
The RIPE Routing Information Service (RIS) and RIPE Atlas produce large amounts of data that needs to be processed, stored and made available to the public. We've been using Hadoop for some time now. In this article we look at the design of the infrastructure we currently have in place and describe how we use it to serve RIPE Atlas and RIPEstat users.
We started using Apache Hadoop years ago when we realised we needed a database that allows us to quickly process and provide access to large amounts of data collected by the RIS route collectors (RRCs) and RIPE Atlas . For background information, please see these two earlier RIPE Labs articles about our use of Hadoop: The Routing Information Service (RIS) and the Internet Number Resource Database (INRDB) and Large-scale PCAP Data Analysis Using Apache Hadoop .
We are now four years down the road and lots of things have changed: we produce more data, we have more users and we've gained a better understanding of how to operate big clusters. However, some things have not changed: we still use Hadoop to process and store our data.
Comparing our current situation with that in 2010 and 2011, while some things have stayed the same, there are a number of noticeable differences. We still use Cloudera's Hadoop distribution, although of course a more recent version (CDH 5). Originally the Hadoop clusters ran on two 12-node clusters. We now run two clusters with 119 servers per cluster with 880 cores available. In total we have a Hadoop Distributed File System (HDFS) capacity of about 400TB, around 3.5TB available memory and peak cluster bandwidth of about 80GBit/s.
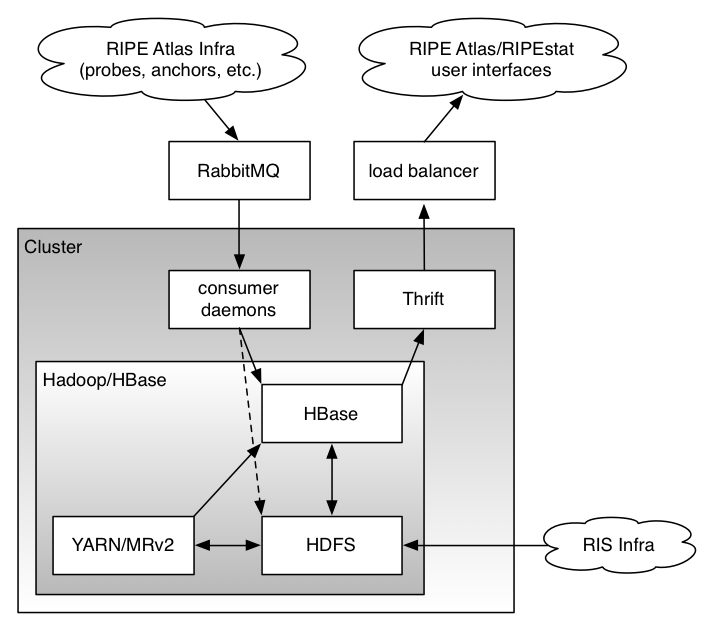
We run HDFS to store our data, YARN and MapReduce version 2 ( MRv2 ) to process it and HBase to organise and access it. The diagram below gives an overview of the current architecture.

Data Inputs: RIS and RIPE Atlas
The RIS route collectors and RIPE Atlas send data to the Hadoop cluster, but through slightly different mechanisms.
RIS
A RIS collector system copies the Multi-threaded Routing Toolkit (MRT) dumps from the RRCs and writes these to a Network File System (NFS) fileserver. This NFS share is mounted on a node in the Hadoop cluster that processes the dumps and writes the data into HDFS. It is then processed by several YARN MapReduce jobs orchestrated by Azkaban (a workflow job scheduler) and stored in HBase (the Hadoop database).
RIPE Atlas
RIPE Atlas uses a different mechanism: the probes and anchors send their data through the RIPE Atlas infrastructure machines which forward the measurement results into the Hadoop environment through a queuing cluster running RabbitMQ . The innards of RIPE Atlas have been extensively described in the recent Internet Protocol Journal .
From the RabbitMQ systems, the data is picked up by consumer daemons that store it directly into HBase and, in a different format, into HDFS. A number of scheduled MapReduce jobs process the data further, for example, to generate daily aggregates of the collected data.
Data Output: RIPE Atlas and RIPEstat
RIPEstat is the main interface for accessing data collected by RIS (indicated by the process on the top right of the diagram). RIPEstat users, via the RIPEstat website or API, access the data in HBase using a protocol called Thrift , a proxy service that sits between HBase and the clients and also runs on the cluster. For RIPE Atlas things work in quite a similar way: the RIPE Atlas frontend webservers retrieve their data from HBase using Thrift.
Next steps
Using a queueing mechanism, as in the case of the RIPE Atlas data processing described above, allows for more flexibility and scalability. Work is on its way to redesign the RIS pipeline to make use of a similar setup with a queue server and dedicated consumer daemons. More details about this redesign can be found in the recent article on RIPE Labs: Updates to the RIPE NCC Routing Information Service .

Comments 1
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Aliya •
Processing RIPE Atlas and RIPEstat Data with Hadoop Thanks for sharing this amazing article! It is really helpful Best regards,