
The start of 2021 saw RIPE Atlas users encountering delays in data retrieval and an overall drop in the responsiveness of the system. Now that things are back to normal, we thought we’d take a more detailed look at what happened and the steps we’re taking to prevent it from happening again.
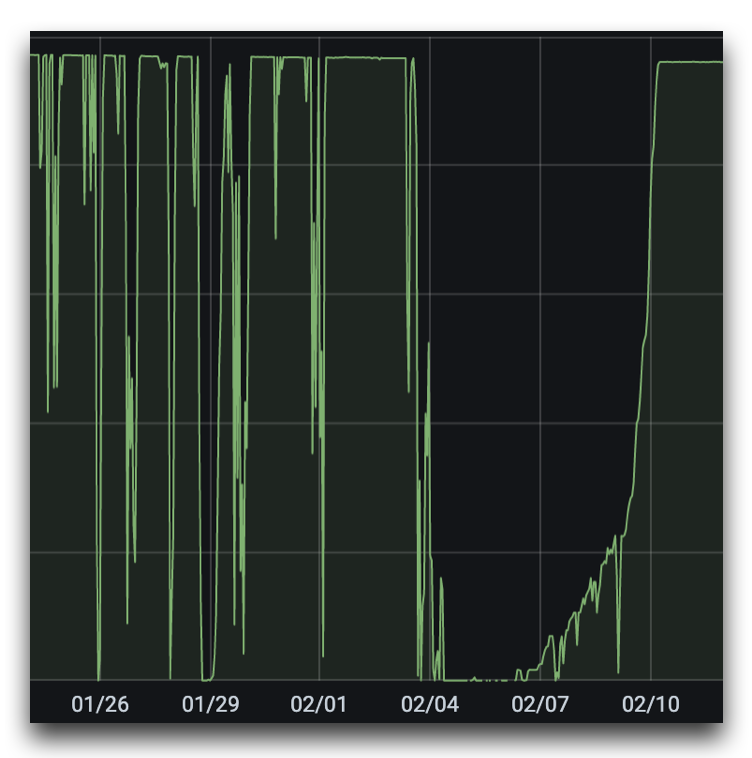
At some point in January, RIPE Atlas started running into an increasing number of problems. We saw spikes in data delays, reduced probe reporting and increasing lag in the measurement queue.
After investigating several possible causes for these delays, we discovered that the problem was being caused by errors on virtual chassis (VC) ports in the network that connects the various Hadoop nodes. These errors were cleared by resetting the interfaces on 9 February at around 10:30 UTC. Data delays returned to normal levels (below 180s) almost immediately. Probe reporting was back at normal levels around 04:00 UTC the following day, with the measurement queue lag also going back to normal around the same time.
A Closer Look
RIPE Atlas and RIS data handling relies on a Hadoop backend that we run on a network setup that makes use of virtual chassis (VCs). These VCs consist of several physical switches connected in a ring to form one logical switch, where the interconnection is handled with high-bandwidth dedicated VC interfaces.

RIPE Atlas result processing delays (defined as the difference between the current time and the timestamp of the latest available measurement in HBase) from 1 January - 9 February
Errors on these interfaces can wreak havoc on network performance in the cluster, with unpredictable behaviour for individual connections and overall packet loss for a percentage of all traffic exchanged to or from machines in the cluster. We don’t know for sure why these errors show up on some VC ports, but when they do, a reset can clear the error condition, immediately restoring performance of the network to earlier levels. To further diagnose this issue, a firmware update would have to be installed on all the members of the virtual chassis.

Drops in RIPE Atlas probe reporting (defined as % of probes that have reported in the last half hour) from 24 December - 22 February
At the end of 2020 and into January, we were looking at a number of issues affecting the RIPE Atlas cluster and working on ways to deal with them. This involved the extension of the Hadoop environment with a set of extra servers on 6 January. We continued investigating reported problems and mitigating issues throughout the month, but we didn’t look into the type of network issues caused by VC-port errors at that time. It was only after a discussion on 9 February that we realised that this issue might be the root cause of the problems affecting performance on our clusters. A quick check carried out shortly thereafter confirmed VC port errors. After resetting those ports at 10:30 UTC, the slowness disappeared and processes stabilised enough to catch up to the backlog of data over the following hours for most data sets.
Next Steps
To avoid any repeats of the above, the first step is to set up proper monitoring of the VC-port error condition. We regret that not introducing this earlier led to the above issues, but we’ve already started putting better monitoring in place, and we believe this alone will mitigate the impact of future VC errors. A software update of the affected switches is also being considered, but as that will have significant impact on the operation of the Hadoop cluster (and as a result, on RIPE Atlas and RIS), this will call for careful planning.
In addition, while debugging this issue we identified some other possible improvements that could either help reduce the impact of future network problems, or ensure faster identification or recovery. Therefore we’ll also be looking at:
- Making improvements in the way RIPE Atlas data is stored, with a focus on reducing data duplication, saving space, and improving write speed for individual measurements
- Improving the way meta-data is queried for RIS data
- Improve our monitoring of the cluster's performance metrics
Once again, we apologise for the delays our users experienced due to these issues, and we appreciate many of you taking the time to report the bugs you were seeing in January. The improved monitoring we’ve started setting up in response to all this will help improve the reliability of RIPE Atlas going forward.
If you have any other comments or suggestions based on what you've read here, leave them below or contact us at atlas@ripe.net.

Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.