
DNS TTL violations is a controversial topic. It basically means a resolver overrides a TTL value provided by an authoritative server, and then serving its clients with this value. In this post, we analyse if this is happening in the wild.
1. Introduction
The time to live (TTL) value of a DNS record is "primarily used by resolvers when they cache resource records (RRs). The TTL describes how long a RR can be cached before it should be discarded" (see RFC1034). In other words, the maximum value (in seconds) a DNS resolver should keep a domain in its cache.
When a recursive resolver overrides the TTL value of a DNS record as provided by the authoritative server, we call that TTL violation. For example, as documented on the dns-oarc mailinglist, Amazon EC2 local resolvers override the TTL of .nl from 172800 to 60. Other research has reported the same for wired and mobile networks, respectively [see here and here).
Whenever a resolver violates the TTL specified by a DNS zone, two things can happen:
- If the TTL value is reduced from 2 days to 60 seconds (for instance, as in the case of EC2), such records would expire from the resolver's cache while still being valid in the authoritative server (ultimately generating extra queries from the resolver to the authoritative server).
- If the TTL value is increased, however, a resolver may keep in its cache RRs for a longer period of time. And this can create inconsistency: a RR that has been updated in the authoritative server may remain outdated in the local cache of the resolver for as long as this resolver wants (basically the new TLL value). This poses a risk in the case of malicious domains, which can be removed from the authoritative zone and, if their TTL is increased on the resolver's side, will
still be valid in the local cache of the resolvers, posing a risk to the resolver's clients.
There are people who support TTL violations while others are against it (see here, here and here). The Internet Draft Serving Stale Data to Improve DNS Resiliency presents a method (currently being used by many cloud providers) to slate DNS query data when authoritative servers are unreachable.
In this post, we do not debate if resolvers should violate TTL values provided by authoritative servers or not. Instead, we are interested in a different question: Are TTL violations happening in the wild? TTL violations have been reported in other studies (e.g. on wireless networks), but not on a large number of providers.
To analyse this situation, we use (of course) RIPE Atlas probes.
2. Measurements
To measure TTL violations in the wild, we have to perform the following steps:
- Register a non-used domain name (cachetest.nl)
- Set up two authoritative name severs for cachetest.nl:
- ns1.cachetest.nl
- ns2.cachetest.nl
- Set up the zone files for each NS, using RIPE Atlas probe IDs as subdomain (so we can use macros to send unique queries from each probe to avoid caching -- i.e., $p.cachetest.nl, where $p is probeid )
23559 333 IN TXT "this is ns1 responding to probe 23559"
23560 333 IN TXT "this is ns1 responding to probe 23560"
23561 333 IN TXT "this is ns1 responding to probe 23561"
23562 333 IN TXT "this is ns1 responding to probe 23562" - Run RIPE Atlas measurements with 10,000 probes (see measurement details)
- Parse and analyse the results
As show in step 3, we make sure each probe queries a unique domain name, so even if they share the same resolver, they guarantee a cache-miss situation in the resolver. In other words, each query should lead the resolver to query one of our authoritative servers.
2.1 Dataset
After running the measurement for 1 hour, querying every 600s (almost twice the value of TTL of the records in our zone), we generate the final dataset shown in Table 1. As you can seen, 9,119 RIPE Atlas probes were involved in this measurement, querying more that 6,687 resolvers.
Since each probe can contact multiple resolvers, we see that, in the end, there are 15,923 vantage points, i.e. unique combinations of probe-resolvers.
Our 54,115 queries lead to more than 94,805 answers, which we use in our analysis described in the next section.
| Unique Probes | 9,119 |
| Unique Resolvers | 6,587 |
| Unique ProbeResolver pairs | 15,923 |
| # Queries | 54,115 |
| # Answers | 94,805 |
| Duration | 1 hour |
| Frequency | every 10min |
| Datsets | [8] |
3. Analysis
So given that we set the TTL for every record in our demo zone to 333, the question is: How many resolvers are changing this TTL value? What is the typical change, if any?
The expected value for the TTL of queries is 333. However, since multiple probes can use the same resolver, we can expect some TTLs to be slightly smaller than 333. However, no queries should have a TTL above 333.
We divide the dataset from Table 1 into three parts:
- Normal TTL: for answers with 320 <= TTL <= 333
- Decreased TTL: for answers with TTL < 320
- Increased TTL: for answers with TTL > 333
Table 2 shows the results. As you can seen, a large majority of probes/queries/resolvers fall into the normal category, meaning their TTL deviates up to 13 from the original 333 (since multiple probes can use a same resolver). Next, we focus on both decreased and increased TTL resolvers, to understand why and how much these values change.
| Complete (baseline) | Normal | Decreased | Increased | |
|---|---|---|---|---|
| Unique Probes | 9,119 | 8,894 | 190 (2.08%) | 274 (3.00%) |
| Unique Resolvers | 6,587 | 6,480 | 130 (1.97%) | 275 (4.17%) |
| Unique ProbeResolver pairs | 15,923 | 15,418 | 257 (1.61%) | 464 (2.91%) |
| # Queries | 54,115 | 52,701 | 540 (1.00%) | 1,464 (2.71%) |
| # Answers | 94,805 | 91,610 | 732 (0.77%) | 2,463 (2.60%) |
3.1 Decreased TTL answers
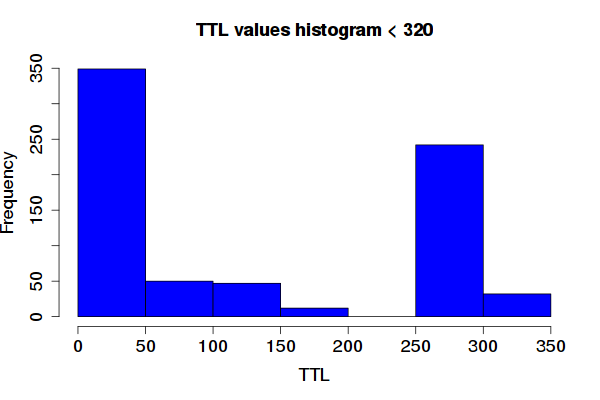
As shown in Table 2, 0.77% of all valid answers in this measurement had their TTL decreased. Figure 1 below illustrates this. Two types of resolvers dominate: those who cap the TTL around 50s, and those around 250-300.
Out of 130 resolvers that reduce their TTL, 71 reduce to less than 50. Many of those, however, are local resolvers using private IP address ranges. Out of the 71, 24 are not, and they belong to networks in mobile operators and research institutes.
Out of the 130 resolvers, 16 (out of those with non private addresses) reduced the TTL from 333 to between 250 and 320. No particular pattern was found in here - several operators from various countries were performing the same way. We also found cases in which Google quad8 resolvers were reduced, but that is an outlier, given the large volume of instances of their infrastructure.

Figure 1: Histogram of TTL values for the decreased queries group (see Table 2).
3.2 Increased TTL answers
We have seen in Table 2 that 4.17% of the resolvers will actually increase the TTL value of our RRs in this measurement.
Figure 2 below shows the Empirical Cumulative Distribution Function (ECDF) of TTL values for answers with TTL above 333. These are particularly worrying, since they will return to any of their clients a RR that may have already been expired on their respective zone.

Figure 2: The ECDF of TTLS larger than 333
4. Conclusions
DNS TTL violations is a controversial topic, with passionate arguments on both sides. It is publicly known that some cloud providers and CDNs override the original values provided by authoritative servers within their networks.
In this article, we use RIPE Atlas to measure if this is happening in the wild. Even though there is a small number of resolvers doing this, it is unclear how many users are being affected.
Reducing the TTL values is debatable, but ultimately will lead the resolver to querying an authoritative server more often. Thus users should always be provided with the correct RR whenever the TTL values are reduced.
Increasing TTLs, on the other hand, may be dangerous to users, since they maybe served with records that are already expired. Consider the case of domains that have been removed from a zone due to a phishing or malware attack: by extending the TTL of these domains, resolvers will "keep them alive" for any of their clients.
The parsed datasets from the RIPE Atlas measurements are attached in this zip file.
Appendix: RIPE Atlas probes with increased TTL values
Format: ProbeID-ResolverIP, ...
22372-fd00:10:246:200::1,22480-fd69:b46:ca9b::1,22891-fd48:71b9:382f::1,31959-
fd00::201:2eff:fe6e:63b8,10181-2a01:e00::1,
10181-2a01:e00::2,10816-2a01:e00::2,11243-2a01:e00::2,11828-2a01:e00::1,
11828-2a01:e00::2,12360-2a01:e00::1,12360-2a01:e00::2,13209-2a01:e00::1,
13209-2a01:e00::2,13317-2a01:e00::2,13407-2a01:e00::1,13407-2a01:e00::2,
13439-2a01:e00::1,14311-2a01:e00::1,14311-2a01:e00::2,14342-2a01:e00::1,
15973-2a01:e00::1,15973-2a01:e00::2,16007-2a01:e00::2,16047-2a01:e00::2,
16052-2a01:e00::1,16052-2a01:e00::2,16146-2a01:e00::1,16146-2a01:e00::2,
16644-2a01:e00::1,16644-2a01:e00::2,16703-2a01:e00::1,16703-2a01:e00::2,16872-
2a01:e00::2,16973-2a01:e00::1,16973-2a01:e00::2,16978-2a01:e00::1,16978-2a01:e00
::2,16998-2a01:e00::1,16998-2a01:e00::2,17025-2a01:e00::1,17025-2a01:e00::2,
17035-2a01:e00::1,17035-2a01:e00::2,17064-2a01:e00::1,17064-2a01:e00::2,17127-
2a01:e00::2,17147-2a01:e00::1,17147-2a01:e00::2,17153-2a01:e00::1,17153-2a01:e00
::2,17214-2a01:e00::2,17228-2a01:e00::1,17228-2a01:e00::2,17263-2a01:e00::1,
17263-2a01:e00::2,17848-2a01:e00::1,17848-2a01:e00::2,18429-2a01:e00::1,18710-
2a01:e00::2,19032-2a01:e00::1,19671-2a01:e00::2,20226-2a01:e00::1,20226-2a01:e00
::2,20480-2a01:e00::2,21173-8.8.4.4,21173-8.8.8.8,2139-62.141.32.3,21507-2a01:
e00::1,21597-2a01:e00::1,21990-2a01:e00::1,21990-2a01:e00::2,21991-2a01:e00::2,
22171-2a01:e00::1,22171-2a01:e00::2,22210-2a01:e00::1,22210-2a01:e00::2,22892-
2a01:e00::1,22892-2a01:e00::2,22963-2a01:e00::1,22963-2a01:e00::2,23289-2a01:e00
::1,23289-2a01:e00::2,23294-2a01:e00::1,24336-2a01:e00::1,24336-2a01:e00::2,
24520-2a01:e00::1,2576-83.219.128.10,26095-2a01:e00::1,26095-2a01:e00::2,27263-
2a01:e00::2,27607-2a01:e00::1,27607-2a01:e00::2,27622-2a01:e00::2,2862-92.244.96
.117,28889-2a01:e00::1,29425-2a01:e00::1,29425-2a01:e00::2,29622-2a01:e00::1,
29622-2a01:e00::2,29772-2a01:e00::1,30807-2a01:e00::1,30807-2a01:e00::2,30920-
2a01:e00::1,30920-2a01:e00::2,30922-2a01:e00::1,30922-2a01:e00::2,31148-2a01:e00
::1,31517-2a01:e00::1,31517-2a01:e00::2,31598-2a01:e00::1,31598-2a01:e00::2,
31749-2a01:e00::1,31749-2a01:e00::2,31770-2a01:e00::2,31853-2a01:e00::1,31853-
2a01:e00::2,31879-2a01:e00::1,31879-2a01:e00::2,31967-2a01:e00::1,31967-2a01:e00
::2,32016-2a01:e00::1,32016-2a01:e00::2,32057-2a01:e00::2,32070-2a01:e00::1,
32140-2a01:e00::1,32140-2a01:e00::2,32320-2a01:e00::1,32419-2a01:e00::1,32606-
2a01:e00::2,32647-2a01:e00::1,32647-2a01:e00::2,33202-2a01:e00::1,33202-2a01:e00
::2,33448-2a01:e00::1,33520-2a01:e00::1,33520-2a01:e00::2,33521-2a01:e00::1,
33521-2a01:e00::2,33924-2a01:e00::1,33924-2a01:e00::2,11729-10.10.16.1,12099-10.
2.2.1,12576-10.1.0.1,13195-10.237.138.137,13972-81.3.3.81,14387-83.172.40.200,
14387-83.172.41.200,17032-10.0.0.3,17858-62.141.32.3,2108-192.168.0.2,2160-192.
168.100.1,2181-192.168.1.254,22017-10.0.0.99,22372-10.246.200.1,23342-10.0.8.240
,23410-10.0.61.1,23796-84.54.64.34,24509-87.72.130.2,24509-87.72.22.66,2486-192.
168.1.254,2511-192.168.72.1,2553-192.168.0.1,2571-212.27.40.240,2571-212.27.40.
241,25727-80.250.1.155,25727-80.250.1.161,2610-109.110.160.172,2623-192.168.1.
254,2656-192.168.1.1,2684-192.168.1.1,2755-212.27.40.240,2755-212.27.40.241,
28186-10.200.99.1,28741-10.80.32.13,31502-46.175.231.193,31847-10.0.0.254,31918-
10.0.0.1,31985-85.21.192.3,32186-10.0.0.1,32317-10.67.71.2,3282-192.168.0.250,
32866-89.47.39.13,33382-88.158.158.3,33950-10.0.0.254,3520-192.168.0.254,3528-
200.3.169.65,3528-200.3.169.66,3588-209.193.0.2,3588-216.67.0.2,3657-192.168.1.1
,3763-192.168.1.1,3782-192.168.77.1,3825-192.168.1.1,3867-192.168.1.1,3869-192.
168.1.1,3880-192.168.0.1,3887-192.168.70.1,4045-192.168.1.254,4076-212.27.40.240
,4076-212.27.40.241,4108-212.27.40.240,4108-212.27.40.241,4264-192.168.0.254,
4266-192.168.0.254,4308-192.168.11.253,4372-192.168.88.1,4383-192.168.0.1,4889-
212.1.224.6,4889-212.1.244.6,4896-192.168.1.1,10673-212.27.40.240,10673-212.27.
40.241,10717-192.168.1.1,10718-192.168.0.1,10816-212.27.40.240,10816-212.27.40.
241,11022-192.168.0.254,11243-212.27.40.240,11243-212.27.40.241,11301-213.170.64
.33,11437-192.168.88.1,11437-195.239.225.93,11437-195.239.225.94,11531-212.27.40
.240,11531-212.27.40.241,11716-192.168.68.1,11828-192.168.0.254,11992-192.168.
100.1,12066-192.168.1.1,12099-192.168.0.1,12357-172.20.1.1,12360-192.168.0.254,
12443-192.168.2.1,12563-192.168.0.2,12584-195.245.120.135,12800-212.27.40.240,
12800-212.27.40.241,12873-192.168.1.1,13209-192.168.0.254,13307-192.168.1.254,
13310-212.27.40.240,13310-212.27.40.241,13393-212.27.40.240,13393-212.27.40.241,
13407-192.168.1.254,13439-192.168.22.254,13605-192.168.1.254,13807-101.100.188.
23,13807-103.7.200.10,14311-192.168.0.254,14772-192.168.1.1,14776-192.168.21.254
,15535-194.225.152.10,15973-192.168.0.254,16007-212.27.40.240,16007-212.27.40.
241,16020-192.168.30.1,16047-212.27.40.240,16047-212.27.40.241,16052-192.168.2.
254,16146-192.168.208.254,16644-192.168.0.254,16645-192.168.0.254,16670-212.27.
40.240,16670-212.27.40.241,16703-192.168.0.254,16818-192.168.0.254,16869-212.27.
40.240,16869-212.27.40.241,16872-212.27.40.240,16872-212.27.40.241,16973-192.168
.0.254,16978-192.168.0.254,16981-192.168.0.254,16998-192.168.0.254,17025-192.168
.0.254,17030-192.168.1.254,17032-212.27.53.252,17032-212.27.54.252,17035-192.168
.0.254,17064-192.168.0.254,17072-212.27.40.240,17072-212.27.40.241,17078-212.27.
40.240,17078-212.27.40.241,17106-192.168.1.1,17127-212.27.40.240,17127-212.27.40
.241,17131-192.168.0.254,17153-192.168.1.1,17174-192.168.0.254,17209-212.27.40.
240,17209-212.27.40.241,17214-212.27.40.240,17214-212.27.40.241,17221-192.168.
254.254,17228-192.168.0.254,17240-212.27.40.240,17240-212.27.40.241,17253-192.
168.0.254,17263-192.168.0.254,17397-212.27.40.240,17397-212.27.40.241,17420-194.
225.152.10,17436-194.225.152.10,17437-194.225.152.10,17502-192.168.10.1,17502-
192.168.10.11,17569-212.27.53.252,17569-212.27.54.252,17619-192.168.88.1,17781-
192.168.254.1,17848-192.168.1.254,18024-195.22.112.69,18564-192.168.1.1,18710-
212.27.40.240,18710-212.27.40.241,18884-113.212.113.212,18925-212.27.40.240,
18925-212.27.40.241,19374-109.71.47.200,19374-130.185.80.80,19504-194.225.152.10
,19627-172.16.0.1,19671-212.27.40.240,19671-212.27.40.241,19984-196.49.13.38,
20096-202.52.255.3,20096-202.52.255.47,20210-192.168.10.1,20223-192.168.5.2,
20226-192.168.1.1,20295-192.168.0.254,20480-212.27.40.240,20480-212.27.40.241,
20515-192.168.2.2,20717-192.168.11.1,20777-192.168.0.1,20909-195.88.158.8,20955-
192.168.1.1,21101-202.159.32.2,21438-192.168.1.254,21596-192.168.1.254,21597-192
.168.1.1,21833-192.168.1.1,21990-192.168.1.254,21991-212.27.40.240,21991-212.27.
40.241,22095-109.71.47.200,22095-130.185.80.80,22171-192.168.0.254,22210-192.168
.99.254,22370-212.27.40.241,22372-212.27.40.240,22429-192.168.0.22,22480-192.168
.0.56,22711-192.168.1.1,22891-192.168.1.1,22892-192.168.69.254,22898-192.168.42.
254,22918-192.168.0.254,22963-192.168.0.254,23254-192.168.71.1,23289-192.168.1.
254,23290-192.168.3.1,23387-212.27.40.240,23387-212.27.40.241,24192-192.168.100.
254,24336-192.168.0.254,24520-192.168.0.254,24801-192.168.1.10,25003-192.168.88.
1,26095-192.168.0.254,26129-192.168.0.1,26671-192.168.1.1,26756-192.168.1.1,
26756-212.27.40.240,26756-212.27.40.241,26900-192.168.8.1,26966-192.168.88.1,
26966-212.1.224.6,26966-212.1.244.6,27263-212.27.40.240,27263-212.27.40.241,
27383-192.168.1.1,27538-192.168.200.242,27607-192.168.0.254,27622-192.168.0.254,
27624-192.168.1.254,28489-212.27.40.240,28489-212.27.40.241,28531-192.168.10.1,
28888-192.168.1.254,28889-192.168.0.1,28951-192.168.0.254,29425-192.168.4.254,
29622-192.168.0.254,29674-192.168.1.254,29770-192.168.1.254,29866-192.168.1.1,
30255-192.168.10.1,30266-192.168.10.1,30409-192.168.0.3,30676-189.50.140.50,
30771-192.168.1.254,30775-192.168.0.254,30807-192.168.1.254,30920-192.168.1.1,
30922-192.168.0.254,30951-192.168.0.254,30962-192.168.3.1,31085-192.168.1.104,
31517-192.168.1.254,31548-192.168.1.1,31556-192.168.1.1,31598-192.168.1.46,31749
-192.168.1.254,31764-192.168.14.1,31770-212.27.40.240,31770-212.27.40.241,31853-
192.168.1.254,31879-192.168.0.1,31932-212.27.40.240,31932-212.27.40.241,31946-
192.168.2.254,31959-192.168.178.4,31985-213.234.192.8,32016-192.168.0.254,32057-
212.27.40.240,32057-212.27.40.241,32140-192.168.5.254,32419-192.168.0.254,32529-
192.168.0.254,32537-192.168.1.6,32568-172.16.1.1,32606-212.27.40.240,32606-212.
27.40.241,32638-195.191.180.4,32638-195.191.180.9,32646-172.31.4.100,32646-172.
31.4.2,32646-172.31.4.205,32647-192.168.1.10,32730-192.168.0.1,32884-185.164.252
.10,32884-185.164.252.11,32930-192.168.28.254,32968-192.168.1.1,33024-103.7.200.
10,33069-185.40.96.96,33069-185.40.96.97,33110-199.19.224.159,33202-192.168.0.
254,33448-192.168.1.254,33520-192.168.0.254,33812-192.168.10.254,33924-192.168.1
.254,33967-212.27.40.240,33967-212.27.40.241,17858-2001:4ba0::53:1,17858-2001:
4ba0::53:2,17951-2001:41d0:fc8b:c900::314,27383-2001:470:28:a3c::1



Comments 5
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Stéphane Bortzmeyer •
Thanks for these very interesting measurements. Really useful. But I disagree with your use of the same term ("TTL violations") for the increase and the decrease of the TTL. A TTL is a *maximum*. A resolver is always free to keep the data for a *shorter* time, for instance because it reboots, or because the cache is full and it has to evict some data. It's only the increase of the TTL which is a protocol violation. Decreasing the TTL, like Amazon does systematically, is bad manners, it transfers costs to someone else, it is selfish, but it is not a protocol violation.
Giovane Moura •
Thanks Stéphane for your feedback. I refer to TTL violations as in [1] , which is when a resolver " overrides the TTL value" . In regardless if is increased or decreases; just different from what the authoritative returns. So in this context , violation is not protocol violation, is the violation or changing the original TTL value provided by the authoritative. thanks, /gio [1] https://dl.acm.org/citation.cfm?doid=3143361.3143375
Stéphane Bortzmeyer •
I still disagree with the term: first, a resolver does not always talk with an authoritative name server, it may talk to an upstream resolver a forwarder), and so receive a smaller TTL. Also, all DNS implementations have an upper bound for TTLs (sometimes configurable, as with BIND and Unbound). Is it a "violation" to cap a one-month TTL (seen in the wild) to one week?
Giovane Moura •
> I still disagree with the term: first, a resolver does not always talk with an authoritative name server, it may talk to an upstream > resolver a forwarder), and so receive a smaller TTL. There may be many "middleboxes" -- other boxes in between resolver and the client , as you pointed (just like fig 1 in [0] I am not saying the violations were performed by the local resolver. I am only claiming they were violated/changed. Now, to avoid any "cache hit" in any "middlebox" -- ie., shared cache, other resovlers, etc. -- which woudl return me a smaller TTL value -- I ensured that each probe sent a unique query -- see step 3 on section 2. So even if two probes used the same local resolver at the same time, they would have asked for diff records , in the format of $probeID.cachetest.nl > Also, all DNS implementations have an upper bound for TTLs (sometimes configurable, as with BIND and Unbound). Is it a "violation" to cap a one-month TTL (seen in the wild) to one week? "Violation" in this case is changing the value provided by the auth server, in regardless of the intention. I am not implying any judgment on the value change, only a value change. refs: [0] https://www.isi.edu/~johnh/PAPERS/Mueller17a.html
Damien FLEURIOT •
Interesting measurement, thanks for the time you put into it. I'm confused however, about this part : == The expected value for the TTL of queries is 333. However, since multiple probes can use the same resolver, we can expect some TTLs to be slightly smaller than 333. However, no queries should have a TTL above 333. == I thought each probe queried its own, individual RR ? If that is so, surely no probe should see a value of 320 <= x <= 333 ?