
This new RIPE Labs article talks about trying to send large packets over the Internet. Above a certain size, these packets will have to be fragmented, which is known to cause problems. In both IPv4 and IPv6, we see approximately 10% of RIPE Atlas probes that are unsuccessful in pings with fragmented packets, while they don't encounter problems with smaller unfragmented packets.
Because most of today's end user Internet connections are Ethernet based, the maximum size of IP packets leaving these end user machines is typically 1,500 bytes (the Maximum Transmission Unit (MTU) of Ethernet). If these large packets have to be sent through links where they won't fit (i.e.where the link MTU is smaller then the packet size) this can become a problem. Routers solve this in 2 possible ways:
A) A packet that is too big is split up in smaller packets at that point ("fragmentation").
B) The packet is discarded and a control message ("Packet Too Big" or PTB) is sent to the originator of the packet. This causes the originator to fragment the packet into smaller pieces.
Option B is what happens for IPv4 packets that have the "Don't Fragment" (DF) bit set, option A in other cases. In IPv6 option B is the only allowed option. The "Packet Too Big" (PTB) message typically contains the maximum packet size that is allowed for the link the router wanted to sent the packet through. If a sender receives a PTB for a given destination it will cache that path MTU information for a short time.
If devices between end-points filter these fragmented packets or the PTB control messages, fragmentation fails, resulting in
potentially hard to debug problems
.
What we did is send increasing sizes of ICMP packets from all RIPE Atlas probes available to a well behaving host and see how much we got back. If we didn't get any response for a bigger packet size, but we did receive responses for smaller packet sizes, that's a sign of problems with fragmentation. We spaced out each measurement by at least 10 minutes to make sure path MTU information wasn't cached. The exact measurement setup is described in Footnote 1.
Initial results of this type of experiment were sent to the NANOG mailing list. However, we got largely varying numbers of RIPE Atlas probes taking these tests, so we repeated this experiment 3 times, and took the result with the most RIPE Atlas probes taking part in the measurement. We looked at how many ICMP echo reply responses RIPE Atlas probes received from sending 10 ICMP echo requests in both IPv4 and IPv6. Because the ICMP echo reply is going to be of the same size as the echo request, this tests the effect of fragmentation of both the forward and reverse path.
IPv4
Table 1 below shows results for sending 10 ICMP echo reply requests for various IPv4 packet sizes.
| IPv4 packet size | all lost | 10/10 received | 9/10 received | 8/10 received | 1/10-7/10 received | number of probes |
| 100 | 1.0% | 95.6% | 2.2% | 0.6% | 0.6% | 3627 |
| 700 | 1.4% | 95.0% | 2.5% | 0.7% | 0.5% | 3629 |
| 1000 | 1.4% | 95.1% | 2.2% | 0.7% | 0.6% | 3626 |
| 1400 | 2.1% | 96.0% | 1.2% | 0.4% | 0.4% | 3611 |
| 1401 | 2.4% | 93.1% | 3.2% | 0.7% | 0.7% | 3616 |
| 1454 | 2.4% | 92.6% | 3.6% | 0.6% | 0.8% | 3625 |
| 1455 | 2.5% | 90.2% | 5.3% | 1.2% | 0.8% | 3626 |
| 1460 | 2.6% | 92.9% | 3.3% | 0.5% | 0.6% | 3614 |
| 1461 | 2.8% | 90.0% | 5.8% | 0.9% | 0.6% | 3624 |
| 1480 | 2.9% | 89.1% | 6.2% | 1.0% | 0.8% | 3629 |
| 1481 | 3.0% | 88.2% | 7.3% | 0.8% | 0.7% | 3631 |
| 1488 | 3.0% | 88.9% | 6.7% | 0.9% | 0.5% | 3619 |
| 1489 | 3.1% | 88.5% | 6.8% | 0.9% | 0.7% | 3624 |
| 1492 | 3.1% | 88.2% | 7.1% | 0.9% | 0.7% | 3624 |
| 1493 | 5.1% | 71.3% | 20.2% | 2.8% | 0.7% | 3619 |
| 1500 | 5.2% | 71.0% | 20.8% | 2.3% | 0.6% | 3618 |
| 1501 | 9.9% | 85.3% | 2.7% | 0.6% | 1.5% | 3620 |
| 1502 | 9.9% | 84.8% | 2.4% | 1.0% | 1.9% | 3620 |
| 1600 | 9.8% | 84.9% | 2.7% | 1.0% | 1.5% | 3626 |
Table 1: Echo reply requests for various IPv4 packet sizes
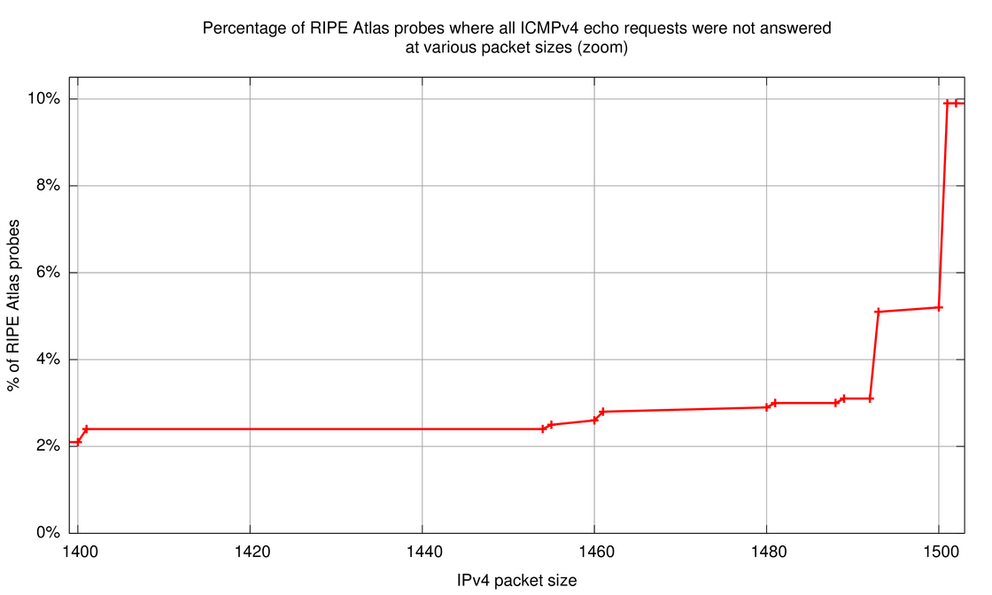
The 'all lost' column is indicative of where real problems occur; the data in this column is plotted in Figure 1 and Figure 2 further below. We have a baseline of about 1 - 1.5% of RIPE Atlas probes that don't receive any responses at IPv4 packet sizes of 100 to 1,000 bytes. With packets above 1,400 bytes the number of extra RIPE Atlas probes that never receive ping responses becomes significant. The most significant jump is from 1,500 byte IPv4 packets (5.2% of probes get no responses), to 1,501 byte IPv4 packets (9.9% of probes get no responses), the difference being about 5%! Because our target has a link MTU of 1,500 the packets at 1,501 are all fragmented.
Also interesting to note are the cases where the RIPE Atlas probe receives 9 out of 10 responses (middle column in Table 1). This is a tell-tale sign of path MTU discovery in process: Because non-fragmented packets are sent out with the DF bit on, any packet that encounters a packet size bottleneck will be dropped at the router just before that bottleneck. At the same time this router will send a PTB back. Since RIPE Atlas probes don't retransmit that dropped packet it will be lost. If the PTB message makes it back to the RIPE Atlas probe, the probe will cache the newly found path MTU, which is typically in the PTB message. Subsequent packets will be fragmented on the probe itself. In more than 95% of cases where we received 9 out of 10 responses, it is the first echo request packet that wasn't responded to (packet sizes 1,493 and 1,500 bytes). The data above suggests that about 20% of probes are in path MTU discovery mode and succeed at IPv4 packet sizes 1,493 and 1,500. At packet size 1,501 this number drops to 2% again (comparable to baseline), because the interface MTU on the RIPE Atlas probe, which is always 1,500 or less, makes the packets be fragmented by the probes kernel already. In this process no packets get lost.


Subtracting the baseline of 1 - 1.5% of RIPE Atlas probes that never see responses from those roughly 10% of probes that don't see responses for packets larger than 1,500 bytes, we can estimate the percentage of RIPE Atlas probes that have problems with fragmentation in IPv4:
In conclusion about 8.5% - 9% of RIPE Atlas probes have problems with fragmentation in IPv4.
IPv6
We did a similar experiment in IPv6, again sending 10 ICMP echo reply requests at various packet sizes. The results are shown in Table 2:
| IPv6 packet size | all lost |
10/10 received |
9/10 received |
8/10 received |
1/10-7/10 received |
number of probes |
| 100 | 11.1% | 86.4% | 1.6% | 0.5% | 0.5% | 1286 |
| 1000 | 11.4% | 85.7% | 1.4% | 0.6% | 0.9% | 1285 |
| 1280 | 11.8% | 86.6% | 1.1% | 0.0% | 0.5% | 1284 |
| 1281 | 13.2% | 72.9% | 9.0% | 4.0% | 0.9% | 1284 |
| 1472 | 14.2% | 68.4% | 9.7% | 6.6% | 1.1% | 1286 |
| 1473 | 14.1% | 65.8% | 9.8% | 7.4% | 2.9% | 1292 |
| 1480 | 14.5% | 65.8% | 9.3% | 8.2% | 2.2% | 1285 |
| 1481 | 16.7% | 51.0% | 11.2% | 16.3% | 4.9% | 1285 |
| 1492 | 17.0% | 50.9% | 10.6% | 16.4% | 5.1% | 1284 |
| 1493 | 18.1% | 44.3% | 14.4% | 18.1% | 5.1% | 1288 |
| 1500 | 18.3% | 43.5% | 14.9% | 18.5% | 4.8% | 1289 |
| 1501 | 21.0% | 40.9% | 14.5% | 17.5% | 6.0% | 1288 |
| 1502 | 20.9% | 41.2% | 14.5% | 18.5% | 5.0% | 1290 |
Table 2: Echo reply requests at various IPv6 packet sizes
The results show that there is already a high baseline loss of about 11% (which is a known phenomenon ) at 100 byte IPv6 packets. This 'all lost' column is plotted in Figure 3 and Figure 4. Comparing this baseline loss to the loss at 1,501 bytes, the percentage of RIPE Atlas probes that have problems with fragmentation in IPv6 is about 10%. Interesting to note is the difference in the number of probes that receive 9 out of 10 packets (middle column in Table 2) between packet sizes 1,280 and 1,281 (cells marked in bold). This increase from 1.1% to 9.0% is indicative of the percentage of probes that go into path MTU discovery when the packet size exceeds IPv6's minimum MTU of 1,280 bytes.


Correlation to Network Address Translation (NAT)
To test if fragmentation problems correlate with RIPE Atlas probes behind NATs we looked at the set of probes that successfully executed ping measurements at unfragmented IPv4 packet sizes (1,000 bytes in this case). We checked if we could find the same probes in ping measurements at ping payloads that resulted in fragmentation (1,501 bytes in this case). This failure rate is shown in Table 3 for NATted and unNATted probes:
| Probe type | Number of probes | Failure rate |
| NATted | 2607 | 10.3% |
| unNATted | 951 | 5.6% |
Table 3: Failure rates for NATted ad unNATted RIPE Atlas probes
This indicates that devices with NAT functionality are part of the problem, but they don't seem to account for all of the breakage we measure.
Applicability to the wider Internet
As already mentioned in the NANOG thread , there is a very likely bias towards clueful hosts (e.g. network operators) when comparing networks with RIPE Atlas probes to the Internet in general. We don't know to what extent these results are also applicable to the wider Internet. What we can measure though is the diversity, both geographically and topologically, of the RIPE Atlas probes taking part in these tests. This is shown in Table 4:
| Protocol | minimum number of probes in tests | number of countries | number of ASNs |
| IPv4 | 3611 | 117 | 1498 |
| IPv6 | 1284 | 71 | 449 to 452 |
Table 4: Diversity of RIPE Atlas probes taking part in the tests
Conclusion
We measure that about 8.5% to 9% of RIPE Atlas probes have problems with fragmentation in IPv4, and 10% of probes have fragmentation problems in IPv6. The IPv6 number agrees with a study that was performed by NLNetLabs in 2012, at which point the number of deployed RIPE Atlas probes was considerably smaller then now. In the meantime NLNetLabs have resumed their work on fragmentation, and the RIPE NCC is closely cooperating with this effort to better inform the Internet operations and research communities on this issue.
Watch this space!
Footnotes:
[1]: Measurement setup: Measurements were done three times, and results are shown for the measurement that yielded the most RIPE Atlas probes participating (this is to counter the fact that sometimes significantly less probes are allocated for an experiment then expected, which is something the RIPE Atlas team is currently looking into to fix). The linux kernel running of RIPE Atlas probes sets the DF flag on unfragmented outgoing ICMP echo request packets, but if it has to fragment packets, the fragments don't have the DF flag set, and packets are split at pMTU (i.e. if the packet size is 1,501 and the pMTU is 1,500, the fragmented packets will be 1,500 and 1+<IP header> bytes respectively). Measurements were done at least 10 minutes apart to counter possible effects of path MTU caching. The well-known host we used for all IPv4 tests didn't set the DF flag on ICMPv4 echo response packets.
Comments 10
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Mikael A •
It would be interesting to see what the performance is for IPv6 packets with fragmentation header, that is substantionally smaller than MTU. So for instance, sending packets that are 1200 bytes large but that have an fragmentation header. There are quite a few networks that punt these packets to slow-path in the routers, thus making any packets with a fragmentation header work very badly regardless of packet size.
Emile Aben •
Yes, that'd indeed be interesting. Unfortunately it is not yet possible in RIPE Atlas. Adding support for IPv6 extension headers is a requested feature that is on the RIPE Atlas Roadmap: http://roadmap.ripe.net/ripe-atlas/
Anastasios Chatzithomaoglou •
It would be nice if results per Atlas owner could be somehow displayed on their page. Just to give a warning to these users.
Vesna Manojlovic •
Hi Anastasios, Good idea, I will add it to the list of requested features in the RIPE Atlas roadmap, as "Display (path) MTU information to the probe owner". If you would want to clarify the details, please contact me by email: BECHA at ripe.net
Steve B •
I'm curious about the 1493-byte breakpoint. 1501-8 = 1493, and 8 is what? Length of a VXLAN/GRE header? Would this happen if the targeted host was a VM?
Tassos •
That's most probably the PPPoE/PPP (6+2) header of DSL clients.
John Jason Brzozowski •
Could really large MTUs be measured especially for IPv6, ie 4K?
Emile Aben •
We haven't tested configurations with MTUs over 1500, and currently don't see probes with MTUs over 1500. Also currently the maximum allowed packet size is 2048 (enforced by the RIPE Atlas infrastructure). If there is interest from the community to support probes with higher MTUs and tests with larger packet sizes, we can put that on our roadmap for RIPE Atlas.
Spyridon Kakaroukas •
While the stats are definitely very interesting, I wonder what percentage represents broken PMTUD in general as opposed to operators specifically dropping ICMP fragments.
Emile Aben •
Hi Spyridon, The NLNetLabs report (link is in the conclusion-section of the article) has separate experiments for dropping fragments and dropping PTB messages.