
The RIPE NCC's Chief Information Officer, Kaveh Ranjbar, gives an update on the state of our technical services and tools, and gives readers a heads up about what they can expect in 2015.
In the second half of 2013, I prepared an action plan and reported this to the community. Now seemed like a good time to report back on what we accomplished and explain what we are going to do over the course of 2015!
Before diving into our services, it is good to mention that we fully decommissioned the Test Traffic Measurement Service (TTM) and replaced most of its functionality with RIPE Atlas anchors. That’s why, unlike in the previous article, you won’t find a section dedicated to TTM in this report. The same is true for the old DNS Monitoring Service (DNSMON). We fully re-implemented DNSMON in RIPE Atlas, and everything you will read in this article is about the new generation of DNSMON, which is also based on RIPE Atlas anchors data.
Table of Contents
RIPE Atlas
Expanding the network
At the time of writing my first report in 2013, we had 15 RIPE Atlas anchors up and running. Now, after 77 weeks, there are 110 active anchors around the world. That’s more than one new RIPE Atlas anchor set up in a data centre somewhere around the globe every week!

This expansion was not limited to RIPE Atlas anchors, though. We have also made three important logistical changes in the way we distribute probes that has helped us distribute them more efficiently and strategically.
First of all, we reduced shipping and handling costs by a factor of almost three when we started using a third-party shipping service and automated the whole process. Now, when we receive a probe request, we run some automated checks to ensure that the RIPE Atlas network would benefit from the person hosting a probe (depending on their geographical location, whether they already have a probe, etc.) and, in most cases, the order is passed automatically through an API to the third-party service for packaging and shipping. All of this results in much lower costs than when we were paying to individually ship each and every probe.
Second, we focused on reducing the number of probes that have been shipped to hosts but not activated. This is a lot trickier than it sounds, because in many cases, probes have a very interesting life cycle. As an example, a probe might be sitting with an ambassador waiting to be delivered to a host, or with a host who has connected it but for some reason disconnected it after a short period of time. We have worked hard to add more tracking points to this life cycle and we have been able to both reduce the number of so-called “lost probes” by 12% and increase the rate of connected probes to 68% (of course, there will always be a percentage of probes that are disconnected at any given time, due to the probe hosts' own Internet connections). These are very important goals for us, and we will continue to work hard to improve the efficiency of the process as much as possible while keeping it feasible and manageable. 
And last but not least, we decided to not spend any membership money to purchase probes from 2015 onwards. As a matter of fact, we have already purchased enough probes to reach 10,000 active probes in 2015, and they were purchased solely using sponsor funding. This is an important step towards involving the larger community in developing this great project, which was started solely with the financial support of RIPE NCC members.
But that’s not all. Right now, RIPE Atlas covers 5.6% of ASNs announcing IPv4 address space and 9.7% of ASNs announcing IPv6 space. As we reach 10,000 active probes, we will strive to cover 10% of announcing ASNs around the globe, which we believe will be enough coverage to give a good representation of the whole Internet.
New features and functionality
Looking at the development of the network from a different angle, we also implemented a new look and feel for RIPE Atlas during the past few months, which makes its interfaces much simpler to use than before. We also worked on many other features and additions, which you can read about on RIPE Labs .
Throughout 2015, we will continue to work on many important requested features, including some form of HTTP measurements, improving the administration and billing features, creating new data visualisations, and adding high-level services to RIPE Atlas.
These high-level services are ones that involve the user instructing the system to complete tasks using a simple interface, but which require a lot of hidden logic taking place under the hood. Obviously, we will keep the current level of customisability in both the web interface and the API, but this simplification will attract many users who want to quickly get some work done without getting into the complex knobs and settings.

We have also started investigating a new version of probe hardware, so when the current supply of probes have been deployed (i.e. we have more than 10,000 active probes online), we can switch to a new generation of RIPE Atlas probes. This will enable us to offer more features and stay up to date with new technologies like new WiFi standards. (We will be discussing proposed WiFi measurements functionality with the community in the coming weeks).
We believe that, by the end of 2015, we will be able to deliver most of the main features we have planned for RIPE Atlas, which means that in 2016 and 2017 we will devote less development time to RIPE Atlas, as the project should be able to stand on its own as a reliable operational service.
RIPE Atlas feedback
Please stay tuned for new features and updates, and give us your feedback via the following channels:
- For specific questions about RIPE Atlas, including RIPE Atlas anchors, please use the RIPE Atlas mailing list for active RIPE Atlas hosts and interested users, which is also followed and answered by RIPE Atlas developers: ripe-atlas [at] ripe [dot] net
- For more general discussions about measurements and future plans, please use the Measurements Analysis and Tools Working Group Mailing List: mat-wg [at] ripe [dot] net
- Join the discussion on Twitter: @RIPE_Atlas
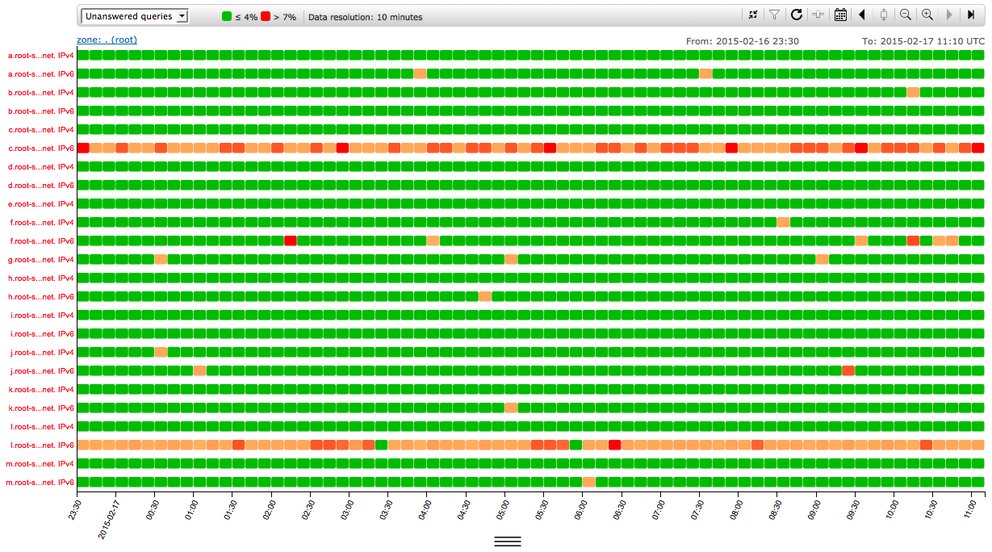
K-root
Being one of the organisations that run one of the 13 DNS root name servers around the globe is interesting – but also comes with a lot of responsibility! We are proud to run a transparent, resilient and global root server operation over a big anycast network.
We currently operate five full resilient nodes with multiple peering sessions in Amsterdam, London, Tokyo, Miami and Frankfurt, and we will continue to operate them as the core of our K-root set-up. It’s good to point out that three out of these five core nodes should be able to handle the average peak traffic we receive, so the system is quite robust. In addition to these five nodes, we have 12 other locations where we host smaller clusters. The scope of these machines is more limited and they normally serve a smaller geographical region.
Expanding K-root
For quite some time now, a number of organisations have asked us about the possibility of hosting a K-root node and whether we would consider expanding the K-root cluster , as there are multiple technical and geopolitical reasons for Internet community members to want to host a root server node themselves. With that in mind, we worked throughout 2014 to revamp our system design to make it easier for this to happen. The new system also means that we can expand K-root with very few additional resources required from our side.
In the expansion model we are considering, the five core nodes will remain intact along with the goal of being able to handle average peak traffic with just three out of these five nodes, but we want to be able to expand the number of smaller, hosted nodes. The concept is very simple: the host will purchase a single machine with minimal requirements and specifications (set by the RIPE NCC) and will set up BGP peering and out-of-band access on the machine, with the RIPE NCC handling the rest. After the initial set-up, everything will be automated – the operation will be basically invisible to the end user and will require minimal engineering effort from our side. As long as the node is up and running and meets all of our required criteria, it will continue operating. However, the RIPE NCC will reserve the right to take the node off the K-root cluster (in most cases automatically) if there are issues, and keep it off the network until we can confirm that all the issues have been fixed and the hosting criteria are met again. The good news is, with RIPE Atlas, we have a very powerful tool at our fingertips to monitor this global anycast network.

Of course, the next question is who will be eligible to host a K-root instance. There are a few basic technical criteria, which will be announced in a few weeks, but beyond meeting these criteria, the more detailed answer is that it will depend on the availability of the existing root services in the potential host’s geographic area. This is because we’re interested in improving latency and want to place instances in those locations that can provide some benefit to the network. We have a lot of requests to host a K-root instance, and already have a waiting list with more than 20 candidates. In order to serve the best interests of the global Internet community as well as the RIPE community, we have set up measurements to investigate which areas can benefit the most from the addition of a K-root instance, both in access times and latency to any root server instance versus a K-root instance, as well as improving the resiliency of those regions by means of other root server operators. Based on this data, we will propose an expansion plan to serve regions that can most benefit from hosting a K-root instance, while giving priority to areas in the RIPE NCC service region. Keep reading RIPE Labs for future updates on these plans.
We will publish a more detailed article about the expansion planning in the near future, so please keep an eye on RIPE Labs and the DNS Working Group Mailing List for further information.
DNS
We are the authoritative zone operator for reverse DNS mapping of addresses in the RIPE NCC service region. At the moment, in-addr.arpa queries are served from three different locations in our service region (Amsterdam, London and Stockholm) with a central provisioning system. In 2015, we will add a second provisioning system to improve the reliability and stability of our authoritative DNS provisioning system.
Secondary DNS for ccTLD operators
Historically, we have provided secondary DNS service for a number of ccTLDs. At the moment, we provide these services for 77 ccTLDs, mostly within the RIPE NCC service region. Last August we sent a proposal to the RIPE DNS Working Group to make the process more streamlined and to give the RIPE NCC clear guidelines on how to evaluate and proceed with new requests we receive. The RIPE DNS Working Group set up a task force and came up with a clear set of criteria , and we are now waiting for them to give us the final go ahead so we can publish them for the community. In the meantime, we refer to the proposed guidelines if we receive such requests. It is worth mentioning that in 2014, we received one ccTLD request (from .ir) to be added to our secondary hosting services. We clarified the process for them and have added them to our ccTLD secondary hosting system (soon to be reflected on the authoritative servers).
DNS Monitoring Service (DNSMON)
In 2014, we revamped DNSMON from scratch. Instead of using TTM data, we switched the system to use data collected by RIPE Atlas anchors and re-implemented the DNSMON user interface completely. The new service is interactive and very useful for both operators and users interested in investigating the stability and reachability of root zone operators, as well as some ccTLD operators that we monitor. Since there are no clear guidelines on how to join DNSMON as a monitored operator, we asked the RIPE DNS Working Group for feedback on a proposal we put together that including guidelines and a process for inclusion. In the meantime, we are following what was suggested and discussed on the DNS Working Group Mailing List .
It’s worth mentioning that, unlike the original implementation, the new DNSMON doesn’t delay the actual visualisation of the data. This delay existed as a security measure in the old system, but we felt that, given advancements in Internet measurement tools and technology that make it relatively easy for someone with bad intentions to monitor the effectiveness of their attack on an operator, adding such a delay to DNSMON doesn’t add any real security value. The discussion started in June 2014 on the DNS Working Group Mailing List has not yet concluded, and in the meantime, we have been operating the new DNSMON without any data delay. We will follow the working group’s decision as soon as we receive a final summary and advice from them.

The new interface to DNSMON is a very good example of how large amounts of collected data can be made useful. We have received a lot of praise from root operators, ccTLD operators and network operators on the value and usefulness of this tool. I strongly encourage you to explore the new DNSMON – even if you are not a root or ccTLD operator – to see how it works, because we all use DNS services and have a common interest in their stability and reliability. And if you are a ccTLD operator, especially in the RIPE NCC service region, please contact us so we can add you to this unique measurement and visualisation system.
We are also active in different DNS venues, including ICANN’s Root Server System Advisory Committee, the IETF’s Domain Name System Operations Working Group (dnsop), DNS-OARC, and other DNS-related groups to share our operational experience and benefit from others’ experience in running DNS operations. Please let us know if you want more information on these topics – we would be more than happy to share what we know.
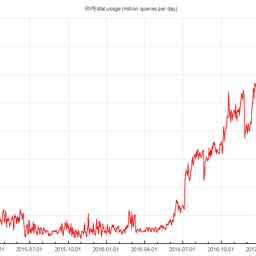
RIPEstat
RIPEstat is a “one-stop shop” for all available information about Internet number resources. In 2014, we worked hard to migrate the huge data back-end of this system from a prototype system to a new production-quality platform, which is more scalable, affordable, efficient and resilient, and is suitable for the big query loads coming from RIPEstat. It was a complex set of tasks, but we accomplished them and now all data calls from RIPEstat go to a single, logical back-end system based on Hadoop infrastructure.
Now that we are done with this phase, we will focus on usability and the ability to follow up use cases and network events in RIPEstat in 2015. We want users to be able to get concrete answers to concrete questions using RIPEstat. With the stable back-end in place, we are working to add new features and visualisations as well as high-level tools and queries in order to streamline network diagnostics and research as much as possible. To achieve this, we will integrate our internal tools like RIPE Atlas and the RIPE Database even more into RIPEstat, as well as introduce additional third-party data sources.
One of the additional data sources we want to fully integrate into RIPEstat is the Routing Information Service (RIS) . In 2014, we worked hard to come up with a new model for the RIS route collectors, in which the machines will stream routing data from all the peers they’re connected to, anywhere in the world, to our systems back home so we can present and visualise BGP routing data from multiple points of view in near real time.
This year, we will focus on migrating existing RIS route collectors to this new firmware and adapt our internal systems to be able to work with live routing data streams so we can provide live routing visualisations through RIPEstat and related tools. We will also work on making those live streams accessible publicly and develop high-level tools, like user-defined alarms that can go off when an interesting routing event happens. We believe this will help realise the full value and power of the RIS system and empower network operators to be proactive when it comes to routing issues.
Data storage and scalability is another area we are working on. As one can imagine, with trillions of measurements collected by RIPE Atlas every year and all the different data sources we serve on RIPEstat, we have a huge amount of data to store, analyse and provide. We don’t want the cost of running such a system to creep exponentially high in the coming years (which it will if we don’t control the intake, or the amount of data we provide live), so we are taking multiple measures to tackle that issue.

One of them is fine-tuning the balance between the CPU and storage we use on the back-end machines so we can get as much as possible from commodity-level machines. Another is to compress and streamline the processing of the data we keep, without impacting the functionality of the service.
Yet another measure is to get the most out of the back-end cluster we use while being flexible enough to make some compromises. For example, in our current set-up we have two active clusters so we can switch in case maintenance is required on one. We are moving towards combining these clusters in one, which means we might have to schedule maintenance time for our services. We understand that this is not ideal, but if done properly, it will give us a lot more room for cheaper expansion with minimum visible effect on the services delivered.
Finally, we are looking into possibilities for serving some of the very old data asynchronously, meaning instead of having them on a pre-indexed live storage system, we fetch the data on request, crunch the numbers based on the user’s demand, and provide them with a little bit of delay. We will still keep all the data, but if a researcher wants the original resolution of routing table changes from 10 years ago, we believe it is reasonable to wait a few minutes to extract the data from the system.
We are looking into all of these options to improve the efficiency of our data storage and we will consult with the community on every decision, outlining their possible impact and benefits. So please watch the relevant channels including the MAT Working Group .
Issue management and feature requests
These days, we receive bug reports and features requests from many different channels, ranging from personal discussions during meetings and socials, to Facebook, Twitter, and mailing list posts, to ticketed emails sent directly to one of our support addresses.
In many cases, some really good suggestions and feature requests are never mentioned on the mailing lists, and are therefore never implemented. To address that, we are working to implement an open and transparent system to track feature requests and development, where we could, for example, input feature requests and bug reports on behalf of users and let users track the status of their requests. Integrating that with our internal planning process means users will be able to see the big picture as well as the dependencies of some of the requested features on other tasks in the project.

This automation and communication model, in conjunction with our usual announcements and consultations with the community, will bring additional transparency to the development work that takes place on these technical services, and will help everyone involved – from RIPE NCC developers to our membership to the wider Internet community – to find out whether a specific feature is planned and to get a better sense of the overall direction of development. We will keep you updated through the MAT Working Group Mailing List and RIPE Labs on the progress of this project.
Research
In the past few years, we have been very active in doing research and publishing articles on Internet events and trends, mainly tailored for the network operators community. You can find the full collection on RIPE Labs, but a few examples include:
- Visualising Network Outages with RIPE Atlas
- RIPE NCC Membership - Developments After Reaching the Last /8
- Internet Traffic During World Cup 2014
- How RIPE Atlas helped Wikipedia Users
- BGP Leaks in Indonesia
In addition, we came up with many useful prototypes and ideas that have ended up becoming successful RIPE NCC services. An example is IPv6 RIPEness , in which we award RIPE NCC members between one and five stars based on their level of IPv6 readiness and deployment. Another recent example is the work being done on Open IP Map , which crowdsources geolocation data of network infrastructure, such as the location of routers, which can be greatly valuable for many different tasks, including diagnostics and route visualisations.
In 2015, we are going to streamline our analysis and statistics generation process. We will first focus on supporting our regional activities with recent and accurate statistics and analysis particular to the region, and then extend the process to the wider community as well as academia. In order to accomplish this, we have worked out a plan to discuss and publish a number of analytical and statistical articles on RIPE Labs every month that we can then compile into a comprehensive report at the end of the year. We will work closely with researchers from APNIC to set up that system and produce some of the initial articles.
In many high-level discussions, having network operation statistics correlated with other indicators (which in many cases are not network related), moves the discussions and helps decision makers and operators in shaping their development strategies. An example of these type of datasets is the correlation between the number of ASNs and the GDP in across regions, or the correlation of IPv6 deployment with population and the use of smart handheld devices. This is not the typical kind of data the RIPE NCC provides, but we see a growing need for it. In order to produce the first round of these types of datasets and make sure we can reproduce them with minimum effort, we are teaming up with researchers from APNIC for a few weeks to establish the know-how in house. We will keep you posted about the progress of that project on RIPE Labs.
Feedback
As always, we want to stay engaged with our community and hear what tools and services would be of most value to you. There are lots of ways to get in touch with us, either in person or online:
And of course, we’ll continue to let you know what we’re up to via the following channels:
- RIPE Labs
- RIPE Mailing Lists , specifically:


Comments 2
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Daniel Karrenberg •
Kaveh, Thanks for the interesting report. It pleases me to see these community services evolve since you have taken over responsibility for them. As an API level user of specifically RIPEstat and RIPE Atlas I am generally very happy. I would like to see much more sharing of tools developed by the users. Could the RIPE NCC find some resources to structurally encourage and support such sharing? A detailed question: For the first time in operational history the RIPE NCC has published its own estimates for the query load capacity of K-root. However I do not understand exactly what "average peak traffic" means. Is it average or peak. If it is an average of peak values, can you be more specific on how it is calculated? If this is intentional obfuscation in keeping with decades of tradition, do not feel obliged to answer with details. ;-) Thanks again, Daniel P.S.: Kaveh and I do talk to each other regularly as RIPE NCC staff, but here I am writing as a happy user.
Kaveh Ranjbar •
Hello Daniel, Thanks for the questions, I think a clarification on these subject will serve the community as well. - On the subject of APIs, yes, definitely. As you know, there is a hackathon (https://labs.ripe.net/Members/suzanne_taylor_muzzin/ripe-atlas-hackathon-2015) planned for RIPE Atlas. With the results of that, we will shape the structure for more sharing and promotion of third-parties building tools and visualisations on top of our APIs. On the other hand, we will keep improving existing APIs and are committed to introduce APIs for every new core functionality of the system. I will make sure we systematically work on publicising these efforts. - For the K-root, very soon we will publish solid numbers on query traffic in line with RSSAC-002. Those, plus the generic numbers we publish for K query loads will provide a lot of information on the amount of traffic we receive and queries we process. What I meant when I referred to average peak traffic, was about a typical weekly (or monthly) average when the root system is not under attack. As visible on http://k.root-servers.org/statistics/ROOT/weekly/ that number amounts ~40 to 50k queries per second and at the moment, a single "core" cluster (out of the five we operate) can easily handle a lot more than that. As you are well aware though, the query load itself is not indicative enough as depending on the type and protocol used for the query we might experience different load levels on different parts of the system, including CPU cycles and bandwidth used to serve those queries, hence we feel really in the safe side with 3 working clusters out of 5. All the best, Kaveh.