
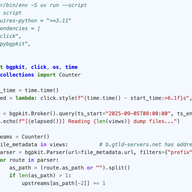
Working with BGP Data

• 14 min read
Have you heard about MRT dumps, but never tried to use them because the bar seems too high? Or are you tired of doing “parse -> grep -> process” every time you touch BGP MRT dumps? This hands-on guide shows how to load RIS/RouteViews data into ClickHouse - covering tools, schema, and example querie…






“Hello - What happened to being able to look up an organization's IP using the RIPE Org-ID???? This new system does not allow for that. I have to plug in the IP address. Before, the old stat.ripe.net would allow you to look up the IPs using an Org-ID and then filter using attributes to see all IPs under a particular Org-ID. How can we access that information?! Is it gone? Also, the Ripe Launchpad provides a lot of useful info in one place such as Abuse Contact, Allocation History, BGP Update Activity, IANA, Maxmind Geo Map, Prefix Status, RIPE Reverse DNS Delegation, RIPE Atlas Probes, RIPE Atlas Targets, RIR Registration, RIR Stats Country, RIS Visibility, RIS Looking Glass, Routing History, RPKI Origin Violation, Transfers, RIS Related Prefixs, RPKI History, and WHOIS. What happened to all that information and can we still access it???”
We described in this, and our earlier updates, that we can not maintain two user interfaces. We understand that we can not make everyone happy. However, we had to take a path forward and decided to move forward from the UI that worked better for users in our research. About searching by ORG-ID: That is an interesting feature. RIPEstat did/does not support searching by ORG-ID. This type of search query is supported and works very well in the RIPE database at https://apps.db.ripe.net/ however.
@Stéphane: Thanks for you report! We underestimated the load the system would have. This should be resolved by now. We will track this on https://status.ripe.net/incidents/2jyvq1h34bgv
Nice article! duckdb has quickly become one of the favourite tools for my data analysis workflows. Since it turns out that many patterns that I end up doing in dataframes (split -> aggregate) are manageable in SQL. I even found some use case for python UDFs that I then call from SQL. And I like how easy it is to integrate it into workbooks or scripts and scales from small (megabytes) to medium-sized data (~500GB uncompressed dataframes). I have done some experiments with parquet-based derivative data of internet data. When they stabilise I will try to write more about it. So far, the only guarantee they come with is that I will change the format 😬
Showing 3 comment(s)