
On 22-23 November 2023, the Amsterdam Internet Exchange (AMS-IX) had an outage on their Amsterdam peering platform. As this is generally considered one of the largest IXPs on the planet, we looked into this event from the perspective of RIPE Atlas to see what it had to tell us about the robustness of the Internet.
Even the largest of networks and IXPs have outages, some of which we’ve reported on in the past - AMS-IX and Level3 in 2015, DE-CIX in 2018, and LINX in 2021. And while events like this are rare for these important elements of the Internet, when they do happen, it’s interesting to see what we can learn from them.
For example, one thing to ask is: to what extent is the Internet resilient to this kind of event? In earlier analyses, to the extent we’ve been able to measure it, the answer has largely been: very. So let’s take a look at whether the same holds this time around.
The incident
AMS-IX have provided their own detailed and very well put together post-mortem of the incident here. This kind of clear and thorough reporting after this kind of event is invaluable. The graph in Figure 1 (also from AMS-IX) gives a view of the impact of the incident. On the evening of 22 November, you can see a huge and sudden drop in traffic, followed by a recovery period, then a second drop on the morning of 23 November.

The RIPE Atlas perspective
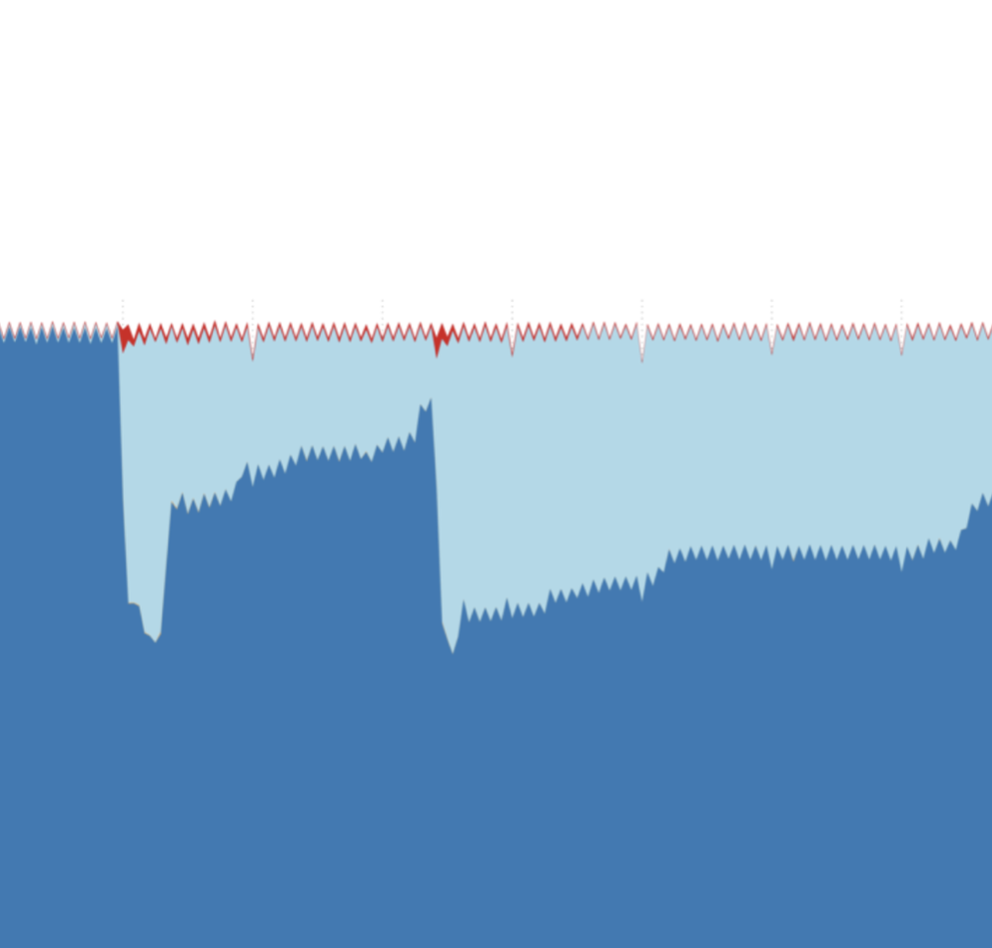
To get a broader view of what happened, we turn to RIPE Atlas. The methodology we adopted to do so is the same we used for earlier analyses of these types of event. Put briefly: to calibrate our measurements, we take the set of source-destination pairs that reliably saw the IXP and reached their intended destination the day before the outage. We find 66k source-destination pairs (7,102 unique RIPE Atlas probes and 1,778 unique destinations). For these pairs we then observe how the two properties - “see AMS-IX” and “reach destination” - hold for traceroutes on the day of the event itself and the following two days. In Figure 2, the set of traceroutes with both properties are labeled “OK” and shaded dark blue.

At around 18:00 UTC on 22 November, there’s a sudden, sharp decline in how often the AMS-IX peering LAN is seen. At the same time, we see the number of traceroutes that reliably reach their intended target, but which now diverge from AMS-IX, picking up most of the drop (light blue in Fig 2). There’s also a relatively small fraction of connectivity failures (red and orange in Fig 2), but overall we see almost all paths reaching their destination successfully.
After the initial event, there’s a steady recovery until a second large drop in traceroutes going via AMS-IX takes place a bit after 8:00 UTC on 23 November. Note that the two events look very similar: many traceroutes get diverted and the same small volume of traceroutes fail to reach their destination. If minimising this error rate is a measure of success, this outage looks much better than other outages we analysed before.
Of course this is limited to what we can see with RIPE Atlas, which has a bias. When comparing Figure 2 to the traffic stats in Figure 1, the drop in traffic (relative to its maximum) was bigger than the shift in traceroute paths in Atlas. Why? Because Atlas doesn’t measure traffic volume, it measures latencies and paths.
Where did the paths go?

In Figure 3 we try to shed a light on where paths were rerouted to. The main alternative in our data are paths without IXP. This could be a direct lateral peering that is not IXP-mediated, or using transit instead of the IXP. Next to that, we see three other IXPs in alternative paths: DE-CIX, LINX and NL-IX. These are not surprising alternatives given the location and size of these IXPs.
Figure 3 shows an interesting difference between the first and second event. For both events the IXP-less traces topped at similar levels. But while in the first event DE-CIX was the most seen IXP, the second event saw a large shift towards NL-IX as the dominant alternative IXP. Again, we don’t know how this shift in observed paths in RIPE Atlas correlates to traffic volume shifts, as we don’t have traffic volume data.
We can speculate about the reasons behind the shift towards NL-IX. If this shift happened due to the BGP selection process, DE-CIX seems to be the preferred alternative IXP for our RIPE Atlas traceroutes. We see the same shift in the initial phase of the second event, but within the first hour we see a large shift towards NL-IX, which might be a manual reconfigure of preference towards NL-IX at least for the period that we show data for.
Conclusion
The things that interconnect the Internet are ultimately controlled, upgraded and monitored by humans (at least for now). And as with any human-made structure, these things occasionally fail.
For the very large IXPs, who have evolved from their humble beginnings as switches to elaborate layer 2 fabrics, these failures are few and far between. The list of years when notable outages for the “big 3” occurred is rather short: 2015, 2018, 2021, and now 2023. But as each outage shows, the vast majority of paths we see in RIPE Atlas that go via these important infrastructures get diverted, so even when outages occur, the Internet - by means of BGP and possibly manual intervention - will route around damage.
In sum, our studies hint at a healthy Internet interconnect ecosystem around these very large IXPs, suggesting there’s enough transit, direct (PNI) peering options and alternative paths via IXPs available for things to take a diversion when needed.




Comments 0
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.