

On 29 July 2020, a number of RIPEstat widgets and their associated API endpoints began reporting incorrect data. In this article, we analyse what happened and explain how we are fixing the problem to prevent future outages.
What happened
On 29 July 2020, between 06:05–16:21 (UTC), the RIPEstat widgets and Data API calls were returning incorrect data for a number of datasets based on the latest available data. More specifically, it reported all prefixes as “not announced” and “not visible”, and all ASNs as “Does not originate prefixes visible” and “Is not seen in any other route”. The widgets and API calls returning historical data were not affected.
Outage analysis
Data presented in RIPEstat comes from route collectors (RRCs) which have different characteristics in terms of data volumes and delays, so that resulting datasets for different RRCs become available at different times. Also, the data is stored with different aggregation intervals, 8 hours, 2 days and 12 days. To present this data consistently in RIPEstat, we use an additional dataset, which we call metadata, that describes which data from which RRCs is available for each aggregation interval.
Data for different aggregations is created by three different jobs, which are run independently from each other. 2- and 12-day aggregations are created once a day around 03:00 (UTC) but 8-hour aggregations are scheduled to run throughout one day with a 2-hour interval.
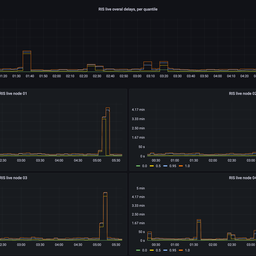
The outage occurred because the aggregation intervals were not taken into account when the metadata was being inspected. On that day, the 8-hour aggregation job was busy processing the backlog of data from RRC21 (more info below) and was therefore not processing recent data from all other RRCs for quite a long time. The 2- and 12-day aggregation jobs were also affected but finished their work at around 06:05 and 07:32 (UTC) and updated the metadata. The 12-day aggregation timestamp was picked up by RIPEstat and was used to query 8-hour aggregation data. Since that data was not available yet, it was interpreted as either “prefix not announced” or “ASN is not visible”.
The problem of not recognising different aggregation intervals in metadata existed in our code for quite a long time, probably since this mechanism was implemented in 2015, it was just not really visible. Our analysis shows that while the potential for the condition that triggers this bug exists every night, when all three jobs run concurrently, in practice this happens only for a short period of time, less than 30 minutes between 03:00 and 04:00 (UTC). And this doesn't affect all RRCs, so that during these times RIPEstat always has data from other RRCs to create a proper answer.
Additional information
Occasionally, RIS peers produce extensive amounts of BGP messages that influence the performance of RIS data pipelines and therefore the generation of RIPEstat datasets. On such occasions, we usually contact the relevant peers and try to solve the problem directly with them. On 16 July 2020, we had a similar case with one peer on RRC21 and although the influx of extraneous BGP updates stopped on 21 July, by 27 July the generation of dump files for RRC21 was still delayed by a week. The process that generates an intermediate dataset for dump files and RIPEstat was spending all CPU cycles in bzip2 deflate code, which left us almost no options to influence its performance. Seeing significant delay in dump files generation, we switched the compression algorithm for the intermediate dataset to the less CPU-hungry LZ4 algorithm, which dramatically improved the situation. The one-week backlog of data for the intermediate dataset was processed in one day, and by the end of 28 July all outstanding dump files for RRC21 were generated. However, this also created a huge amount of new data to include in RIPEstat datasets, and this is what our processing jobs were busy with during 29 July, delaying processing of more recent data, and making the misalignment between data with different aggregation intervals quite visible.
Lessons learned
We are fixing our code where it does not treat our metadata correctly.
We are also busy with switching all RIS pipelines from the batch-oriented jobs, created in the past when the main data supply to RIS were RIB dump files generated every 8 hours, to a stream-based processing of live data delivered by our collectors now. This will enable near-realtime generation of dump files (as it is currently the case with update files), more recent data in RIPEstat datasets, and allow us to process more data in parallel, so that backlogs of data from some peers will have less influence on the overall system.
We are investigating possible options for handling occasional substantial amounts of BGP updates delivered by some peers. We are open for community suggestions on this matter. If you have feedback, please send it to routing-wg@ripe.net or ris-users@ripe.net.
Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.