt | 8 | 8 | |
| Stuttgart-IX | 5 | 5 | |
| N-IX | 4 | 4 | |
| KleyReX | 4 | 2 | |
| BREM-IX | 3 | 3 | |
| MegaIX Munich | 3 | 3 | |
| MegaIX Berlin | 3 | 3 | |
| STACIX | 1 | 1 | |
| DE-CIX Leipzig | 0 | 1 | |
| Netherlands | |||
| AMS-IX | 151 | 192 | |
| DATAIX | 145 | 146 | (multi-country LAN) |
| NL-ix-Main | 26 | 26 | (multi-country LAN) |
| Global-IX | 11 | 12 | |
| Frys-IX | 6 | 6 | |
| Asteroid Amsterdam | 2 | 2 | |
| Speed-IX | 2 | 2 | |
| Sweden | |||
| SONIX Stockholm | 70 | 70 | |
|
Netnod Stockholm GREEN/A/MTU1500 |
57 | 58 | |
|
Netnod Stockholm BLUE/B/MTU1500 |
21 | 22 | |
| SOLIX MTU1500 | 17 | 17 | |
|
Netnod Stockholm BLUE/B/MTU4470 |
5 | 5 | |
|
Netnod Stockholm GREEN/A/MTU4470 |
3 | 3 | |
| STHIX - Stockholm-STH Peering | 1 | 1 | |
| Finland | |||
| FICIX 2 (Helsinki)/MTU1500 | 89 | 136 | |
| FICIX 1 (Espoo)/MTU1500 | 11 | 11 | |
| Equinix Helsinki | 4 | 5 | |
| PITER-IX Helsinki | 2 | 2 | |
| Russia | |||
| MSK-IX Moscow | 7 | 7 | |
| PITER-IX Moscow | 6 | 6 | |
| Switzerland | |||
| SwissIX | 2 | 2 | |
| CHIX | 1 | 1 | |
|
Great Brittain |
|||
| LINX LON1 | 27 | 29 | |
| LONAP LON0 | 2 | 2 | |
| Austria | |||
| VIX | 2 | 2 | |
| Bulgaria | |||
| NetIX | 18 | 12 | (multi-country LAN) |
| France | |||
| France-IX Paris | 1 | 2 | |
| Denmark | |||
| DIX LAN | 2 | 2 | |
| USA | |||
| NYIIX New York | 2 | 2 | |
| Poland | |||
| Equinix Warsaw | 2 | 2 |
3. RIPE Atlas anchors per country and indication of city and network diversity
| cc | anchor count | city count | asn count |
| AF | 1 | 1 | 1 |
| AX | 0 | 0 | 0 |
| AL | 1 | 1 | 1 |
| DZ | 0 | 0 | 0 |
| AS | 0 | 0 | 0 |
| AD | 0 | 0 | 0 |
| AO | 1 | 1 | 1 |
| AI | 0 | 0 | 0 |
| AQ | 0 | 0 | 0 |
| AG | 0 | 0 | 0 |
| AR | 6 | 6 | 6 |
| AM | 1 | 1 | 1 |
| AW | 0 | 0 | 0 |
| AU | 24 | 7 | 19 |
| AT | 24 | 8 | 23 |
| AZ | 0 | 0 | 0 |
| BS | 0 | 0 | 0 |
| BH | 1 | 1 | 1 |
| BD | 1 | 1 | 1 |
| BB | 0 | 0 | 0 |
| BY | 1 | 1 | 1 |
| BE | 7 | 6 | 5 |
| BZ | 0 | 0 | 0 |
| BJ | 0 | 0 | 0 |
| BM | 0 | 0 | 0 |
| BT | 0 | 0 | 0 |
| BO | 0 | 0 | 0 |
| BQ | 0 | 0 | 0 |
| BA | 2 | 2 | 2 |
| BW | 0 | 0 | 0 |
| BV | 0 | 0 | 0 |
| BR | 16 | 9 | 16 |
| IO | 0 | 0 | 0 |
| BN | 0 | 0 | 0 |
| BG | 8 | 4 | 7 |
| BF | 1 | 1 | 1 |
| BI | 0 | 0 | 0 |
| KH | 1 | 1 | 1 |
| CM | 1 | 1 | 1 |
| CA | 19 | 10 | 18 |
| CV | 0 | 0 | 0 |
| KY | 0 | 0 | 0 |
| CF | 0 | 0 | 0 |
| TD | 0 | 0 | 0 |
| CL | 8 | 3 | 7 |
| CN | 2 | 1 | 2 |
| CX | 0 | 0 | 0 |
| CC | 0 | 0 | 0 |
| CO | 2 | 1 | 2 |
| KM | 0 | 0 | 0 |
| CG | 0 | 0 | 0 |
| CD | 0 | 0 | 0 |
| CK | 0 | 0 | 0 |
| CR | 1 | 1 | 1 |
| CI | 0 | 0 | 0 |
| HR | 1 | 1 | 1 |
| CU | 0 | 0 | 0 |
| CW | 0 | 0 | 0 |
| CY | 0 | 0 | 0 |
| CZ | 14 | 2 | 13 |
| DK | 8 | 7 | 8 |
| DJ | 0 | 0 | 0 |
| DM | 0 | 0 | 0 |
| DO | 4 | 4 | 4 |
| EC | 1 | 1 | 1 |
| EG | 0 | 0 | 0 |
| SV | 0 | 0 | 0 |
| GQ | 0 | 0 | 0 |
| ER | 0 | 0 | 0 |
| EE | 3 | 1 | 3 |
| ET | 0 | 0 | 0 |
| FK | 0 | 0 | 0 |
| FO | 0 | 0 | 0 |
| FJ | 0 | 0 | 0 |
| FI | 13 | 8 | 13 |
| FR | 49 | 28 | 46 |
| GF | 0 | 0 | 0 |
| PF | 0 | 0 | 0 |
| TF | 0 | 0 | 0 |
| GA | 0 | 0 | 0 |
| GM | 0 | 0 | 0 |
| GE | 4 | 2 | 4 |
| DE | 119 | 52 | 102 |
| GH | 2 | 2 | 2 |
| GI | 0 | 0 | 0 |
| GR | 6 | 4 | 6 |
| GL | 0 | 0 | 0 |
| GD | 0 | 0 | 0 |
| GP | 0 | 0 | 0 |
| GU | 0 | 0 | 0 |
| GT | 1 | 1 | 1 |
| GG | 0 | 0 | 0 |
| GN | 0 | 0 | 0 |
| GW | 0 | 0 | 0 |
| GY | 0 | 0 | 0 |
| HT | 0 | 0 | 0 |
| HM | 0 | 0 | 0 |
| VA | 0 | 0 | 0 |
| HN | 1 | 1 | 1 |
| HK | 5 | 1 | 5 |
| HU | 2 | 2 | 2 |
| IS | 2 | 1 | 2 |
| IN | 10 | 9 | 9 |
| ID | 14 | 9 | 11 |
| IR | 9 | 4 | 9 |
| IQ | 1 | 1 | 1 |
| IE | 2 | 2 | 2 |
| IM | 1 | 1 | 1 |
| IL | 2 | 2 | 2 |
| IT | 24 | 17 | 22 |
| JM | 0 | 0 | 0 |
| JP | 13 | 2 | 12 |
| JE | 0 | 0 | 0 |
| JO | 0 | 0 | 0 |
| KZ | 16 | 13 | 4 |
| KE | 2 | 1 | 2 |
| KI | 0 | 0 | 0 |
| KP | 0 | 0 | 0 |
| KR | 3 | 1 | 3 |
| XK | 0 | 0 | 0 |
| KW | 1 | 1 | 1 |
| KG | 1 | 1 | 1 |
| LA | 0 | 0 | 0 |
| LV | 2 | 1 | 2 |
| LB | 0 | 0 | 0 |
| LS | 0 | 0 | 0 |
| LR | 0 | 0 | 0 |
| LY | 0 | 0 | 0 |
| LI | 0 | 0 | 0 |
| LT | 5 | 3 | 5 |
| LU | 8 | 4 | 7 |
| MO | 0 | 0 | 0 |
| MK | 3 | 2 | 3 |
| MG | 0 | 0 | 0 |
| MW | 0 | 0 | 0 |
| MY | 2 | 1 | 2 |
| MV | 1 | 1 | 1 |
| ML | 0 | 0 | 0 |
| MT | 0 | 0 | 0 |
| MH | 0 | 0 | 0 |
| MQ | 0 | 0 | 0 |
| MR | 0 | 0 | 0 |
| MU | 2 | 2 | 2 |
| YT | 0 | 0 | 0 |
| MX | 6 | 5 | 5 |
| FM | 0 | 0 | 0 |
| MD | 2 | 1 | 2 |
| MC | 0 | 0 | 0 |
| MN | 1 | 1 | 1 |
| ME | 0 | 0 | 0 |
| MS | 0 | 0 | 0 |
| MA | 0 | 0 | 0 |
| MZ | 1 | 1 | 1 |
| MM | 0 | 0 | 0 |
| NA | 0 | 0 | 0 |
| NR | 0 | 0 | 0 |
| NP | 1 | 1 | 1 |
| NL | 49 | 22 | 46 |
| NC | 1 | 1 | 1 |
| NZ | 6 | 2 | 6 |
| NI | 0 | 0 | 0 |
| NE | 0 | 0 | 0 |
| NG | 0 | 0 | 0 |
| NU | 0 | 0 | 0 |
| NF | 0 | 0 | 0 |
| MP | 0 | 0 | 0 |
| NO | 7 | 4 | 7 |
| OM | 0 | 0 | 0 |
| PK | 2 | 1 | 2 |
| PW | 0 | 0 | 0 |
| PS | 0 | 0 | 0 |
| PA | 1 | 1 | 1 |
| PG | 1 | 1 | 1 |
| PY | 1 | 1 | 1 |
| PE | 3 | 2 | 3 |
| PH | 3 | 3 | 3 |
| PN | 0 | 0 | 0 |
| PL | 13 | 8 | 13 |
| PT | 5 | 2 | 5 |
| PR | 0 | 0 | 0 |
| QA | 0 | 0 | 0 |
| RE | 0 | 0 | 0 |
| RO | 7 | 4 | 6 |
| RU | 28 | 13 | 24 |
| RW | 0 | 0 | 0 |
| BL | 0 | 0 | 0 |
| SH | 0 | 0 | 0 |
| KN | 0 | 0 | 0 |
| LC | 0 | 0 | 0 |
| MF | 0 | 0 | 0 |
| PM | 0 | 0 | 0 |
| VC | 0 | 0 | 0 |
| WS | 0 | 0 | 0 |
| SM | 0 | 0 | 0 |
| ST | 0 | 0 | 0 |
| SA | 3 | 2 | 3 |
| SN | 0 | 0 | 0 |
| RS | 4 | 2 | 4 |
| SC | 0 | 0 | 0 |
| SL | 0 | 0 | 0 |
| SG | 28 | 2 | 28 |
| SX | 1 | 1 | 1 |
| SK | 1 | 1 | 1 |
| SI | 3 | 1 | 3 |
| SB | 0 | 0 | 0 |
| SO | 0 | 0 | 0 |
| ZA | 12 | 3 | 11 |
| GS | 0 | 0 | 0 |
| SS | 0 | 0 | 0 |
| ES | 12 | 7 | 11 |
| LK | 0 | 0 | 0 |
| SD | 0 | 0 | 0 |
| SR | 0 | 0 | 0 |
| SJ | 0 | 0 | 0 |
| SZ | 0 | 0 | 0 |
| SE | 16 | 7 | 14 |
| CH | 35 | 16 | 31 |
| SY | 0 | 0 | 0 |
| TW | 5 | 2 | 5 |
| TJ | 1 | 1 | 1 |
| TZ | 1 | 1 | 1 |
| TH | 2 | 2 | 2 |
| TL | 0 | 0 | 0 |
| TG | 0 | 0 | 0 |
| TK | 0 | 0 | 0 |
| TO | 0 | 0 | 0 |
| TT | 1 | 1 | 1 |
| TN | 0 | 0 | 0 |
| TR | 13 | 6 | 12 |
| TM | 0 | 0 | 0 |
| TC | 0 | 0 | 0 |
| TV | 0 | 0 | 0 |
| UG | 1 | 1 | 1 |
| UA | 15 | 10 | 14 |
| AE | 11 | 3 | 10 |
| GB | 45 | 20 | 41 |
| US | 152 | 72 | 102 |
| UM | 0 | 0 | 0 |
| UY | 2 | 1 | 2 |
| UZ | 1 | 1 | 1 |
| VU | 0 | 0 | 0 |
| VE | 3 | 3 | 3 |
| VN | 2 | 1 | 2 |
| VG | 0 | 0 | 0 |
| VI | 0 | 0 | 0 |
| WF | 0 | 0 | 0 |
| EH | 0 | 0 | 0 |
| YE | 0 | 0 | 0 |
| ZM | 0 | 0 | 0 |
| ZW | 0 | 0 | 0 |

Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.